# Tutorials
> This bundle contains all pages in the Tutorials section.
> Source: https://www.union.ai/docs/v2/union/tutorials/
=== PAGE: https://www.union.ai/docs/v2/union/tutorials ===
# Tutorials
> **📝 Note**
>
> An LLM-optimized bundle of this entire section is available at [`section.md`](section.md).
> This single file contains all pages in this section, optimized for AI coding agent context.
This section contains tutorials that showcase relevant use cases and provide step-by-step instructions on how to implement various features using Flyte and Union. Tutorials are organized by **industry vertical** and by **technical topic**.
## Industry verticals
### **Biotech & healthcare**
Bioinformatics, medical imaging, and other life-sciences workloads.
### **Geospatial**
Satellite imagery, remote sensing, and earth and atmospheric modeling workloads.
### **Financial services & fintech**
Financial research, trading, and other fintech workloads.
### **Frontier AI**
Frontier-model pretraining, automated experimentation, and large-scale AI workloads.
## Technical topics
### **Computer vision**
Image and vision-language model workloads.
### **Agents**
Agentic workflows and autonomous LLM-powered systems.
### **Context engineering**
Prompt engineering, prompt optimization, and context construction.
### **Model training**
Training, fine-tuning, and hyperparameter optimization of models at scale.
### **Data processing**
Large-scale data processing and batching strategies.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/biotech-healthcare ===
# Biotech & healthcare
Tutorials for bioinformatics, medical imaging, and other life-sciences workloads.
### **Biotech & healthcare > Genomic alignment**
Align sequencing reads to a reference genome with a cached, parallel Bowtie 2 pipeline.
### **Biotech & healthcare > Cross-species gene comparison**
Compare homologous genes across species with Carbon scoring, sequence alignment, and ESMFold 3D structures.
### **Biotech & healthcare > Genomic variant effect prediction**
Zero-shot pathogenicity scoring with HuggingFace Carbon and interactive VEP reports.
### **Biotech & healthcare > Brain tumor MRI classification**
Classify brain MRI scans with a two-phase EfficientNet-B4 pipeline featuring resumable GPU checkpointing and in-UI reports.
### **Biotech & healthcare > Drug molecule screening agent**
Agentic virtual screening with RDKit stage tools, Lipinski filters, and ranked drug-likeness reports.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/biotech-healthcare/genomic-alignment ===
# Genomic alignment
> [!NOTE]
> Code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/genomic_alignment).
This tutorial builds a bioinformatics pipeline that aligns raw sequencing reads to a reference genome. The workflow downloads a reference genome and paired-end sequencing data, performs quality filtering, builds a reference index, and aligns the filtered reads with the [Bowtie 2](https://bowtie-bio.sourceforge.net/bowtie2/index.shtml) aligner — running each sample in parallel.
It's a good showcase of how Flyte handles real bioinformatics workloads:
- **Per-task resources** so quality filtering, indexing, and alignment each request exactly the CPU and memory they need.
- **`cache="auto"`** on the download and indexing steps, so re-runs skip work that hasn't changed.
- **Fan-out parallelism** across samples with `asyncio.gather`.
- **System dependencies** (`fastp`, `bowtie2`) installed into the container image with `apt`.
## Define the container image
Because the pipeline shells out to bioinformatics tools, we build a custom image with `flyte.Image.from_uv_script` and install `fastp` (quality filtering) and `bowtie2` (alignment) via `apt`.
```
# # Genomic Alignment
#
# This tutorial demonstrates how to use Flyte to build a workflow that
# performs genomic alignment on sequencing data. The workflow takes as input
# a reference genome and raw sequencing data, performs quality filtering and
# preprocessing on the raw data, generates an index for the reference genome,
# and aligns the filtered data to the reference genome using the Bowtie 2 aligner.
# {{run-on-union}}
# The tutorial is divided into the following sections:
# 1. Define the container image
# 2. Define the data classes
# 3. Define the tasks
# 4. Define the workflow
# /// script
# requires-python = "3.12"
# dependencies = [
# "flyte",
# "requests",
# ]
# main = "alignment_wf"
# params = ""
# ///
import asyncio
import subprocess
import tempfile
from dataclasses import dataclass
from pathlib import Path
from typing import List
import requests
import flyte
from flyte.io import Dir, File
# ## Defining a Container Image
#
# We define a custom container image using `flyte.Image`. Since we need bioinformatics
# tools — `fastp` for quality filtering and `bowtie2` for alignment — we install them
# via apt. This approach replaces the v1 `ImageSpec` with conda channels.
# {{docs-fragment image}}
main_img = (
flyte.Image.from_uv_script(
__file__,
name="alignment-tutorial",
)
.with_apt_packages("fastp", "bowtie2")
)
# {{/docs-fragment image}}
# We define per-task environments with different resource requirements, then a
# top-level `base_env` that declares all of them as dependencies (required because
# `alignment_wf` and `bowtie2_align_samples` call tasks that live in those environments).
# {{docs-fragment envs}}
fetch_env = flyte.TaskEnvironment(
name="alignment-tutorial-fetch",
image=main_img,
cache="auto",
)
fastp_env = flyte.TaskEnvironment(
name="alignment-tutorial-fastp",
image=main_img,
resources=flyte.Resources(memory="2Gi"),
)
index_env = flyte.TaskEnvironment(
name="alignment-tutorial-index",
image=main_img,
resources=flyte.Resources(memory="10Gi"),
cache="auto",
)
align_env = flyte.TaskEnvironment(
name="alignment-tutorial-align",
image=main_img,
resources=flyte.Resources(cpu=2, memory="10Gi"),
)
base_env = flyte.TaskEnvironment(
name="alignment-tutorial",
image=main_img,
depends_on=[fetch_env, fastp_env, index_env, align_env],
)
# {{/docs-fragment envs}}
# ## Defining Data Classes
#
# We define three data classes to represent the reference genome, sequencing reads,
# and alignment results. We'll first define a convenience function to download files,
# which we'll use within the fetch task to materialize assets from their remote locations.
def fetch_file(url: str, local_dir: str) -> Path:
"""
Downloads a file from the specified URL.
Args:
url (str): The URL of the file to download.
local_dir (str): The directory where you would like this file saved.
Returns:
Path: The local path to the file.
Raises:
requests.HTTPError: If an HTTP error occurs while downloading the file.
"""
url_parts = url.split("/")
fname = url_parts[-1]
local_path = Path(local_dir) / fname
response = requests.get(url)
with open(local_path, "wb") as file:
file.write(response.content)
return local_path
# Reference genomes are used extensively throughout bioinformatics workflows. We define a
# `Reference` data class to represent a reference genome and its associated index files.
# {{docs-fragment dataclasses}}
@dataclass
class Reference:
"""
Represents a reference FASTA and associated index files.
Attributes:
ref_name (str): Name or identifier of the reference file.
ref_dir (Dir): Directory containing the reference and any index files.
index_name (str): Index string to pass to tools requiring it.
indexed_with (str): Name of tool used to create the index.
"""
ref_name: str
ref_dir: Dir
index_name: str | None = None
indexed_with: str | None = None
# Sequencing reads are the raw data generated from a sequencing experiment.
@dataclass
class Reads:
"""
Represents a sequencing reads sample via its associated FastQ files.
Attributes:
sample (str): The name or identifier of the raw sequencing sample.
read1 (File): A File object representing the path to the raw R1 read file.
read2 (File): A File object representing the path to the raw R2 read file.
"""
sample: str
read1: File | None = None
read2: File | None = None
def get_read_fnames(self):
return (
f"{self.sample}_1.fastq.gz",
f"{self.sample}_2.fastq.gz",
)
# Finally, we define an `Alignment` data class to represent an alignment file.
@dataclass
class Alignment:
"""
Represents an alignment file and its associated sample.
Attributes:
sample (str): The name or identifier of the sample.
aligner (str): The name of the aligner used to generate the alignment file.
format (str): The format of the alignment file (e.g., SAM, BAM).
alignment (File): A File object representing the path to the alignment file.
"""
sample: str
aligner: str
format: str | None = None
alignment: File | None = None
def get_alignment_fname(self):
return f"{self.sample}_{self.aligner}_aligned.{self.format}"
# {{/docs-fragment dataclasses}}
# ## Tasks
#
# We define a series of tasks to perform the following operations:
# 1. Fetch assets from remote URLs
# 2. Perform quality filtering and preprocessing using FastP
# 3. Generate Bowtie2 index files from a reference genome
# 4. Perform alignment using Bowtie2 on a filtered sample
#
# The first task fetches the reference genome and sequencing reads. It is cached
# so that re-runs skip the download step.
# {{docs-fragment fetch_assets}}
@fetch_env.task
async def fetch_assets(
ref_url: str, read_urls: List[str]
) -> tuple[Reference, List[Reads]]:
"""
Fetch assets from remote URLs.
"""
# Download reference genome
ref_dir = Path("/tmp/reference_genome")
ref_dir.mkdir(exist_ok=True, parents=True)
ref = fetch_file(ref_url, str(ref_dir))
ref_obj = Reference(
ref_name=ref.name,
ref_dir=await Dir.from_local(str(ref_dir)),
)
# Download sequencing reads
dl_loc = Path("/tmp/reads")
dl_loc.mkdir(exist_ok=True, parents=True)
samples: dict[str, Reads] = {}
for url in read_urls:
fp = fetch_file(url, str(dl_loc))
sample = fp.stem.split("_")[0]
if sample not in samples:
samples[sample] = Reads(sample=sample)
if ".fastq.gz" in fp.name or "fasta" in fp.name:
mate = fp.name.strip(".fastq.gz").strip(".filt").split("_")[-1]
if "1" in mate:
samples[sample].read1 = await File.from_local(str(fp))
elif "2" in mate:
samples[sample].read2 = await File.from_local(str(fp))
return ref_obj, list(samples.values())
# {{/docs-fragment fetch_assets}}
# The second task performs quality filtering and preprocessing using FastP on a Reads object.
# FastP is a performant tool for removing duplicate or low-quality reads. We increase
# the memory request for this task so FastP can efficiently process reads from larger files.
# {{docs-fragment pyfastp}}
@fastp_env.task
async def pyfastp(rs: Reads) -> Reads:
"""
Perform quality filtering and preprocessing using Fastp on a Reads object.
Args:
rs (Reads): A Reads object containing raw sequencing data to be processed.
Returns:
Reads: A Reads object representing the filtered and preprocessed data.
"""
ldir = Path(tempfile.mkdtemp())
samp = Reads(rs.sample)
o1, o2 = samp.get_read_fnames()
o1p = ldir / o1
o2p = ldir / o2
assert rs.read1 is not None and rs.read2 is not None
r1 = await rs.read1.download()
r2 = await rs.read2.download()
cmd = [
"fastp",
"-i", str(r1),
"-I", str(r2),
"-o", str(o1p),
"-O", str(o2p),
]
subprocess.run(cmd, check=True)
samp.read1 = await File.from_local(str(o1p))
samp.read2 = await File.from_local(str(o2p))
return samp
# {{/docs-fragment pyfastp}}
# Next, we define a task to generate Bowtie2 index files from a reference genome. As the index
# for a given tool and reference seldom changes, we cache this task.
# {{docs-fragment bowtie2_index}}
@index_env.task
async def bowtie2_index(ref: Reference) -> Reference:
"""
Generate Bowtie2 index files from a reference genome.
Args:
ref (Reference): A Reference object representing the reference genome.
Returns:
Reference: The same reference object with the index_name and indexed_with attributes set.
"""
ref_dir = await ref.ref_dir.download()
idx_name = "bt2_idx"
cmd = [
"bowtie2-build",
str(Path(str(ref_dir)) / ref.ref_name),
str(Path(str(ref_dir)) / idx_name),
]
subprocess.run(cmd, check=True)
return Reference(
ref.ref_name,
await Dir.from_local(str(ref_dir)),
idx_name,
"bowtie2",
)
# {{/docs-fragment bowtie2_index}}
# The next task performs paired-end alignment using Bowtie 2 on a single sample.
# {{docs-fragment bowtie2_align}}
@align_env.task
async def bowtie2_align_paired_reads(idx: Reference, fs: Reads) -> Alignment:
"""
Perform paired-end alignment using Bowtie 2 on a filtered sample.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
fs (Reads): A filtered Reads object containing sample data to be aligned.
Returns:
Alignment: An Alignment object representing the alignment result.
"""
assert idx.indexed_with == "bowtie2", "Reference index must be generated with bowtie2"
assert idx.index_name is not None
assert fs.read1 is not None and fs.read2 is not None
ref_dir = await idx.ref_dir.download()
r1 = await fs.read1.download()
r2 = await fs.read2.download()
ldir = Path(tempfile.mkdtemp())
alignment = Alignment(fs.sample, "bowtie2", "sam")
al = ldir / alignment.get_alignment_fname()
cmd = [
"bowtie2",
"-x", str(Path(str(ref_dir)) / idx.index_name),
"-1", str(r1),
"-2", str(r2),
"-S", str(al),
]
subprocess.run(cmd, check=True)
alignment.alignment = await File.from_local(str(al))
return alignment
# {{/docs-fragment bowtie2_align}}
# In place of the v1 `@dynamic` workflow, we use a plain async task with `asyncio.gather`
# to run alignments for all samples in parallel.
@base_env.task
async def bowtie2_align_samples(
idx: Reference, samples: List[Reads]
) -> List[Alignment]:
"""
Process samples through bowtie2 in parallel.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
samples (List[Reads]): A list of Reads objects to be aligned.
Returns:
List[Alignment]: A list of Alignment objects representing the alignment results.
"""
tasks = [bowtie2_align_paired_reads(idx=idx, fs=sample) for sample in samples]
return list(await asyncio.gather(*tasks))
# ## End-to-End Workflow
#
# We tie everything together in a final task that fetches assets, filters them, generates
# an index, and aligns the samples. In place of the v1 `@workflow`, we use a top-level
# `@base_env.task`. Parallelism across samples is achieved with `asyncio.gather`.
# {{docs-fragment workflow}}
@base_env.task
async def alignment_wf() -> List[Alignment]:
# Prepare raw samples from remote URLs
ref, samples = await fetch_assets(
ref_url="https://github.com/unionai-oss/unionbio/raw/main/tests/assets/references/GRCh38_short.fasta",
read_urls=[
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_1.fastq.gz",
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_2.fastq.gz",
],
)
# Filter all samples in parallel
filtered_samples = list(
await asyncio.gather(*[pyfastp(rs=s) for s in samples])
)
# Generate a bowtie2 index or load it from cache
bowtie2_idx = await bowtie2_index(ref=ref)
# Generate alignments using bowtie2
sams = await bowtie2_align_samples(idx=bowtie2_idx, samples=filtered_samples)
return sams
# {{/docs-fragment workflow}}
# You can now run the workflow using the command in the dropdown at the top of the page!
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(alignment_wf)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/genomic_alignment/genomic_alignment.py*
The Python dependencies are declared at the top of the file using the `uv` script style:
```
# /// script
# requires-python = "3.12"
# dependencies = [
# "flyte",
# "requests",
# ]
# main = "alignment_wf"
# ///
```
## Define the task environments
Each stage runs in its own `TaskEnvironment` with tailored resources. The top-level `base_env` declares the others as `depends_on` so the tasks it calls are available at run time.
```
# # Genomic Alignment
#
# This tutorial demonstrates how to use Flyte to build a workflow that
# performs genomic alignment on sequencing data. The workflow takes as input
# a reference genome and raw sequencing data, performs quality filtering and
# preprocessing on the raw data, generates an index for the reference genome,
# and aligns the filtered data to the reference genome using the Bowtie 2 aligner.
# {{run-on-union}}
# The tutorial is divided into the following sections:
# 1. Define the container image
# 2. Define the data classes
# 3. Define the tasks
# 4. Define the workflow
# /// script
# requires-python = "3.12"
# dependencies = [
# "flyte",
# "requests",
# ]
# main = "alignment_wf"
# params = ""
# ///
import asyncio
import subprocess
import tempfile
from dataclasses import dataclass
from pathlib import Path
from typing import List
import requests
import flyte
from flyte.io import Dir, File
# ## Defining a Container Image
#
# We define a custom container image using `flyte.Image`. Since we need bioinformatics
# tools — `fastp` for quality filtering and `bowtie2` for alignment — we install them
# via apt. This approach replaces the v1 `ImageSpec` with conda channels.
# {{docs-fragment image}}
main_img = (
flyte.Image.from_uv_script(
__file__,
name="alignment-tutorial",
)
.with_apt_packages("fastp", "bowtie2")
)
# {{/docs-fragment image}}
# We define per-task environments with different resource requirements, then a
# top-level `base_env` that declares all of them as dependencies (required because
# `alignment_wf` and `bowtie2_align_samples` call tasks that live in those environments).
# {{docs-fragment envs}}
fetch_env = flyte.TaskEnvironment(
name="alignment-tutorial-fetch",
image=main_img,
cache="auto",
)
fastp_env = flyte.TaskEnvironment(
name="alignment-tutorial-fastp",
image=main_img,
resources=flyte.Resources(memory="2Gi"),
)
index_env = flyte.TaskEnvironment(
name="alignment-tutorial-index",
image=main_img,
resources=flyte.Resources(memory="10Gi"),
cache="auto",
)
align_env = flyte.TaskEnvironment(
name="alignment-tutorial-align",
image=main_img,
resources=flyte.Resources(cpu=2, memory="10Gi"),
)
base_env = flyte.TaskEnvironment(
name="alignment-tutorial",
image=main_img,
depends_on=[fetch_env, fastp_env, index_env, align_env],
)
# {{/docs-fragment envs}}
# ## Defining Data Classes
#
# We define three data classes to represent the reference genome, sequencing reads,
# and alignment results. We'll first define a convenience function to download files,
# which we'll use within the fetch task to materialize assets from their remote locations.
def fetch_file(url: str, local_dir: str) -> Path:
"""
Downloads a file from the specified URL.
Args:
url (str): The URL of the file to download.
local_dir (str): The directory where you would like this file saved.
Returns:
Path: The local path to the file.
Raises:
requests.HTTPError: If an HTTP error occurs while downloading the file.
"""
url_parts = url.split("/")
fname = url_parts[-1]
local_path = Path(local_dir) / fname
response = requests.get(url)
with open(local_path, "wb") as file:
file.write(response.content)
return local_path
# Reference genomes are used extensively throughout bioinformatics workflows. We define a
# `Reference` data class to represent a reference genome and its associated index files.
# {{docs-fragment dataclasses}}
@dataclass
class Reference:
"""
Represents a reference FASTA and associated index files.
Attributes:
ref_name (str): Name or identifier of the reference file.
ref_dir (Dir): Directory containing the reference and any index files.
index_name (str): Index string to pass to tools requiring it.
indexed_with (str): Name of tool used to create the index.
"""
ref_name: str
ref_dir: Dir
index_name: str | None = None
indexed_with: str | None = None
# Sequencing reads are the raw data generated from a sequencing experiment.
@dataclass
class Reads:
"""
Represents a sequencing reads sample via its associated FastQ files.
Attributes:
sample (str): The name or identifier of the raw sequencing sample.
read1 (File): A File object representing the path to the raw R1 read file.
read2 (File): A File object representing the path to the raw R2 read file.
"""
sample: str
read1: File | None = None
read2: File | None = None
def get_read_fnames(self):
return (
f"{self.sample}_1.fastq.gz",
f"{self.sample}_2.fastq.gz",
)
# Finally, we define an `Alignment` data class to represent an alignment file.
@dataclass
class Alignment:
"""
Represents an alignment file and its associated sample.
Attributes:
sample (str): The name or identifier of the sample.
aligner (str): The name of the aligner used to generate the alignment file.
format (str): The format of the alignment file (e.g., SAM, BAM).
alignment (File): A File object representing the path to the alignment file.
"""
sample: str
aligner: str
format: str | None = None
alignment: File | None = None
def get_alignment_fname(self):
return f"{self.sample}_{self.aligner}_aligned.{self.format}"
# {{/docs-fragment dataclasses}}
# ## Tasks
#
# We define a series of tasks to perform the following operations:
# 1. Fetch assets from remote URLs
# 2. Perform quality filtering and preprocessing using FastP
# 3. Generate Bowtie2 index files from a reference genome
# 4. Perform alignment using Bowtie2 on a filtered sample
#
# The first task fetches the reference genome and sequencing reads. It is cached
# so that re-runs skip the download step.
# {{docs-fragment fetch_assets}}
@fetch_env.task
async def fetch_assets(
ref_url: str, read_urls: List[str]
) -> tuple[Reference, List[Reads]]:
"""
Fetch assets from remote URLs.
"""
# Download reference genome
ref_dir = Path("/tmp/reference_genome")
ref_dir.mkdir(exist_ok=True, parents=True)
ref = fetch_file(ref_url, str(ref_dir))
ref_obj = Reference(
ref_name=ref.name,
ref_dir=await Dir.from_local(str(ref_dir)),
)
# Download sequencing reads
dl_loc = Path("/tmp/reads")
dl_loc.mkdir(exist_ok=True, parents=True)
samples: dict[str, Reads] = {}
for url in read_urls:
fp = fetch_file(url, str(dl_loc))
sample = fp.stem.split("_")[0]
if sample not in samples:
samples[sample] = Reads(sample=sample)
if ".fastq.gz" in fp.name or "fasta" in fp.name:
mate = fp.name.strip(".fastq.gz").strip(".filt").split("_")[-1]
if "1" in mate:
samples[sample].read1 = await File.from_local(str(fp))
elif "2" in mate:
samples[sample].read2 = await File.from_local(str(fp))
return ref_obj, list(samples.values())
# {{/docs-fragment fetch_assets}}
# The second task performs quality filtering and preprocessing using FastP on a Reads object.
# FastP is a performant tool for removing duplicate or low-quality reads. We increase
# the memory request for this task so FastP can efficiently process reads from larger files.
# {{docs-fragment pyfastp}}
@fastp_env.task
async def pyfastp(rs: Reads) -> Reads:
"""
Perform quality filtering and preprocessing using Fastp on a Reads object.
Args:
rs (Reads): A Reads object containing raw sequencing data to be processed.
Returns:
Reads: A Reads object representing the filtered and preprocessed data.
"""
ldir = Path(tempfile.mkdtemp())
samp = Reads(rs.sample)
o1, o2 = samp.get_read_fnames()
o1p = ldir / o1
o2p = ldir / o2
assert rs.read1 is not None and rs.read2 is not None
r1 = await rs.read1.download()
r2 = await rs.read2.download()
cmd = [
"fastp",
"-i", str(r1),
"-I", str(r2),
"-o", str(o1p),
"-O", str(o2p),
]
subprocess.run(cmd, check=True)
samp.read1 = await File.from_local(str(o1p))
samp.read2 = await File.from_local(str(o2p))
return samp
# {{/docs-fragment pyfastp}}
# Next, we define a task to generate Bowtie2 index files from a reference genome. As the index
# for a given tool and reference seldom changes, we cache this task.
# {{docs-fragment bowtie2_index}}
@index_env.task
async def bowtie2_index(ref: Reference) -> Reference:
"""
Generate Bowtie2 index files from a reference genome.
Args:
ref (Reference): A Reference object representing the reference genome.
Returns:
Reference: The same reference object with the index_name and indexed_with attributes set.
"""
ref_dir = await ref.ref_dir.download()
idx_name = "bt2_idx"
cmd = [
"bowtie2-build",
str(Path(str(ref_dir)) / ref.ref_name),
str(Path(str(ref_dir)) / idx_name),
]
subprocess.run(cmd, check=True)
return Reference(
ref.ref_name,
await Dir.from_local(str(ref_dir)),
idx_name,
"bowtie2",
)
# {{/docs-fragment bowtie2_index}}
# The next task performs paired-end alignment using Bowtie 2 on a single sample.
# {{docs-fragment bowtie2_align}}
@align_env.task
async def bowtie2_align_paired_reads(idx: Reference, fs: Reads) -> Alignment:
"""
Perform paired-end alignment using Bowtie 2 on a filtered sample.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
fs (Reads): A filtered Reads object containing sample data to be aligned.
Returns:
Alignment: An Alignment object representing the alignment result.
"""
assert idx.indexed_with == "bowtie2", "Reference index must be generated with bowtie2"
assert idx.index_name is not None
assert fs.read1 is not None and fs.read2 is not None
ref_dir = await idx.ref_dir.download()
r1 = await fs.read1.download()
r2 = await fs.read2.download()
ldir = Path(tempfile.mkdtemp())
alignment = Alignment(fs.sample, "bowtie2", "sam")
al = ldir / alignment.get_alignment_fname()
cmd = [
"bowtie2",
"-x", str(Path(str(ref_dir)) / idx.index_name),
"-1", str(r1),
"-2", str(r2),
"-S", str(al),
]
subprocess.run(cmd, check=True)
alignment.alignment = await File.from_local(str(al))
return alignment
# {{/docs-fragment bowtie2_align}}
# In place of the v1 `@dynamic` workflow, we use a plain async task with `asyncio.gather`
# to run alignments for all samples in parallel.
@base_env.task
async def bowtie2_align_samples(
idx: Reference, samples: List[Reads]
) -> List[Alignment]:
"""
Process samples through bowtie2 in parallel.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
samples (List[Reads]): A list of Reads objects to be aligned.
Returns:
List[Alignment]: A list of Alignment objects representing the alignment results.
"""
tasks = [bowtie2_align_paired_reads(idx=idx, fs=sample) for sample in samples]
return list(await asyncio.gather(*tasks))
# ## End-to-End Workflow
#
# We tie everything together in a final task that fetches assets, filters them, generates
# an index, and aligns the samples. In place of the v1 `@workflow`, we use a top-level
# `@base_env.task`. Parallelism across samples is achieved with `asyncio.gather`.
# {{docs-fragment workflow}}
@base_env.task
async def alignment_wf() -> List[Alignment]:
# Prepare raw samples from remote URLs
ref, samples = await fetch_assets(
ref_url="https://github.com/unionai-oss/unionbio/raw/main/tests/assets/references/GRCh38_short.fasta",
read_urls=[
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_1.fastq.gz",
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_2.fastq.gz",
],
)
# Filter all samples in parallel
filtered_samples = list(
await asyncio.gather(*[pyfastp(rs=s) for s in samples])
)
# Generate a bowtie2 index or load it from cache
bowtie2_idx = await bowtie2_index(ref=ref)
# Generate alignments using bowtie2
sams = await bowtie2_align_samples(idx=bowtie2_idx, samples=filtered_samples)
return sams
# {{/docs-fragment workflow}}
# You can now run the workflow using the command in the dropdown at the top of the page!
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(alignment_wf)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/genomic_alignment/genomic_alignment.py*
## Define the data classes
We model the reference genome, sequencing reads, and alignment results as dataclasses. `flyte.io.File` and `flyte.io.Dir` reference offloaded data in blob storage, so large genomic files are passed between tasks by reference rather than copied through the orchestrator.
```
# # Genomic Alignment
#
# This tutorial demonstrates how to use Flyte to build a workflow that
# performs genomic alignment on sequencing data. The workflow takes as input
# a reference genome and raw sequencing data, performs quality filtering and
# preprocessing on the raw data, generates an index for the reference genome,
# and aligns the filtered data to the reference genome using the Bowtie 2 aligner.
# {{run-on-union}}
# The tutorial is divided into the following sections:
# 1. Define the container image
# 2. Define the data classes
# 3. Define the tasks
# 4. Define the workflow
# /// script
# requires-python = "3.12"
# dependencies = [
# "flyte",
# "requests",
# ]
# main = "alignment_wf"
# params = ""
# ///
import asyncio
import subprocess
import tempfile
from dataclasses import dataclass
from pathlib import Path
from typing import List
import requests
import flyte
from flyte.io import Dir, File
# ## Defining a Container Image
#
# We define a custom container image using `flyte.Image`. Since we need bioinformatics
# tools — `fastp` for quality filtering and `bowtie2` for alignment — we install them
# via apt. This approach replaces the v1 `ImageSpec` with conda channels.
# {{docs-fragment image}}
main_img = (
flyte.Image.from_uv_script(
__file__,
name="alignment-tutorial",
)
.with_apt_packages("fastp", "bowtie2")
)
# {{/docs-fragment image}}
# We define per-task environments with different resource requirements, then a
# top-level `base_env` that declares all of them as dependencies (required because
# `alignment_wf` and `bowtie2_align_samples` call tasks that live in those environments).
# {{docs-fragment envs}}
fetch_env = flyte.TaskEnvironment(
name="alignment-tutorial-fetch",
image=main_img,
cache="auto",
)
fastp_env = flyte.TaskEnvironment(
name="alignment-tutorial-fastp",
image=main_img,
resources=flyte.Resources(memory="2Gi"),
)
index_env = flyte.TaskEnvironment(
name="alignment-tutorial-index",
image=main_img,
resources=flyte.Resources(memory="10Gi"),
cache="auto",
)
align_env = flyte.TaskEnvironment(
name="alignment-tutorial-align",
image=main_img,
resources=flyte.Resources(cpu=2, memory="10Gi"),
)
base_env = flyte.TaskEnvironment(
name="alignment-tutorial",
image=main_img,
depends_on=[fetch_env, fastp_env, index_env, align_env],
)
# {{/docs-fragment envs}}
# ## Defining Data Classes
#
# We define three data classes to represent the reference genome, sequencing reads,
# and alignment results. We'll first define a convenience function to download files,
# which we'll use within the fetch task to materialize assets from their remote locations.
def fetch_file(url: str, local_dir: str) -> Path:
"""
Downloads a file from the specified URL.
Args:
url (str): The URL of the file to download.
local_dir (str): The directory where you would like this file saved.
Returns:
Path: The local path to the file.
Raises:
requests.HTTPError: If an HTTP error occurs while downloading the file.
"""
url_parts = url.split("/")
fname = url_parts[-1]
local_path = Path(local_dir) / fname
response = requests.get(url)
with open(local_path, "wb") as file:
file.write(response.content)
return local_path
# Reference genomes are used extensively throughout bioinformatics workflows. We define a
# `Reference` data class to represent a reference genome and its associated index files.
# {{docs-fragment dataclasses}}
@dataclass
class Reference:
"""
Represents a reference FASTA and associated index files.
Attributes:
ref_name (str): Name or identifier of the reference file.
ref_dir (Dir): Directory containing the reference and any index files.
index_name (str): Index string to pass to tools requiring it.
indexed_with (str): Name of tool used to create the index.
"""
ref_name: str
ref_dir: Dir
index_name: str | None = None
indexed_with: str | None = None
# Sequencing reads are the raw data generated from a sequencing experiment.
@dataclass
class Reads:
"""
Represents a sequencing reads sample via its associated FastQ files.
Attributes:
sample (str): The name or identifier of the raw sequencing sample.
read1 (File): A File object representing the path to the raw R1 read file.
read2 (File): A File object representing the path to the raw R2 read file.
"""
sample: str
read1: File | None = None
read2: File | None = None
def get_read_fnames(self):
return (
f"{self.sample}_1.fastq.gz",
f"{self.sample}_2.fastq.gz",
)
# Finally, we define an `Alignment` data class to represent an alignment file.
@dataclass
class Alignment:
"""
Represents an alignment file and its associated sample.
Attributes:
sample (str): The name or identifier of the sample.
aligner (str): The name of the aligner used to generate the alignment file.
format (str): The format of the alignment file (e.g., SAM, BAM).
alignment (File): A File object representing the path to the alignment file.
"""
sample: str
aligner: str
format: str | None = None
alignment: File | None = None
def get_alignment_fname(self):
return f"{self.sample}_{self.aligner}_aligned.{self.format}"
# {{/docs-fragment dataclasses}}
# ## Tasks
#
# We define a series of tasks to perform the following operations:
# 1. Fetch assets from remote URLs
# 2. Perform quality filtering and preprocessing using FastP
# 3. Generate Bowtie2 index files from a reference genome
# 4. Perform alignment using Bowtie2 on a filtered sample
#
# The first task fetches the reference genome and sequencing reads. It is cached
# so that re-runs skip the download step.
# {{docs-fragment fetch_assets}}
@fetch_env.task
async def fetch_assets(
ref_url: str, read_urls: List[str]
) -> tuple[Reference, List[Reads]]:
"""
Fetch assets from remote URLs.
"""
# Download reference genome
ref_dir = Path("/tmp/reference_genome")
ref_dir.mkdir(exist_ok=True, parents=True)
ref = fetch_file(ref_url, str(ref_dir))
ref_obj = Reference(
ref_name=ref.name,
ref_dir=await Dir.from_local(str(ref_dir)),
)
# Download sequencing reads
dl_loc = Path("/tmp/reads")
dl_loc.mkdir(exist_ok=True, parents=True)
samples: dict[str, Reads] = {}
for url in read_urls:
fp = fetch_file(url, str(dl_loc))
sample = fp.stem.split("_")[0]
if sample not in samples:
samples[sample] = Reads(sample=sample)
if ".fastq.gz" in fp.name or "fasta" in fp.name:
mate = fp.name.strip(".fastq.gz").strip(".filt").split("_")[-1]
if "1" in mate:
samples[sample].read1 = await File.from_local(str(fp))
elif "2" in mate:
samples[sample].read2 = await File.from_local(str(fp))
return ref_obj, list(samples.values())
# {{/docs-fragment fetch_assets}}
# The second task performs quality filtering and preprocessing using FastP on a Reads object.
# FastP is a performant tool for removing duplicate or low-quality reads. We increase
# the memory request for this task so FastP can efficiently process reads from larger files.
# {{docs-fragment pyfastp}}
@fastp_env.task
async def pyfastp(rs: Reads) -> Reads:
"""
Perform quality filtering and preprocessing using Fastp on a Reads object.
Args:
rs (Reads): A Reads object containing raw sequencing data to be processed.
Returns:
Reads: A Reads object representing the filtered and preprocessed data.
"""
ldir = Path(tempfile.mkdtemp())
samp = Reads(rs.sample)
o1, o2 = samp.get_read_fnames()
o1p = ldir / o1
o2p = ldir / o2
assert rs.read1 is not None and rs.read2 is not None
r1 = await rs.read1.download()
r2 = await rs.read2.download()
cmd = [
"fastp",
"-i", str(r1),
"-I", str(r2),
"-o", str(o1p),
"-O", str(o2p),
]
subprocess.run(cmd, check=True)
samp.read1 = await File.from_local(str(o1p))
samp.read2 = await File.from_local(str(o2p))
return samp
# {{/docs-fragment pyfastp}}
# Next, we define a task to generate Bowtie2 index files from a reference genome. As the index
# for a given tool and reference seldom changes, we cache this task.
# {{docs-fragment bowtie2_index}}
@index_env.task
async def bowtie2_index(ref: Reference) -> Reference:
"""
Generate Bowtie2 index files from a reference genome.
Args:
ref (Reference): A Reference object representing the reference genome.
Returns:
Reference: The same reference object with the index_name and indexed_with attributes set.
"""
ref_dir = await ref.ref_dir.download()
idx_name = "bt2_idx"
cmd = [
"bowtie2-build",
str(Path(str(ref_dir)) / ref.ref_name),
str(Path(str(ref_dir)) / idx_name),
]
subprocess.run(cmd, check=True)
return Reference(
ref.ref_name,
await Dir.from_local(str(ref_dir)),
idx_name,
"bowtie2",
)
# {{/docs-fragment bowtie2_index}}
# The next task performs paired-end alignment using Bowtie 2 on a single sample.
# {{docs-fragment bowtie2_align}}
@align_env.task
async def bowtie2_align_paired_reads(idx: Reference, fs: Reads) -> Alignment:
"""
Perform paired-end alignment using Bowtie 2 on a filtered sample.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
fs (Reads): A filtered Reads object containing sample data to be aligned.
Returns:
Alignment: An Alignment object representing the alignment result.
"""
assert idx.indexed_with == "bowtie2", "Reference index must be generated with bowtie2"
assert idx.index_name is not None
assert fs.read1 is not None and fs.read2 is not None
ref_dir = await idx.ref_dir.download()
r1 = await fs.read1.download()
r2 = await fs.read2.download()
ldir = Path(tempfile.mkdtemp())
alignment = Alignment(fs.sample, "bowtie2", "sam")
al = ldir / alignment.get_alignment_fname()
cmd = [
"bowtie2",
"-x", str(Path(str(ref_dir)) / idx.index_name),
"-1", str(r1),
"-2", str(r2),
"-S", str(al),
]
subprocess.run(cmd, check=True)
alignment.alignment = await File.from_local(str(al))
return alignment
# {{/docs-fragment bowtie2_align}}
# In place of the v1 `@dynamic` workflow, we use a plain async task with `asyncio.gather`
# to run alignments for all samples in parallel.
@base_env.task
async def bowtie2_align_samples(
idx: Reference, samples: List[Reads]
) -> List[Alignment]:
"""
Process samples through bowtie2 in parallel.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
samples (List[Reads]): A list of Reads objects to be aligned.
Returns:
List[Alignment]: A list of Alignment objects representing the alignment results.
"""
tasks = [bowtie2_align_paired_reads(idx=idx, fs=sample) for sample in samples]
return list(await asyncio.gather(*tasks))
# ## End-to-End Workflow
#
# We tie everything together in a final task that fetches assets, filters them, generates
# an index, and aligns the samples. In place of the v1 `@workflow`, we use a top-level
# `@base_env.task`. Parallelism across samples is achieved with `asyncio.gather`.
# {{docs-fragment workflow}}
@base_env.task
async def alignment_wf() -> List[Alignment]:
# Prepare raw samples from remote URLs
ref, samples = await fetch_assets(
ref_url="https://github.com/unionai-oss/unionbio/raw/main/tests/assets/references/GRCh38_short.fasta",
read_urls=[
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_1.fastq.gz",
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_2.fastq.gz",
],
)
# Filter all samples in parallel
filtered_samples = list(
await asyncio.gather(*[pyfastp(rs=s) for s in samples])
)
# Generate a bowtie2 index or load it from cache
bowtie2_idx = await bowtie2_index(ref=ref)
# Generate alignments using bowtie2
sams = await bowtie2_align_samples(idx=bowtie2_idx, samples=filtered_samples)
return sams
# {{/docs-fragment workflow}}
# You can now run the workflow using the command in the dropdown at the top of the page!
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(alignment_wf)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/genomic_alignment/genomic_alignment.py*
## Fetch assets
The first task downloads the reference genome and paired-end reads from remote URLs and materializes them as `File`/`Dir` objects. It's cached, so repeat runs skip the download.
```
# # Genomic Alignment
#
# This tutorial demonstrates how to use Flyte to build a workflow that
# performs genomic alignment on sequencing data. The workflow takes as input
# a reference genome and raw sequencing data, performs quality filtering and
# preprocessing on the raw data, generates an index for the reference genome,
# and aligns the filtered data to the reference genome using the Bowtie 2 aligner.
# {{run-on-union}}
# The tutorial is divided into the following sections:
# 1. Define the container image
# 2. Define the data classes
# 3. Define the tasks
# 4. Define the workflow
# /// script
# requires-python = "3.12"
# dependencies = [
# "flyte",
# "requests",
# ]
# main = "alignment_wf"
# params = ""
# ///
import asyncio
import subprocess
import tempfile
from dataclasses import dataclass
from pathlib import Path
from typing import List
import requests
import flyte
from flyte.io import Dir, File
# ## Defining a Container Image
#
# We define a custom container image using `flyte.Image`. Since we need bioinformatics
# tools — `fastp` for quality filtering and `bowtie2` for alignment — we install them
# via apt. This approach replaces the v1 `ImageSpec` with conda channels.
# {{docs-fragment image}}
main_img = (
flyte.Image.from_uv_script(
__file__,
name="alignment-tutorial",
)
.with_apt_packages("fastp", "bowtie2")
)
# {{/docs-fragment image}}
# We define per-task environments with different resource requirements, then a
# top-level `base_env` that declares all of them as dependencies (required because
# `alignment_wf` and `bowtie2_align_samples` call tasks that live in those environments).
# {{docs-fragment envs}}
fetch_env = flyte.TaskEnvironment(
name="alignment-tutorial-fetch",
image=main_img,
cache="auto",
)
fastp_env = flyte.TaskEnvironment(
name="alignment-tutorial-fastp",
image=main_img,
resources=flyte.Resources(memory="2Gi"),
)
index_env = flyte.TaskEnvironment(
name="alignment-tutorial-index",
image=main_img,
resources=flyte.Resources(memory="10Gi"),
cache="auto",
)
align_env = flyte.TaskEnvironment(
name="alignment-tutorial-align",
image=main_img,
resources=flyte.Resources(cpu=2, memory="10Gi"),
)
base_env = flyte.TaskEnvironment(
name="alignment-tutorial",
image=main_img,
depends_on=[fetch_env, fastp_env, index_env, align_env],
)
# {{/docs-fragment envs}}
# ## Defining Data Classes
#
# We define three data classes to represent the reference genome, sequencing reads,
# and alignment results. We'll first define a convenience function to download files,
# which we'll use within the fetch task to materialize assets from their remote locations.
def fetch_file(url: str, local_dir: str) -> Path:
"""
Downloads a file from the specified URL.
Args:
url (str): The URL of the file to download.
local_dir (str): The directory where you would like this file saved.
Returns:
Path: The local path to the file.
Raises:
requests.HTTPError: If an HTTP error occurs while downloading the file.
"""
url_parts = url.split("/")
fname = url_parts[-1]
local_path = Path(local_dir) / fname
response = requests.get(url)
with open(local_path, "wb") as file:
file.write(response.content)
return local_path
# Reference genomes are used extensively throughout bioinformatics workflows. We define a
# `Reference` data class to represent a reference genome and its associated index files.
# {{docs-fragment dataclasses}}
@dataclass
class Reference:
"""
Represents a reference FASTA and associated index files.
Attributes:
ref_name (str): Name or identifier of the reference file.
ref_dir (Dir): Directory containing the reference and any index files.
index_name (str): Index string to pass to tools requiring it.
indexed_with (str): Name of tool used to create the index.
"""
ref_name: str
ref_dir: Dir
index_name: str | None = None
indexed_with: str | None = None
# Sequencing reads are the raw data generated from a sequencing experiment.
@dataclass
class Reads:
"""
Represents a sequencing reads sample via its associated FastQ files.
Attributes:
sample (str): The name or identifier of the raw sequencing sample.
read1 (File): A File object representing the path to the raw R1 read file.
read2 (File): A File object representing the path to the raw R2 read file.
"""
sample: str
read1: File | None = None
read2: File | None = None
def get_read_fnames(self):
return (
f"{self.sample}_1.fastq.gz",
f"{self.sample}_2.fastq.gz",
)
# Finally, we define an `Alignment` data class to represent an alignment file.
@dataclass
class Alignment:
"""
Represents an alignment file and its associated sample.
Attributes:
sample (str): The name or identifier of the sample.
aligner (str): The name of the aligner used to generate the alignment file.
format (str): The format of the alignment file (e.g., SAM, BAM).
alignment (File): A File object representing the path to the alignment file.
"""
sample: str
aligner: str
format: str | None = None
alignment: File | None = None
def get_alignment_fname(self):
return f"{self.sample}_{self.aligner}_aligned.{self.format}"
# {{/docs-fragment dataclasses}}
# ## Tasks
#
# We define a series of tasks to perform the following operations:
# 1. Fetch assets from remote URLs
# 2. Perform quality filtering and preprocessing using FastP
# 3. Generate Bowtie2 index files from a reference genome
# 4. Perform alignment using Bowtie2 on a filtered sample
#
# The first task fetches the reference genome and sequencing reads. It is cached
# so that re-runs skip the download step.
# {{docs-fragment fetch_assets}}
@fetch_env.task
async def fetch_assets(
ref_url: str, read_urls: List[str]
) -> tuple[Reference, List[Reads]]:
"""
Fetch assets from remote URLs.
"""
# Download reference genome
ref_dir = Path("/tmp/reference_genome")
ref_dir.mkdir(exist_ok=True, parents=True)
ref = fetch_file(ref_url, str(ref_dir))
ref_obj = Reference(
ref_name=ref.name,
ref_dir=await Dir.from_local(str(ref_dir)),
)
# Download sequencing reads
dl_loc = Path("/tmp/reads")
dl_loc.mkdir(exist_ok=True, parents=True)
samples: dict[str, Reads] = {}
for url in read_urls:
fp = fetch_file(url, str(dl_loc))
sample = fp.stem.split("_")[0]
if sample not in samples:
samples[sample] = Reads(sample=sample)
if ".fastq.gz" in fp.name or "fasta" in fp.name:
mate = fp.name.strip(".fastq.gz").strip(".filt").split("_")[-1]
if "1" in mate:
samples[sample].read1 = await File.from_local(str(fp))
elif "2" in mate:
samples[sample].read2 = await File.from_local(str(fp))
return ref_obj, list(samples.values())
# {{/docs-fragment fetch_assets}}
# The second task performs quality filtering and preprocessing using FastP on a Reads object.
# FastP is a performant tool for removing duplicate or low-quality reads. We increase
# the memory request for this task so FastP can efficiently process reads from larger files.
# {{docs-fragment pyfastp}}
@fastp_env.task
async def pyfastp(rs: Reads) -> Reads:
"""
Perform quality filtering and preprocessing using Fastp on a Reads object.
Args:
rs (Reads): A Reads object containing raw sequencing data to be processed.
Returns:
Reads: A Reads object representing the filtered and preprocessed data.
"""
ldir = Path(tempfile.mkdtemp())
samp = Reads(rs.sample)
o1, o2 = samp.get_read_fnames()
o1p = ldir / o1
o2p = ldir / o2
assert rs.read1 is not None and rs.read2 is not None
r1 = await rs.read1.download()
r2 = await rs.read2.download()
cmd = [
"fastp",
"-i", str(r1),
"-I", str(r2),
"-o", str(o1p),
"-O", str(o2p),
]
subprocess.run(cmd, check=True)
samp.read1 = await File.from_local(str(o1p))
samp.read2 = await File.from_local(str(o2p))
return samp
# {{/docs-fragment pyfastp}}
# Next, we define a task to generate Bowtie2 index files from a reference genome. As the index
# for a given tool and reference seldom changes, we cache this task.
# {{docs-fragment bowtie2_index}}
@index_env.task
async def bowtie2_index(ref: Reference) -> Reference:
"""
Generate Bowtie2 index files from a reference genome.
Args:
ref (Reference): A Reference object representing the reference genome.
Returns:
Reference: The same reference object with the index_name and indexed_with attributes set.
"""
ref_dir = await ref.ref_dir.download()
idx_name = "bt2_idx"
cmd = [
"bowtie2-build",
str(Path(str(ref_dir)) / ref.ref_name),
str(Path(str(ref_dir)) / idx_name),
]
subprocess.run(cmd, check=True)
return Reference(
ref.ref_name,
await Dir.from_local(str(ref_dir)),
idx_name,
"bowtie2",
)
# {{/docs-fragment bowtie2_index}}
# The next task performs paired-end alignment using Bowtie 2 on a single sample.
# {{docs-fragment bowtie2_align}}
@align_env.task
async def bowtie2_align_paired_reads(idx: Reference, fs: Reads) -> Alignment:
"""
Perform paired-end alignment using Bowtie 2 on a filtered sample.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
fs (Reads): A filtered Reads object containing sample data to be aligned.
Returns:
Alignment: An Alignment object representing the alignment result.
"""
assert idx.indexed_with == "bowtie2", "Reference index must be generated with bowtie2"
assert idx.index_name is not None
assert fs.read1 is not None and fs.read2 is not None
ref_dir = await idx.ref_dir.download()
r1 = await fs.read1.download()
r2 = await fs.read2.download()
ldir = Path(tempfile.mkdtemp())
alignment = Alignment(fs.sample, "bowtie2", "sam")
al = ldir / alignment.get_alignment_fname()
cmd = [
"bowtie2",
"-x", str(Path(str(ref_dir)) / idx.index_name),
"-1", str(r1),
"-2", str(r2),
"-S", str(al),
]
subprocess.run(cmd, check=True)
alignment.alignment = await File.from_local(str(al))
return alignment
# {{/docs-fragment bowtie2_align}}
# In place of the v1 `@dynamic` workflow, we use a plain async task with `asyncio.gather`
# to run alignments for all samples in parallel.
@base_env.task
async def bowtie2_align_samples(
idx: Reference, samples: List[Reads]
) -> List[Alignment]:
"""
Process samples through bowtie2 in parallel.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
samples (List[Reads]): A list of Reads objects to be aligned.
Returns:
List[Alignment]: A list of Alignment objects representing the alignment results.
"""
tasks = [bowtie2_align_paired_reads(idx=idx, fs=sample) for sample in samples]
return list(await asyncio.gather(*tasks))
# ## End-to-End Workflow
#
# We tie everything together in a final task that fetches assets, filters them, generates
# an index, and aligns the samples. In place of the v1 `@workflow`, we use a top-level
# `@base_env.task`. Parallelism across samples is achieved with `asyncio.gather`.
# {{docs-fragment workflow}}
@base_env.task
async def alignment_wf() -> List[Alignment]:
# Prepare raw samples from remote URLs
ref, samples = await fetch_assets(
ref_url="https://github.com/unionai-oss/unionbio/raw/main/tests/assets/references/GRCh38_short.fasta",
read_urls=[
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_1.fastq.gz",
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_2.fastq.gz",
],
)
# Filter all samples in parallel
filtered_samples = list(
await asyncio.gather(*[pyfastp(rs=s) for s in samples])
)
# Generate a bowtie2 index or load it from cache
bowtie2_idx = await bowtie2_index(ref=ref)
# Generate alignments using bowtie2
sams = await bowtie2_align_samples(idx=bowtie2_idx, samples=filtered_samples)
return sams
# {{/docs-fragment workflow}}
# You can now run the workflow using the command in the dropdown at the top of the page!
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(alignment_wf)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/genomic_alignment/genomic_alignment.py*
## Quality filtering with fastp
`pyfastp` removes duplicate and low-quality reads. It requests extra memory so it can process larger read files efficiently.
```
# # Genomic Alignment
#
# This tutorial demonstrates how to use Flyte to build a workflow that
# performs genomic alignment on sequencing data. The workflow takes as input
# a reference genome and raw sequencing data, performs quality filtering and
# preprocessing on the raw data, generates an index for the reference genome,
# and aligns the filtered data to the reference genome using the Bowtie 2 aligner.
# {{run-on-union}}
# The tutorial is divided into the following sections:
# 1. Define the container image
# 2. Define the data classes
# 3. Define the tasks
# 4. Define the workflow
# /// script
# requires-python = "3.12"
# dependencies = [
# "flyte",
# "requests",
# ]
# main = "alignment_wf"
# params = ""
# ///
import asyncio
import subprocess
import tempfile
from dataclasses import dataclass
from pathlib import Path
from typing import List
import requests
import flyte
from flyte.io import Dir, File
# ## Defining a Container Image
#
# We define a custom container image using `flyte.Image`. Since we need bioinformatics
# tools — `fastp` for quality filtering and `bowtie2` for alignment — we install them
# via apt. This approach replaces the v1 `ImageSpec` with conda channels.
# {{docs-fragment image}}
main_img = (
flyte.Image.from_uv_script(
__file__,
name="alignment-tutorial",
)
.with_apt_packages("fastp", "bowtie2")
)
# {{/docs-fragment image}}
# We define per-task environments with different resource requirements, then a
# top-level `base_env` that declares all of them as dependencies (required because
# `alignment_wf` and `bowtie2_align_samples` call tasks that live in those environments).
# {{docs-fragment envs}}
fetch_env = flyte.TaskEnvironment(
name="alignment-tutorial-fetch",
image=main_img,
cache="auto",
)
fastp_env = flyte.TaskEnvironment(
name="alignment-tutorial-fastp",
image=main_img,
resources=flyte.Resources(memory="2Gi"),
)
index_env = flyte.TaskEnvironment(
name="alignment-tutorial-index",
image=main_img,
resources=flyte.Resources(memory="10Gi"),
cache="auto",
)
align_env = flyte.TaskEnvironment(
name="alignment-tutorial-align",
image=main_img,
resources=flyte.Resources(cpu=2, memory="10Gi"),
)
base_env = flyte.TaskEnvironment(
name="alignment-tutorial",
image=main_img,
depends_on=[fetch_env, fastp_env, index_env, align_env],
)
# {{/docs-fragment envs}}
# ## Defining Data Classes
#
# We define three data classes to represent the reference genome, sequencing reads,
# and alignment results. We'll first define a convenience function to download files,
# which we'll use within the fetch task to materialize assets from their remote locations.
def fetch_file(url: str, local_dir: str) -> Path:
"""
Downloads a file from the specified URL.
Args:
url (str): The URL of the file to download.
local_dir (str): The directory where you would like this file saved.
Returns:
Path: The local path to the file.
Raises:
requests.HTTPError: If an HTTP error occurs while downloading the file.
"""
url_parts = url.split("/")
fname = url_parts[-1]
local_path = Path(local_dir) / fname
response = requests.get(url)
with open(local_path, "wb") as file:
file.write(response.content)
return local_path
# Reference genomes are used extensively throughout bioinformatics workflows. We define a
# `Reference` data class to represent a reference genome and its associated index files.
# {{docs-fragment dataclasses}}
@dataclass
class Reference:
"""
Represents a reference FASTA and associated index files.
Attributes:
ref_name (str): Name or identifier of the reference file.
ref_dir (Dir): Directory containing the reference and any index files.
index_name (str): Index string to pass to tools requiring it.
indexed_with (str): Name of tool used to create the index.
"""
ref_name: str
ref_dir: Dir
index_name: str | None = None
indexed_with: str | None = None
# Sequencing reads are the raw data generated from a sequencing experiment.
@dataclass
class Reads:
"""
Represents a sequencing reads sample via its associated FastQ files.
Attributes:
sample (str): The name or identifier of the raw sequencing sample.
read1 (File): A File object representing the path to the raw R1 read file.
read2 (File): A File object representing the path to the raw R2 read file.
"""
sample: str
read1: File | None = None
read2: File | None = None
def get_read_fnames(self):
return (
f"{self.sample}_1.fastq.gz",
f"{self.sample}_2.fastq.gz",
)
# Finally, we define an `Alignment` data class to represent an alignment file.
@dataclass
class Alignment:
"""
Represents an alignment file and its associated sample.
Attributes:
sample (str): The name or identifier of the sample.
aligner (str): The name of the aligner used to generate the alignment file.
format (str): The format of the alignment file (e.g., SAM, BAM).
alignment (File): A File object representing the path to the alignment file.
"""
sample: str
aligner: str
format: str | None = None
alignment: File | None = None
def get_alignment_fname(self):
return f"{self.sample}_{self.aligner}_aligned.{self.format}"
# {{/docs-fragment dataclasses}}
# ## Tasks
#
# We define a series of tasks to perform the following operations:
# 1. Fetch assets from remote URLs
# 2. Perform quality filtering and preprocessing using FastP
# 3. Generate Bowtie2 index files from a reference genome
# 4. Perform alignment using Bowtie2 on a filtered sample
#
# The first task fetches the reference genome and sequencing reads. It is cached
# so that re-runs skip the download step.
# {{docs-fragment fetch_assets}}
@fetch_env.task
async def fetch_assets(
ref_url: str, read_urls: List[str]
) -> tuple[Reference, List[Reads]]:
"""
Fetch assets from remote URLs.
"""
# Download reference genome
ref_dir = Path("/tmp/reference_genome")
ref_dir.mkdir(exist_ok=True, parents=True)
ref = fetch_file(ref_url, str(ref_dir))
ref_obj = Reference(
ref_name=ref.name,
ref_dir=await Dir.from_local(str(ref_dir)),
)
# Download sequencing reads
dl_loc = Path("/tmp/reads")
dl_loc.mkdir(exist_ok=True, parents=True)
samples: dict[str, Reads] = {}
for url in read_urls:
fp = fetch_file(url, str(dl_loc))
sample = fp.stem.split("_")[0]
if sample not in samples:
samples[sample] = Reads(sample=sample)
if ".fastq.gz" in fp.name or "fasta" in fp.name:
mate = fp.name.strip(".fastq.gz").strip(".filt").split("_")[-1]
if "1" in mate:
samples[sample].read1 = await File.from_local(str(fp))
elif "2" in mate:
samples[sample].read2 = await File.from_local(str(fp))
return ref_obj, list(samples.values())
# {{/docs-fragment fetch_assets}}
# The second task performs quality filtering and preprocessing using FastP on a Reads object.
# FastP is a performant tool for removing duplicate or low-quality reads. We increase
# the memory request for this task so FastP can efficiently process reads from larger files.
# {{docs-fragment pyfastp}}
@fastp_env.task
async def pyfastp(rs: Reads) -> Reads:
"""
Perform quality filtering and preprocessing using Fastp on a Reads object.
Args:
rs (Reads): A Reads object containing raw sequencing data to be processed.
Returns:
Reads: A Reads object representing the filtered and preprocessed data.
"""
ldir = Path(tempfile.mkdtemp())
samp = Reads(rs.sample)
o1, o2 = samp.get_read_fnames()
o1p = ldir / o1
o2p = ldir / o2
assert rs.read1 is not None and rs.read2 is not None
r1 = await rs.read1.download()
r2 = await rs.read2.download()
cmd = [
"fastp",
"-i", str(r1),
"-I", str(r2),
"-o", str(o1p),
"-O", str(o2p),
]
subprocess.run(cmd, check=True)
samp.read1 = await File.from_local(str(o1p))
samp.read2 = await File.from_local(str(o2p))
return samp
# {{/docs-fragment pyfastp}}
# Next, we define a task to generate Bowtie2 index files from a reference genome. As the index
# for a given tool and reference seldom changes, we cache this task.
# {{docs-fragment bowtie2_index}}
@index_env.task
async def bowtie2_index(ref: Reference) -> Reference:
"""
Generate Bowtie2 index files from a reference genome.
Args:
ref (Reference): A Reference object representing the reference genome.
Returns:
Reference: The same reference object with the index_name and indexed_with attributes set.
"""
ref_dir = await ref.ref_dir.download()
idx_name = "bt2_idx"
cmd = [
"bowtie2-build",
str(Path(str(ref_dir)) / ref.ref_name),
str(Path(str(ref_dir)) / idx_name),
]
subprocess.run(cmd, check=True)
return Reference(
ref.ref_name,
await Dir.from_local(str(ref_dir)),
idx_name,
"bowtie2",
)
# {{/docs-fragment bowtie2_index}}
# The next task performs paired-end alignment using Bowtie 2 on a single sample.
# {{docs-fragment bowtie2_align}}
@align_env.task
async def bowtie2_align_paired_reads(idx: Reference, fs: Reads) -> Alignment:
"""
Perform paired-end alignment using Bowtie 2 on a filtered sample.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
fs (Reads): A filtered Reads object containing sample data to be aligned.
Returns:
Alignment: An Alignment object representing the alignment result.
"""
assert idx.indexed_with == "bowtie2", "Reference index must be generated with bowtie2"
assert idx.index_name is not None
assert fs.read1 is not None and fs.read2 is not None
ref_dir = await idx.ref_dir.download()
r1 = await fs.read1.download()
r2 = await fs.read2.download()
ldir = Path(tempfile.mkdtemp())
alignment = Alignment(fs.sample, "bowtie2", "sam")
al = ldir / alignment.get_alignment_fname()
cmd = [
"bowtie2",
"-x", str(Path(str(ref_dir)) / idx.index_name),
"-1", str(r1),
"-2", str(r2),
"-S", str(al),
]
subprocess.run(cmd, check=True)
alignment.alignment = await File.from_local(str(al))
return alignment
# {{/docs-fragment bowtie2_align}}
# In place of the v1 `@dynamic` workflow, we use a plain async task with `asyncio.gather`
# to run alignments for all samples in parallel.
@base_env.task
async def bowtie2_align_samples(
idx: Reference, samples: List[Reads]
) -> List[Alignment]:
"""
Process samples through bowtie2 in parallel.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
samples (List[Reads]): A list of Reads objects to be aligned.
Returns:
List[Alignment]: A list of Alignment objects representing the alignment results.
"""
tasks = [bowtie2_align_paired_reads(idx=idx, fs=sample) for sample in samples]
return list(await asyncio.gather(*tasks))
# ## End-to-End Workflow
#
# We tie everything together in a final task that fetches assets, filters them, generates
# an index, and aligns the samples. In place of the v1 `@workflow`, we use a top-level
# `@base_env.task`. Parallelism across samples is achieved with `asyncio.gather`.
# {{docs-fragment workflow}}
@base_env.task
async def alignment_wf() -> List[Alignment]:
# Prepare raw samples from remote URLs
ref, samples = await fetch_assets(
ref_url="https://github.com/unionai-oss/unionbio/raw/main/tests/assets/references/GRCh38_short.fasta",
read_urls=[
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_1.fastq.gz",
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_2.fastq.gz",
],
)
# Filter all samples in parallel
filtered_samples = list(
await asyncio.gather(*[pyfastp(rs=s) for s in samples])
)
# Generate a bowtie2 index or load it from cache
bowtie2_idx = await bowtie2_index(ref=ref)
# Generate alignments using bowtie2
sams = await bowtie2_align_samples(idx=bowtie2_idx, samples=filtered_samples)
return sams
# {{/docs-fragment workflow}}
# You can now run the workflow using the command in the dropdown at the top of the page!
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(alignment_wf)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/genomic_alignment/genomic_alignment.py*
## Build the Bowtie 2 index
A reference index rarely changes, so this task is cached.
```
# # Genomic Alignment
#
# This tutorial demonstrates how to use Flyte to build a workflow that
# performs genomic alignment on sequencing data. The workflow takes as input
# a reference genome and raw sequencing data, performs quality filtering and
# preprocessing on the raw data, generates an index for the reference genome,
# and aligns the filtered data to the reference genome using the Bowtie 2 aligner.
# {{run-on-union}}
# The tutorial is divided into the following sections:
# 1. Define the container image
# 2. Define the data classes
# 3. Define the tasks
# 4. Define the workflow
# /// script
# requires-python = "3.12"
# dependencies = [
# "flyte",
# "requests",
# ]
# main = "alignment_wf"
# params = ""
# ///
import asyncio
import subprocess
import tempfile
from dataclasses import dataclass
from pathlib import Path
from typing import List
import requests
import flyte
from flyte.io import Dir, File
# ## Defining a Container Image
#
# We define a custom container image using `flyte.Image`. Since we need bioinformatics
# tools — `fastp` for quality filtering and `bowtie2` for alignment — we install them
# via apt. This approach replaces the v1 `ImageSpec` with conda channels.
# {{docs-fragment image}}
main_img = (
flyte.Image.from_uv_script(
__file__,
name="alignment-tutorial",
)
.with_apt_packages("fastp", "bowtie2")
)
# {{/docs-fragment image}}
# We define per-task environments with different resource requirements, then a
# top-level `base_env` that declares all of them as dependencies (required because
# `alignment_wf` and `bowtie2_align_samples` call tasks that live in those environments).
# {{docs-fragment envs}}
fetch_env = flyte.TaskEnvironment(
name="alignment-tutorial-fetch",
image=main_img,
cache="auto",
)
fastp_env = flyte.TaskEnvironment(
name="alignment-tutorial-fastp",
image=main_img,
resources=flyte.Resources(memory="2Gi"),
)
index_env = flyte.TaskEnvironment(
name="alignment-tutorial-index",
image=main_img,
resources=flyte.Resources(memory="10Gi"),
cache="auto",
)
align_env = flyte.TaskEnvironment(
name="alignment-tutorial-align",
image=main_img,
resources=flyte.Resources(cpu=2, memory="10Gi"),
)
base_env = flyte.TaskEnvironment(
name="alignment-tutorial",
image=main_img,
depends_on=[fetch_env, fastp_env, index_env, align_env],
)
# {{/docs-fragment envs}}
# ## Defining Data Classes
#
# We define three data classes to represent the reference genome, sequencing reads,
# and alignment results. We'll first define a convenience function to download files,
# which we'll use within the fetch task to materialize assets from their remote locations.
def fetch_file(url: str, local_dir: str) -> Path:
"""
Downloads a file from the specified URL.
Args:
url (str): The URL of the file to download.
local_dir (str): The directory where you would like this file saved.
Returns:
Path: The local path to the file.
Raises:
requests.HTTPError: If an HTTP error occurs while downloading the file.
"""
url_parts = url.split("/")
fname = url_parts[-1]
local_path = Path(local_dir) / fname
response = requests.get(url)
with open(local_path, "wb") as file:
file.write(response.content)
return local_path
# Reference genomes are used extensively throughout bioinformatics workflows. We define a
# `Reference` data class to represent a reference genome and its associated index files.
# {{docs-fragment dataclasses}}
@dataclass
class Reference:
"""
Represents a reference FASTA and associated index files.
Attributes:
ref_name (str): Name or identifier of the reference file.
ref_dir (Dir): Directory containing the reference and any index files.
index_name (str): Index string to pass to tools requiring it.
indexed_with (str): Name of tool used to create the index.
"""
ref_name: str
ref_dir: Dir
index_name: str | None = None
indexed_with: str | None = None
# Sequencing reads are the raw data generated from a sequencing experiment.
@dataclass
class Reads:
"""
Represents a sequencing reads sample via its associated FastQ files.
Attributes:
sample (str): The name or identifier of the raw sequencing sample.
read1 (File): A File object representing the path to the raw R1 read file.
read2 (File): A File object representing the path to the raw R2 read file.
"""
sample: str
read1: File | None = None
read2: File | None = None
def get_read_fnames(self):
return (
f"{self.sample}_1.fastq.gz",
f"{self.sample}_2.fastq.gz",
)
# Finally, we define an `Alignment` data class to represent an alignment file.
@dataclass
class Alignment:
"""
Represents an alignment file and its associated sample.
Attributes:
sample (str): The name or identifier of the sample.
aligner (str): The name of the aligner used to generate the alignment file.
format (str): The format of the alignment file (e.g., SAM, BAM).
alignment (File): A File object representing the path to the alignment file.
"""
sample: str
aligner: str
format: str | None = None
alignment: File | None = None
def get_alignment_fname(self):
return f"{self.sample}_{self.aligner}_aligned.{self.format}"
# {{/docs-fragment dataclasses}}
# ## Tasks
#
# We define a series of tasks to perform the following operations:
# 1. Fetch assets from remote URLs
# 2. Perform quality filtering and preprocessing using FastP
# 3. Generate Bowtie2 index files from a reference genome
# 4. Perform alignment using Bowtie2 on a filtered sample
#
# The first task fetches the reference genome and sequencing reads. It is cached
# so that re-runs skip the download step.
# {{docs-fragment fetch_assets}}
@fetch_env.task
async def fetch_assets(
ref_url: str, read_urls: List[str]
) -> tuple[Reference, List[Reads]]:
"""
Fetch assets from remote URLs.
"""
# Download reference genome
ref_dir = Path("/tmp/reference_genome")
ref_dir.mkdir(exist_ok=True, parents=True)
ref = fetch_file(ref_url, str(ref_dir))
ref_obj = Reference(
ref_name=ref.name,
ref_dir=await Dir.from_local(str(ref_dir)),
)
# Download sequencing reads
dl_loc = Path("/tmp/reads")
dl_loc.mkdir(exist_ok=True, parents=True)
samples: dict[str, Reads] = {}
for url in read_urls:
fp = fetch_file(url, str(dl_loc))
sample = fp.stem.split("_")[0]
if sample not in samples:
samples[sample] = Reads(sample=sample)
if ".fastq.gz" in fp.name or "fasta" in fp.name:
mate = fp.name.strip(".fastq.gz").strip(".filt").split("_")[-1]
if "1" in mate:
samples[sample].read1 = await File.from_local(str(fp))
elif "2" in mate:
samples[sample].read2 = await File.from_local(str(fp))
return ref_obj, list(samples.values())
# {{/docs-fragment fetch_assets}}
# The second task performs quality filtering and preprocessing using FastP on a Reads object.
# FastP is a performant tool for removing duplicate or low-quality reads. We increase
# the memory request for this task so FastP can efficiently process reads from larger files.
# {{docs-fragment pyfastp}}
@fastp_env.task
async def pyfastp(rs: Reads) -> Reads:
"""
Perform quality filtering and preprocessing using Fastp on a Reads object.
Args:
rs (Reads): A Reads object containing raw sequencing data to be processed.
Returns:
Reads: A Reads object representing the filtered and preprocessed data.
"""
ldir = Path(tempfile.mkdtemp())
samp = Reads(rs.sample)
o1, o2 = samp.get_read_fnames()
o1p = ldir / o1
o2p = ldir / o2
assert rs.read1 is not None and rs.read2 is not None
r1 = await rs.read1.download()
r2 = await rs.read2.download()
cmd = [
"fastp",
"-i", str(r1),
"-I", str(r2),
"-o", str(o1p),
"-O", str(o2p),
]
subprocess.run(cmd, check=True)
samp.read1 = await File.from_local(str(o1p))
samp.read2 = await File.from_local(str(o2p))
return samp
# {{/docs-fragment pyfastp}}
# Next, we define a task to generate Bowtie2 index files from a reference genome. As the index
# for a given tool and reference seldom changes, we cache this task.
# {{docs-fragment bowtie2_index}}
@index_env.task
async def bowtie2_index(ref: Reference) -> Reference:
"""
Generate Bowtie2 index files from a reference genome.
Args:
ref (Reference): A Reference object representing the reference genome.
Returns:
Reference: The same reference object with the index_name and indexed_with attributes set.
"""
ref_dir = await ref.ref_dir.download()
idx_name = "bt2_idx"
cmd = [
"bowtie2-build",
str(Path(str(ref_dir)) / ref.ref_name),
str(Path(str(ref_dir)) / idx_name),
]
subprocess.run(cmd, check=True)
return Reference(
ref.ref_name,
await Dir.from_local(str(ref_dir)),
idx_name,
"bowtie2",
)
# {{/docs-fragment bowtie2_index}}
# The next task performs paired-end alignment using Bowtie 2 on a single sample.
# {{docs-fragment bowtie2_align}}
@align_env.task
async def bowtie2_align_paired_reads(idx: Reference, fs: Reads) -> Alignment:
"""
Perform paired-end alignment using Bowtie 2 on a filtered sample.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
fs (Reads): A filtered Reads object containing sample data to be aligned.
Returns:
Alignment: An Alignment object representing the alignment result.
"""
assert idx.indexed_with == "bowtie2", "Reference index must be generated with bowtie2"
assert idx.index_name is not None
assert fs.read1 is not None and fs.read2 is not None
ref_dir = await idx.ref_dir.download()
r1 = await fs.read1.download()
r2 = await fs.read2.download()
ldir = Path(tempfile.mkdtemp())
alignment = Alignment(fs.sample, "bowtie2", "sam")
al = ldir / alignment.get_alignment_fname()
cmd = [
"bowtie2",
"-x", str(Path(str(ref_dir)) / idx.index_name),
"-1", str(r1),
"-2", str(r2),
"-S", str(al),
]
subprocess.run(cmd, check=True)
alignment.alignment = await File.from_local(str(al))
return alignment
# {{/docs-fragment bowtie2_align}}
# In place of the v1 `@dynamic` workflow, we use a plain async task with `asyncio.gather`
# to run alignments for all samples in parallel.
@base_env.task
async def bowtie2_align_samples(
idx: Reference, samples: List[Reads]
) -> List[Alignment]:
"""
Process samples through bowtie2 in parallel.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
samples (List[Reads]): A list of Reads objects to be aligned.
Returns:
List[Alignment]: A list of Alignment objects representing the alignment results.
"""
tasks = [bowtie2_align_paired_reads(idx=idx, fs=sample) for sample in samples]
return list(await asyncio.gather(*tasks))
# ## End-to-End Workflow
#
# We tie everything together in a final task that fetches assets, filters them, generates
# an index, and aligns the samples. In place of the v1 `@workflow`, we use a top-level
# `@base_env.task`. Parallelism across samples is achieved with `asyncio.gather`.
# {{docs-fragment workflow}}
@base_env.task
async def alignment_wf() -> List[Alignment]:
# Prepare raw samples from remote URLs
ref, samples = await fetch_assets(
ref_url="https://github.com/unionai-oss/unionbio/raw/main/tests/assets/references/GRCh38_short.fasta",
read_urls=[
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_1.fastq.gz",
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_2.fastq.gz",
],
)
# Filter all samples in parallel
filtered_samples = list(
await asyncio.gather(*[pyfastp(rs=s) for s in samples])
)
# Generate a bowtie2 index or load it from cache
bowtie2_idx = await bowtie2_index(ref=ref)
# Generate alignments using bowtie2
sams = await bowtie2_align_samples(idx=bowtie2_idx, samples=filtered_samples)
return sams
# {{/docs-fragment workflow}}
# You can now run the workflow using the command in the dropdown at the top of the page!
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(alignment_wf)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/genomic_alignment/genomic_alignment.py*
## Align reads
Each sample is aligned to the indexed reference with Bowtie 2, producing a SAM file.
```
# # Genomic Alignment
#
# This tutorial demonstrates how to use Flyte to build a workflow that
# performs genomic alignment on sequencing data. The workflow takes as input
# a reference genome and raw sequencing data, performs quality filtering and
# preprocessing on the raw data, generates an index for the reference genome,
# and aligns the filtered data to the reference genome using the Bowtie 2 aligner.
# {{run-on-union}}
# The tutorial is divided into the following sections:
# 1. Define the container image
# 2. Define the data classes
# 3. Define the tasks
# 4. Define the workflow
# /// script
# requires-python = "3.12"
# dependencies = [
# "flyte",
# "requests",
# ]
# main = "alignment_wf"
# params = ""
# ///
import asyncio
import subprocess
import tempfile
from dataclasses import dataclass
from pathlib import Path
from typing import List
import requests
import flyte
from flyte.io import Dir, File
# ## Defining a Container Image
#
# We define a custom container image using `flyte.Image`. Since we need bioinformatics
# tools — `fastp` for quality filtering and `bowtie2` for alignment — we install them
# via apt. This approach replaces the v1 `ImageSpec` with conda channels.
# {{docs-fragment image}}
main_img = (
flyte.Image.from_uv_script(
__file__,
name="alignment-tutorial",
)
.with_apt_packages("fastp", "bowtie2")
)
# {{/docs-fragment image}}
# We define per-task environments with different resource requirements, then a
# top-level `base_env` that declares all of them as dependencies (required because
# `alignment_wf` and `bowtie2_align_samples` call tasks that live in those environments).
# {{docs-fragment envs}}
fetch_env = flyte.TaskEnvironment(
name="alignment-tutorial-fetch",
image=main_img,
cache="auto",
)
fastp_env = flyte.TaskEnvironment(
name="alignment-tutorial-fastp",
image=main_img,
resources=flyte.Resources(memory="2Gi"),
)
index_env = flyte.TaskEnvironment(
name="alignment-tutorial-index",
image=main_img,
resources=flyte.Resources(memory="10Gi"),
cache="auto",
)
align_env = flyte.TaskEnvironment(
name="alignment-tutorial-align",
image=main_img,
resources=flyte.Resources(cpu=2, memory="10Gi"),
)
base_env = flyte.TaskEnvironment(
name="alignment-tutorial",
image=main_img,
depends_on=[fetch_env, fastp_env, index_env, align_env],
)
# {{/docs-fragment envs}}
# ## Defining Data Classes
#
# We define three data classes to represent the reference genome, sequencing reads,
# and alignment results. We'll first define a convenience function to download files,
# which we'll use within the fetch task to materialize assets from their remote locations.
def fetch_file(url: str, local_dir: str) -> Path:
"""
Downloads a file from the specified URL.
Args:
url (str): The URL of the file to download.
local_dir (str): The directory where you would like this file saved.
Returns:
Path: The local path to the file.
Raises:
requests.HTTPError: If an HTTP error occurs while downloading the file.
"""
url_parts = url.split("/")
fname = url_parts[-1]
local_path = Path(local_dir) / fname
response = requests.get(url)
with open(local_path, "wb") as file:
file.write(response.content)
return local_path
# Reference genomes are used extensively throughout bioinformatics workflows. We define a
# `Reference` data class to represent a reference genome and its associated index files.
# {{docs-fragment dataclasses}}
@dataclass
class Reference:
"""
Represents a reference FASTA and associated index files.
Attributes:
ref_name (str): Name or identifier of the reference file.
ref_dir (Dir): Directory containing the reference and any index files.
index_name (str): Index string to pass to tools requiring it.
indexed_with (str): Name of tool used to create the index.
"""
ref_name: str
ref_dir: Dir
index_name: str | None = None
indexed_with: str | None = None
# Sequencing reads are the raw data generated from a sequencing experiment.
@dataclass
class Reads:
"""
Represents a sequencing reads sample via its associated FastQ files.
Attributes:
sample (str): The name or identifier of the raw sequencing sample.
read1 (File): A File object representing the path to the raw R1 read file.
read2 (File): A File object representing the path to the raw R2 read file.
"""
sample: str
read1: File | None = None
read2: File | None = None
def get_read_fnames(self):
return (
f"{self.sample}_1.fastq.gz",
f"{self.sample}_2.fastq.gz",
)
# Finally, we define an `Alignment` data class to represent an alignment file.
@dataclass
class Alignment:
"""
Represents an alignment file and its associated sample.
Attributes:
sample (str): The name or identifier of the sample.
aligner (str): The name of the aligner used to generate the alignment file.
format (str): The format of the alignment file (e.g., SAM, BAM).
alignment (File): A File object representing the path to the alignment file.
"""
sample: str
aligner: str
format: str | None = None
alignment: File | None = None
def get_alignment_fname(self):
return f"{self.sample}_{self.aligner}_aligned.{self.format}"
# {{/docs-fragment dataclasses}}
# ## Tasks
#
# We define a series of tasks to perform the following operations:
# 1. Fetch assets from remote URLs
# 2. Perform quality filtering and preprocessing using FastP
# 3. Generate Bowtie2 index files from a reference genome
# 4. Perform alignment using Bowtie2 on a filtered sample
#
# The first task fetches the reference genome and sequencing reads. It is cached
# so that re-runs skip the download step.
# {{docs-fragment fetch_assets}}
@fetch_env.task
async def fetch_assets(
ref_url: str, read_urls: List[str]
) -> tuple[Reference, List[Reads]]:
"""
Fetch assets from remote URLs.
"""
# Download reference genome
ref_dir = Path("/tmp/reference_genome")
ref_dir.mkdir(exist_ok=True, parents=True)
ref = fetch_file(ref_url, str(ref_dir))
ref_obj = Reference(
ref_name=ref.name,
ref_dir=await Dir.from_local(str(ref_dir)),
)
# Download sequencing reads
dl_loc = Path("/tmp/reads")
dl_loc.mkdir(exist_ok=True, parents=True)
samples: dict[str, Reads] = {}
for url in read_urls:
fp = fetch_file(url, str(dl_loc))
sample = fp.stem.split("_")[0]
if sample not in samples:
samples[sample] = Reads(sample=sample)
if ".fastq.gz" in fp.name or "fasta" in fp.name:
mate = fp.name.strip(".fastq.gz").strip(".filt").split("_")[-1]
if "1" in mate:
samples[sample].read1 = await File.from_local(str(fp))
elif "2" in mate:
samples[sample].read2 = await File.from_local(str(fp))
return ref_obj, list(samples.values())
# {{/docs-fragment fetch_assets}}
# The second task performs quality filtering and preprocessing using FastP on a Reads object.
# FastP is a performant tool for removing duplicate or low-quality reads. We increase
# the memory request for this task so FastP can efficiently process reads from larger files.
# {{docs-fragment pyfastp}}
@fastp_env.task
async def pyfastp(rs: Reads) -> Reads:
"""
Perform quality filtering and preprocessing using Fastp on a Reads object.
Args:
rs (Reads): A Reads object containing raw sequencing data to be processed.
Returns:
Reads: A Reads object representing the filtered and preprocessed data.
"""
ldir = Path(tempfile.mkdtemp())
samp = Reads(rs.sample)
o1, o2 = samp.get_read_fnames()
o1p = ldir / o1
o2p = ldir / o2
assert rs.read1 is not None and rs.read2 is not None
r1 = await rs.read1.download()
r2 = await rs.read2.download()
cmd = [
"fastp",
"-i", str(r1),
"-I", str(r2),
"-o", str(o1p),
"-O", str(o2p),
]
subprocess.run(cmd, check=True)
samp.read1 = await File.from_local(str(o1p))
samp.read2 = await File.from_local(str(o2p))
return samp
# {{/docs-fragment pyfastp}}
# Next, we define a task to generate Bowtie2 index files from a reference genome. As the index
# for a given tool and reference seldom changes, we cache this task.
# {{docs-fragment bowtie2_index}}
@index_env.task
async def bowtie2_index(ref: Reference) -> Reference:
"""
Generate Bowtie2 index files from a reference genome.
Args:
ref (Reference): A Reference object representing the reference genome.
Returns:
Reference: The same reference object with the index_name and indexed_with attributes set.
"""
ref_dir = await ref.ref_dir.download()
idx_name = "bt2_idx"
cmd = [
"bowtie2-build",
str(Path(str(ref_dir)) / ref.ref_name),
str(Path(str(ref_dir)) / idx_name),
]
subprocess.run(cmd, check=True)
return Reference(
ref.ref_name,
await Dir.from_local(str(ref_dir)),
idx_name,
"bowtie2",
)
# {{/docs-fragment bowtie2_index}}
# The next task performs paired-end alignment using Bowtie 2 on a single sample.
# {{docs-fragment bowtie2_align}}
@align_env.task
async def bowtie2_align_paired_reads(idx: Reference, fs: Reads) -> Alignment:
"""
Perform paired-end alignment using Bowtie 2 on a filtered sample.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
fs (Reads): A filtered Reads object containing sample data to be aligned.
Returns:
Alignment: An Alignment object representing the alignment result.
"""
assert idx.indexed_with == "bowtie2", "Reference index must be generated with bowtie2"
assert idx.index_name is not None
assert fs.read1 is not None and fs.read2 is not None
ref_dir = await idx.ref_dir.download()
r1 = await fs.read1.download()
r2 = await fs.read2.download()
ldir = Path(tempfile.mkdtemp())
alignment = Alignment(fs.sample, "bowtie2", "sam")
al = ldir / alignment.get_alignment_fname()
cmd = [
"bowtie2",
"-x", str(Path(str(ref_dir)) / idx.index_name),
"-1", str(r1),
"-2", str(r2),
"-S", str(al),
]
subprocess.run(cmd, check=True)
alignment.alignment = await File.from_local(str(al))
return alignment
# {{/docs-fragment bowtie2_align}}
# In place of the v1 `@dynamic` workflow, we use a plain async task with `asyncio.gather`
# to run alignments for all samples in parallel.
@base_env.task
async def bowtie2_align_samples(
idx: Reference, samples: List[Reads]
) -> List[Alignment]:
"""
Process samples through bowtie2 in parallel.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
samples (List[Reads]): A list of Reads objects to be aligned.
Returns:
List[Alignment]: A list of Alignment objects representing the alignment results.
"""
tasks = [bowtie2_align_paired_reads(idx=idx, fs=sample) for sample in samples]
return list(await asyncio.gather(*tasks))
# ## End-to-End Workflow
#
# We tie everything together in a final task that fetches assets, filters them, generates
# an index, and aligns the samples. In place of the v1 `@workflow`, we use a top-level
# `@base_env.task`. Parallelism across samples is achieved with `asyncio.gather`.
# {{docs-fragment workflow}}
@base_env.task
async def alignment_wf() -> List[Alignment]:
# Prepare raw samples from remote URLs
ref, samples = await fetch_assets(
ref_url="https://github.com/unionai-oss/unionbio/raw/main/tests/assets/references/GRCh38_short.fasta",
read_urls=[
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_1.fastq.gz",
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_2.fastq.gz",
],
)
# Filter all samples in parallel
filtered_samples = list(
await asyncio.gather(*[pyfastp(rs=s) for s in samples])
)
# Generate a bowtie2 index or load it from cache
bowtie2_idx = await bowtie2_index(ref=ref)
# Generate alignments using bowtie2
sams = await bowtie2_align_samples(idx=bowtie2_idx, samples=filtered_samples)
return sams
# {{/docs-fragment workflow}}
# You can now run the workflow using the command in the dropdown at the top of the page!
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(alignment_wf)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/genomic_alignment/genomic_alignment.py*
## Orchestrate the workflow
The top-level task fetches the assets, filters every sample in parallel, builds the index, and aligns all samples. Parallelism across samples is achieved with `asyncio.gather` rather than a separate `@dynamic` decorator.
```
# # Genomic Alignment
#
# This tutorial demonstrates how to use Flyte to build a workflow that
# performs genomic alignment on sequencing data. The workflow takes as input
# a reference genome and raw sequencing data, performs quality filtering and
# preprocessing on the raw data, generates an index for the reference genome,
# and aligns the filtered data to the reference genome using the Bowtie 2 aligner.
# {{run-on-union}}
# The tutorial is divided into the following sections:
# 1. Define the container image
# 2. Define the data classes
# 3. Define the tasks
# 4. Define the workflow
# /// script
# requires-python = "3.12"
# dependencies = [
# "flyte",
# "requests",
# ]
# main = "alignment_wf"
# params = ""
# ///
import asyncio
import subprocess
import tempfile
from dataclasses import dataclass
from pathlib import Path
from typing import List
import requests
import flyte
from flyte.io import Dir, File
# ## Defining a Container Image
#
# We define a custom container image using `flyte.Image`. Since we need bioinformatics
# tools — `fastp` for quality filtering and `bowtie2` for alignment — we install them
# via apt. This approach replaces the v1 `ImageSpec` with conda channels.
# {{docs-fragment image}}
main_img = (
flyte.Image.from_uv_script(
__file__,
name="alignment-tutorial",
)
.with_apt_packages("fastp", "bowtie2")
)
# {{/docs-fragment image}}
# We define per-task environments with different resource requirements, then a
# top-level `base_env` that declares all of them as dependencies (required because
# `alignment_wf` and `bowtie2_align_samples` call tasks that live in those environments).
# {{docs-fragment envs}}
fetch_env = flyte.TaskEnvironment(
name="alignment-tutorial-fetch",
image=main_img,
cache="auto",
)
fastp_env = flyte.TaskEnvironment(
name="alignment-tutorial-fastp",
image=main_img,
resources=flyte.Resources(memory="2Gi"),
)
index_env = flyte.TaskEnvironment(
name="alignment-tutorial-index",
image=main_img,
resources=flyte.Resources(memory="10Gi"),
cache="auto",
)
align_env = flyte.TaskEnvironment(
name="alignment-tutorial-align",
image=main_img,
resources=flyte.Resources(cpu=2, memory="10Gi"),
)
base_env = flyte.TaskEnvironment(
name="alignment-tutorial",
image=main_img,
depends_on=[fetch_env, fastp_env, index_env, align_env],
)
# {{/docs-fragment envs}}
# ## Defining Data Classes
#
# We define three data classes to represent the reference genome, sequencing reads,
# and alignment results. We'll first define a convenience function to download files,
# which we'll use within the fetch task to materialize assets from their remote locations.
def fetch_file(url: str, local_dir: str) -> Path:
"""
Downloads a file from the specified URL.
Args:
url (str): The URL of the file to download.
local_dir (str): The directory where you would like this file saved.
Returns:
Path: The local path to the file.
Raises:
requests.HTTPError: If an HTTP error occurs while downloading the file.
"""
url_parts = url.split("/")
fname = url_parts[-1]
local_path = Path(local_dir) / fname
response = requests.get(url)
with open(local_path, "wb") as file:
file.write(response.content)
return local_path
# Reference genomes are used extensively throughout bioinformatics workflows. We define a
# `Reference` data class to represent a reference genome and its associated index files.
# {{docs-fragment dataclasses}}
@dataclass
class Reference:
"""
Represents a reference FASTA and associated index files.
Attributes:
ref_name (str): Name or identifier of the reference file.
ref_dir (Dir): Directory containing the reference and any index files.
index_name (str): Index string to pass to tools requiring it.
indexed_with (str): Name of tool used to create the index.
"""
ref_name: str
ref_dir: Dir
index_name: str | None = None
indexed_with: str | None = None
# Sequencing reads are the raw data generated from a sequencing experiment.
@dataclass
class Reads:
"""
Represents a sequencing reads sample via its associated FastQ files.
Attributes:
sample (str): The name or identifier of the raw sequencing sample.
read1 (File): A File object representing the path to the raw R1 read file.
read2 (File): A File object representing the path to the raw R2 read file.
"""
sample: str
read1: File | None = None
read2: File | None = None
def get_read_fnames(self):
return (
f"{self.sample}_1.fastq.gz",
f"{self.sample}_2.fastq.gz",
)
# Finally, we define an `Alignment` data class to represent an alignment file.
@dataclass
class Alignment:
"""
Represents an alignment file and its associated sample.
Attributes:
sample (str): The name or identifier of the sample.
aligner (str): The name of the aligner used to generate the alignment file.
format (str): The format of the alignment file (e.g., SAM, BAM).
alignment (File): A File object representing the path to the alignment file.
"""
sample: str
aligner: str
format: str | None = None
alignment: File | None = None
def get_alignment_fname(self):
return f"{self.sample}_{self.aligner}_aligned.{self.format}"
# {{/docs-fragment dataclasses}}
# ## Tasks
#
# We define a series of tasks to perform the following operations:
# 1. Fetch assets from remote URLs
# 2. Perform quality filtering and preprocessing using FastP
# 3. Generate Bowtie2 index files from a reference genome
# 4. Perform alignment using Bowtie2 on a filtered sample
#
# The first task fetches the reference genome and sequencing reads. It is cached
# so that re-runs skip the download step.
# {{docs-fragment fetch_assets}}
@fetch_env.task
async def fetch_assets(
ref_url: str, read_urls: List[str]
) -> tuple[Reference, List[Reads]]:
"""
Fetch assets from remote URLs.
"""
# Download reference genome
ref_dir = Path("/tmp/reference_genome")
ref_dir.mkdir(exist_ok=True, parents=True)
ref = fetch_file(ref_url, str(ref_dir))
ref_obj = Reference(
ref_name=ref.name,
ref_dir=await Dir.from_local(str(ref_dir)),
)
# Download sequencing reads
dl_loc = Path("/tmp/reads")
dl_loc.mkdir(exist_ok=True, parents=True)
samples: dict[str, Reads] = {}
for url in read_urls:
fp = fetch_file(url, str(dl_loc))
sample = fp.stem.split("_")[0]
if sample not in samples:
samples[sample] = Reads(sample=sample)
if ".fastq.gz" in fp.name or "fasta" in fp.name:
mate = fp.name.strip(".fastq.gz").strip(".filt").split("_")[-1]
if "1" in mate:
samples[sample].read1 = await File.from_local(str(fp))
elif "2" in mate:
samples[sample].read2 = await File.from_local(str(fp))
return ref_obj, list(samples.values())
# {{/docs-fragment fetch_assets}}
# The second task performs quality filtering and preprocessing using FastP on a Reads object.
# FastP is a performant tool for removing duplicate or low-quality reads. We increase
# the memory request for this task so FastP can efficiently process reads from larger files.
# {{docs-fragment pyfastp}}
@fastp_env.task
async def pyfastp(rs: Reads) -> Reads:
"""
Perform quality filtering and preprocessing using Fastp on a Reads object.
Args:
rs (Reads): A Reads object containing raw sequencing data to be processed.
Returns:
Reads: A Reads object representing the filtered and preprocessed data.
"""
ldir = Path(tempfile.mkdtemp())
samp = Reads(rs.sample)
o1, o2 = samp.get_read_fnames()
o1p = ldir / o1
o2p = ldir / o2
assert rs.read1 is not None and rs.read2 is not None
r1 = await rs.read1.download()
r2 = await rs.read2.download()
cmd = [
"fastp",
"-i", str(r1),
"-I", str(r2),
"-o", str(o1p),
"-O", str(o2p),
]
subprocess.run(cmd, check=True)
samp.read1 = await File.from_local(str(o1p))
samp.read2 = await File.from_local(str(o2p))
return samp
# {{/docs-fragment pyfastp}}
# Next, we define a task to generate Bowtie2 index files from a reference genome. As the index
# for a given tool and reference seldom changes, we cache this task.
# {{docs-fragment bowtie2_index}}
@index_env.task
async def bowtie2_index(ref: Reference) -> Reference:
"""
Generate Bowtie2 index files from a reference genome.
Args:
ref (Reference): A Reference object representing the reference genome.
Returns:
Reference: The same reference object with the index_name and indexed_with attributes set.
"""
ref_dir = await ref.ref_dir.download()
idx_name = "bt2_idx"
cmd = [
"bowtie2-build",
str(Path(str(ref_dir)) / ref.ref_name),
str(Path(str(ref_dir)) / idx_name),
]
subprocess.run(cmd, check=True)
return Reference(
ref.ref_name,
await Dir.from_local(str(ref_dir)),
idx_name,
"bowtie2",
)
# {{/docs-fragment bowtie2_index}}
# The next task performs paired-end alignment using Bowtie 2 on a single sample.
# {{docs-fragment bowtie2_align}}
@align_env.task
async def bowtie2_align_paired_reads(idx: Reference, fs: Reads) -> Alignment:
"""
Perform paired-end alignment using Bowtie 2 on a filtered sample.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
fs (Reads): A filtered Reads object containing sample data to be aligned.
Returns:
Alignment: An Alignment object representing the alignment result.
"""
assert idx.indexed_with == "bowtie2", "Reference index must be generated with bowtie2"
assert idx.index_name is not None
assert fs.read1 is not None and fs.read2 is not None
ref_dir = await idx.ref_dir.download()
r1 = await fs.read1.download()
r2 = await fs.read2.download()
ldir = Path(tempfile.mkdtemp())
alignment = Alignment(fs.sample, "bowtie2", "sam")
al = ldir / alignment.get_alignment_fname()
cmd = [
"bowtie2",
"-x", str(Path(str(ref_dir)) / idx.index_name),
"-1", str(r1),
"-2", str(r2),
"-S", str(al),
]
subprocess.run(cmd, check=True)
alignment.alignment = await File.from_local(str(al))
return alignment
# {{/docs-fragment bowtie2_align}}
# In place of the v1 `@dynamic` workflow, we use a plain async task with `asyncio.gather`
# to run alignments for all samples in parallel.
@base_env.task
async def bowtie2_align_samples(
idx: Reference, samples: List[Reads]
) -> List[Alignment]:
"""
Process samples through bowtie2 in parallel.
Args:
idx (Reference): A Reference object containing the Bowtie 2 index.
samples (List[Reads]): A list of Reads objects to be aligned.
Returns:
List[Alignment]: A list of Alignment objects representing the alignment results.
"""
tasks = [bowtie2_align_paired_reads(idx=idx, fs=sample) for sample in samples]
return list(await asyncio.gather(*tasks))
# ## End-to-End Workflow
#
# We tie everything together in a final task that fetches assets, filters them, generates
# an index, and aligns the samples. In place of the v1 `@workflow`, we use a top-level
# `@base_env.task`. Parallelism across samples is achieved with `asyncio.gather`.
# {{docs-fragment workflow}}
@base_env.task
async def alignment_wf() -> List[Alignment]:
# Prepare raw samples from remote URLs
ref, samples = await fetch_assets(
ref_url="https://github.com/unionai-oss/unionbio/raw/main/tests/assets/references/GRCh38_short.fasta",
read_urls=[
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_1.fastq.gz",
"https://github.com/unionai-oss/unionbio/raw/main/tests/assets/sequences/raw/ERR250683-tiny_2.fastq.gz",
],
)
# Filter all samples in parallel
filtered_samples = list(
await asyncio.gather(*[pyfastp(rs=s) for s in samples])
)
# Generate a bowtie2 index or load it from cache
bowtie2_idx = await bowtie2_index(ref=ref)
# Generate alignments using bowtie2
sams = await bowtie2_align_samples(idx=bowtie2_idx, samples=filtered_samples)
return sams
# {{/docs-fragment workflow}}
# You can now run the workflow using the command in the dropdown at the top of the page!
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(alignment_wf)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/genomic_alignment/genomic_alignment.py*
## Run the workflow
This example has no secrets or external API keys — it pulls public test data from GitHub.
From the [example directory](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/genomic_alignment), run it as a `uv` script:
```
cd v2/tutorials/genomic_alignment
uv run --script genomic_alignment.py
```
Or submit it with the Flyte CLI:
```
flyte run genomic_alignment.py alignment_wf
```
When the run completes, each returned `Alignment` points to a SAM file in blob storage that you can download from the run's outputs in the UI.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/biotech-healthcare/tumor-detection ===
# Brain tumor MRI classification
> [!NOTE]
> Code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/tumor_detection).
This tutorial builds a medical-imaging pipeline that classifies brain MRI scans into four categories — Glioma, Meningioma, No Tumor, and Pituitary — using a two-phase EfficientNet-B4 transfer-learning strategy. The pipeline downloads the dataset, trains on a GPU with fault-tolerant checkpointing, and renders training curves and a confusion matrix directly in the Union.ai UI.
The example is split into focused modules:
- `config.py` — container image, task environments, and the `TrainingConfig` hyperparameters.
- `dataset.py` — downloads the Hugging Face dataset, builds class-balanced data loaders.
- `model.py` / `training.py` — the Lightning module and the two-phase training loop.
- `utils.py` — plotting helpers for the report.
- `run.py` — the three Flyte tasks and the pipeline driver.
Flyte handles the production concerns:
- **Per-task resources**: CPU for download/reporting, a GPU for training.
- **`cache="auto"`** on dataset download and training, so reruns with the same data and config are free.
- **`retries=3`** plus **Flyte checkpointing** on the training task so a preempted GPU job resumes from the last epoch.
- **Built-in reports** to visualize metrics without separate dashboard infrastructure.
## Define the container image
A single GPU-ready image is shared by all tasks. `with_source_folder` copies the local modules (`dataset.py`, `model.py`, etc.) into the image.
```
"""
Configuration for brain tumor MRI classification pipeline.
Defines task environments, resource requirements, and training hyperparameters.
"""
import pathlib
import flyte
# {{docs-fragment image}}
image = flyte.Image.from_debian_base(
name="tumor_detection_gpu"
).with_pip_packages(
"torch",
"lightning",
"torchvision",
"timm",
"pillow",
"scikit-learn",
"plotly",
"numpy",
"pandas",
"torchmetrics",
"datasets",
"typing_extensions",
).with_source_folder(
pathlib.Path(__file__).parent,
copy_contents_only=True,
)
# {{/docs-fragment image}}
# {{docs-fragment envs}}
# Downloads raw MRI JPEG files — CPU only, no auth needed, result is cached
dataset_env = flyte.TaskEnvironment(
name="tumor_dataset",
image=image,
resources=flyte.Resources(cpu=2, memory="4Gi", disk="8Gi"),
cache="auto",
)
# GPU training — result is cached so re-running with the same data + config is free
training_env = flyte.TaskEnvironment(
name="tumor_gpu_training",
image=image,
resources=flyte.Resources(
cpu=8,
memory="32Gi",
gpu="T4:1",
disk="100Gi",
),
env_vars={
"CUDA_VISIBLE_DEVICES": "0",
"CUDA_LAUNCH_BLOCKING": "1",
"TORCH_CUDA_MEMORY_FRACTION": "1.0",
"PYTORCH_CUDA_ALLOC_CONF": "expandable_segments:True",
},
cache="auto",
)
# Report generation — CPU only, reads training results and renders Union UI panels
report_env = flyte.TaskEnvironment(
name="tumor_report",
image=image,
resources=flyte.Resources(cpu=2, memory="4Gi"),
)
# Pipeline driver — lightweight orchestrator that calls the three tasks above
pipeline_env = flyte.TaskEnvironment(
name="tumor_pipeline",
image=image,
resources=flyte.Resources(cpu=2, memory="4Gi"),
depends_on=[dataset_env, training_env, report_env],
)
# {{/docs-fragment envs}}
class TrainingConfig:
"""Unified training configuration for brain tumor MRI classification."""
def __init__(
self,
image_size: int = 380,
num_classes: int = 4,
model_name: str = "efficientnet_b4",
pretrained: bool = True,
phase1_epochs: int = 8,
phase1_lr: float = 1e-3,
phase1_freeze_backbone: bool = True,
phase2_epochs: int = 25,
phase2_lr: float = 5e-5,
batch_size: int = 16,
num_workers: int = 0,
val_split: float = 0.2,
weight_decay: float = 1e-4,
warmup_steps: int = 200,
focal_gamma: float = 2.0,
mixup_alpha: float = 0.0,
log_interval: int = 50,
):
self.image_size = image_size
self.num_classes = num_classes
self.model_name = model_name
self.pretrained = pretrained
self.phase1_epochs = phase1_epochs
self.phase1_lr = phase1_lr
self.phase1_freeze_backbone = phase1_freeze_backbone
self.phase2_epochs = phase2_epochs
self.phase2_lr = phase2_lr
self.batch_size = batch_size
self.num_workers = num_workers
self.val_split = val_split
self.weight_decay = weight_decay
self.warmup_steps = warmup_steps
self.focal_gamma = focal_gamma
self.mixup_alpha = mixup_alpha
self.log_interval = log_interval
def to_dict(self) -> dict:
return self.__dict__
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/tumor_detection/config.py*
## Define the task environments
Each stage declares the resources it needs. The lightweight `pipeline_env` orchestrates the others via `depends_on`.
```
"""
Configuration for brain tumor MRI classification pipeline.
Defines task environments, resource requirements, and training hyperparameters.
"""
import pathlib
import flyte
# {{docs-fragment image}}
image = flyte.Image.from_debian_base(
name="tumor_detection_gpu"
).with_pip_packages(
"torch",
"lightning",
"torchvision",
"timm",
"pillow",
"scikit-learn",
"plotly",
"numpy",
"pandas",
"torchmetrics",
"datasets",
"typing_extensions",
).with_source_folder(
pathlib.Path(__file__).parent,
copy_contents_only=True,
)
# {{/docs-fragment image}}
# {{docs-fragment envs}}
# Downloads raw MRI JPEG files — CPU only, no auth needed, result is cached
dataset_env = flyte.TaskEnvironment(
name="tumor_dataset",
image=image,
resources=flyte.Resources(cpu=2, memory="4Gi", disk="8Gi"),
cache="auto",
)
# GPU training — result is cached so re-running with the same data + config is free
training_env = flyte.TaskEnvironment(
name="tumor_gpu_training",
image=image,
resources=flyte.Resources(
cpu=8,
memory="32Gi",
gpu="T4:1",
disk="100Gi",
),
env_vars={
"CUDA_VISIBLE_DEVICES": "0",
"CUDA_LAUNCH_BLOCKING": "1",
"TORCH_CUDA_MEMORY_FRACTION": "1.0",
"PYTORCH_CUDA_ALLOC_CONF": "expandable_segments:True",
},
cache="auto",
)
# Report generation — CPU only, reads training results and renders Union UI panels
report_env = flyte.TaskEnvironment(
name="tumor_report",
image=image,
resources=flyte.Resources(cpu=2, memory="4Gi"),
)
# Pipeline driver — lightweight orchestrator that calls the three tasks above
pipeline_env = flyte.TaskEnvironment(
name="tumor_pipeline",
image=image,
resources=flyte.Resources(cpu=2, memory="4Gi"),
depends_on=[dataset_env, training_env, report_env],
)
# {{/docs-fragment envs}}
class TrainingConfig:
"""Unified training configuration for brain tumor MRI classification."""
def __init__(
self,
image_size: int = 380,
num_classes: int = 4,
model_name: str = "efficientnet_b4",
pretrained: bool = True,
phase1_epochs: int = 8,
phase1_lr: float = 1e-3,
phase1_freeze_backbone: bool = True,
phase2_epochs: int = 25,
phase2_lr: float = 5e-5,
batch_size: int = 16,
num_workers: int = 0,
val_split: float = 0.2,
weight_decay: float = 1e-4,
warmup_steps: int = 200,
focal_gamma: float = 2.0,
mixup_alpha: float = 0.0,
log_interval: int = 50,
):
self.image_size = image_size
self.num_classes = num_classes
self.model_name = model_name
self.pretrained = pretrained
self.phase1_epochs = phase1_epochs
self.phase1_lr = phase1_lr
self.phase1_freeze_backbone = phase1_freeze_backbone
self.phase2_epochs = phase2_epochs
self.phase2_lr = phase2_lr
self.batch_size = batch_size
self.num_workers = num_workers
self.val_split = val_split
self.weight_decay = weight_decay
self.warmup_steps = warmup_steps
self.focal_gamma = focal_gamma
self.mixup_alpha = mixup_alpha
self.log_interval = log_interval
def to_dict(self) -> dict:
return self.__dict__
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/tumor_detection/config.py*
## Configure training
Hyperparameters are gathered in a single `TrainingConfig`, serialized to JSON, and passed into the training task so the exact configuration is captured alongside the run.
```
"""
Flyte/Union pipeline for brain tumor MRI classification.
Three-task pipeline:
1. load_dataset — download Brain Tumor MRI from Hugging Face, cache as Dir (CPU)
2. train_model — two-phase EfficientNet-B4 training with focal loss (GPU)
3. create_report — render training curves and confusion matrix in the Union UI (CPU)
"""
import json
import flyte
from flyte.io import Dir
from config import TrainingConfig, dataset_env, pipeline_env, report_env, training_env
from dataset import download_tumor_dataset
# {{docs-fragment config}}
TRAINING_CONFIG = TrainingConfig(
phase1_epochs=8,
phase2_epochs=25,
phase1_lr=1e-3,
phase2_lr=5e-5,
batch_size=16,
num_workers=0,
log_interval=50,
mixup_alpha=0.0,
image_size=380,
focal_gamma=3.0,
)
# {{/docs-fragment config}}
# {{docs-fragment load_dataset}}
@dataset_env.task
async def load_dataset() -> Dir:
"""
Download raw Brain Tumor MRI JPEG files from Hugging Face and cache as flyte.io.Dir.
Runs once — result is reused on subsequent pipeline runs (cache="auto").
"""
return await download_tumor_dataset()
# {{/docs-fragment load_dataset}}
# {{docs-fragment train_model}}
@training_env.task(retries=3)
async def train_model(dataset_dir: Dir, config_json: str) -> Dir:
"""
Download the raw dataset Dir, run two-phase training,
and return training metrics and final predictions as a Dir for the report task.
"""
from pathlib import Path
local_dir = Path("/tmp/tumor_local")
local_dir.mkdir(parents=True, exist_ok=True)
await dataset_dir.download(local_path=str(local_dir))
from training import train_tumor_classifier
config = TrainingConfig(**json.loads(config_json))
result = train_tumor_classifier(config=config, dataset_path=str(local_dir))
output_dir = Path("/tmp/training_results")
output_dir.mkdir(parents=True, exist_ok=True)
(output_dir / "metrics.json").write_text(json.dumps(result["metrics"]))
(output_dir / "predictions.json").write_text(json.dumps({
"preds": result["final_preds"],
"targets": result["final_targets"],
}))
return await Dir.from_local(str(output_dir))
# {{/docs-fragment train_model}}
# {{docs-fragment create_report}}
@report_env.task(report=True)
async def create_report(results_dir: Dir) -> None:
"""
Download training metrics and render loss/accuracy curves, confusion matrix,
and per-class F1 chart in the Union UI report panel.
"""
import numpy as np
from pathlib import Path
from utils import create_confusion_matrix_plot, create_metrics_plots, create_per_class_f1_plot
local_dir = Path("/tmp/tumor_report")
local_dir.mkdir(parents=True, exist_ok=True)
await results_dir.download(local_path=str(local_dir))
matches = list(local_dir.glob("**/metrics.json"))
if not matches:
raise RuntimeError(f"metrics.json not found under {local_dir}")
local_path = matches[0].parent
history = json.loads((local_path / "metrics.json").read_text())
predictions = json.loads((local_path / "predictions.json").read_text())
preds = np.array(predictions["preds"])
targets = np.array(predictions["targets"])
loss_fig, acc_fig = create_metrics_plots(history)
cm_fig = create_confusion_matrix_plot(preds, targets)
f1_fig = create_per_class_f1_plot(preds, targets)
combined_html = (
acc_fig.to_html(include_plotlyjs=True, full_html=False)
+ loss_fig.to_html(include_plotlyjs=False, full_html=False)
+ cm_fig.to_html(include_plotlyjs=False, full_html=False)
+ f1_fig.to_html(include_plotlyjs=False, full_html=False)
)
flyte.report.log(combined_html, do_flush=True)
# {{/docs-fragment create_report}}
# {{docs-fragment pipeline}}
@pipeline_env.task
async def tumor_detection_pipeline() -> None:
"""Orchestrate dataset loading, GPU training, and report generation."""
dataset_dir = await load_dataset()
results_dir = await train_model(
dataset_dir=dataset_dir,
config_json=json.dumps(TRAINING_CONFIG.to_dict()),
)
await create_report(results_dir=results_dir)
# {{/docs-fragment pipeline}}
if __name__ == "__main__":
import pathlib
flyte.init_from_config(root_dir=pathlib.Path(__file__).parent)
run = flyte.with_runcontext().run(tumor_detection_pipeline)
print(f"\n✓ Pipeline submitted!")
print(f"Run URL: {run.url}")
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/tumor_detection/run.py*
## Load the dataset
The first task downloads the public [Brain Tumor MRI dataset](https://huggingface.co/datasets/AIOmarRehan/Brain_Tumor_MRI_Dataset) from Hugging Face (no auth required) and stores it as a `flyte.io.Dir`. It's cached, so subsequent runs reuse it.
```
"""
Flyte/Union pipeline for brain tumor MRI classification.
Three-task pipeline:
1. load_dataset — download Brain Tumor MRI from Hugging Face, cache as Dir (CPU)
2. train_model — two-phase EfficientNet-B4 training with focal loss (GPU)
3. create_report — render training curves and confusion matrix in the Union UI (CPU)
"""
import json
import flyte
from flyte.io import Dir
from config import TrainingConfig, dataset_env, pipeline_env, report_env, training_env
from dataset import download_tumor_dataset
# {{docs-fragment config}}
TRAINING_CONFIG = TrainingConfig(
phase1_epochs=8,
phase2_epochs=25,
phase1_lr=1e-3,
phase2_lr=5e-5,
batch_size=16,
num_workers=0,
log_interval=50,
mixup_alpha=0.0,
image_size=380,
focal_gamma=3.0,
)
# {{/docs-fragment config}}
# {{docs-fragment load_dataset}}
@dataset_env.task
async def load_dataset() -> Dir:
"""
Download raw Brain Tumor MRI JPEG files from Hugging Face and cache as flyte.io.Dir.
Runs once — result is reused on subsequent pipeline runs (cache="auto").
"""
return await download_tumor_dataset()
# {{/docs-fragment load_dataset}}
# {{docs-fragment train_model}}
@training_env.task(retries=3)
async def train_model(dataset_dir: Dir, config_json: str) -> Dir:
"""
Download the raw dataset Dir, run two-phase training,
and return training metrics and final predictions as a Dir for the report task.
"""
from pathlib import Path
local_dir = Path("/tmp/tumor_local")
local_dir.mkdir(parents=True, exist_ok=True)
await dataset_dir.download(local_path=str(local_dir))
from training import train_tumor_classifier
config = TrainingConfig(**json.loads(config_json))
result = train_tumor_classifier(config=config, dataset_path=str(local_dir))
output_dir = Path("/tmp/training_results")
output_dir.mkdir(parents=True, exist_ok=True)
(output_dir / "metrics.json").write_text(json.dumps(result["metrics"]))
(output_dir / "predictions.json").write_text(json.dumps({
"preds": result["final_preds"],
"targets": result["final_targets"],
}))
return await Dir.from_local(str(output_dir))
# {{/docs-fragment train_model}}
# {{docs-fragment create_report}}
@report_env.task(report=True)
async def create_report(results_dir: Dir) -> None:
"""
Download training metrics and render loss/accuracy curves, confusion matrix,
and per-class F1 chart in the Union UI report panel.
"""
import numpy as np
from pathlib import Path
from utils import create_confusion_matrix_plot, create_metrics_plots, create_per_class_f1_plot
local_dir = Path("/tmp/tumor_report")
local_dir.mkdir(parents=True, exist_ok=True)
await results_dir.download(local_path=str(local_dir))
matches = list(local_dir.glob("**/metrics.json"))
if not matches:
raise RuntimeError(f"metrics.json not found under {local_dir}")
local_path = matches[0].parent
history = json.loads((local_path / "metrics.json").read_text())
predictions = json.loads((local_path / "predictions.json").read_text())
preds = np.array(predictions["preds"])
targets = np.array(predictions["targets"])
loss_fig, acc_fig = create_metrics_plots(history)
cm_fig = create_confusion_matrix_plot(preds, targets)
f1_fig = create_per_class_f1_plot(preds, targets)
combined_html = (
acc_fig.to_html(include_plotlyjs=True, full_html=False)
+ loss_fig.to_html(include_plotlyjs=False, full_html=False)
+ cm_fig.to_html(include_plotlyjs=False, full_html=False)
+ f1_fig.to_html(include_plotlyjs=False, full_html=False)
)
flyte.report.log(combined_html, do_flush=True)
# {{/docs-fragment create_report}}
# {{docs-fragment pipeline}}
@pipeline_env.task
async def tumor_detection_pipeline() -> None:
"""Orchestrate dataset loading, GPU training, and report generation."""
dataset_dir = await load_dataset()
results_dir = await train_model(
dataset_dir=dataset_dir,
config_json=json.dumps(TRAINING_CONFIG.to_dict()),
)
await create_report(results_dir=results_dir)
# {{/docs-fragment pipeline}}
if __name__ == "__main__":
import pathlib
flyte.init_from_config(root_dir=pathlib.Path(__file__).parent)
run = flyte.with_runcontext().run(tumor_detection_pipeline)
print(f"\n✓ Pipeline submitted!")
print(f"Run URL: {run.url}")
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/tumor_detection/run.py*
## Train the model
The training task downloads the dataset `Dir`, runs two-phase training (frozen backbone, then full fine-tuning), and writes metrics and predictions to an output `Dir`. It sets `retries=3` so a preempted GPU node restarts the task.
```
"""
Flyte/Union pipeline for brain tumor MRI classification.
Three-task pipeline:
1. load_dataset — download Brain Tumor MRI from Hugging Face, cache as Dir (CPU)
2. train_model — two-phase EfficientNet-B4 training with focal loss (GPU)
3. create_report — render training curves and confusion matrix in the Union UI (CPU)
"""
import json
import flyte
from flyte.io import Dir
from config import TrainingConfig, dataset_env, pipeline_env, report_env, training_env
from dataset import download_tumor_dataset
# {{docs-fragment config}}
TRAINING_CONFIG = TrainingConfig(
phase1_epochs=8,
phase2_epochs=25,
phase1_lr=1e-3,
phase2_lr=5e-5,
batch_size=16,
num_workers=0,
log_interval=50,
mixup_alpha=0.0,
image_size=380,
focal_gamma=3.0,
)
# {{/docs-fragment config}}
# {{docs-fragment load_dataset}}
@dataset_env.task
async def load_dataset() -> Dir:
"""
Download raw Brain Tumor MRI JPEG files from Hugging Face and cache as flyte.io.Dir.
Runs once — result is reused on subsequent pipeline runs (cache="auto").
"""
return await download_tumor_dataset()
# {{/docs-fragment load_dataset}}
# {{docs-fragment train_model}}
@training_env.task(retries=3)
async def train_model(dataset_dir: Dir, config_json: str) -> Dir:
"""
Download the raw dataset Dir, run two-phase training,
and return training metrics and final predictions as a Dir for the report task.
"""
from pathlib import Path
local_dir = Path("/tmp/tumor_local")
local_dir.mkdir(parents=True, exist_ok=True)
await dataset_dir.download(local_path=str(local_dir))
from training import train_tumor_classifier
config = TrainingConfig(**json.loads(config_json))
result = train_tumor_classifier(config=config, dataset_path=str(local_dir))
output_dir = Path("/tmp/training_results")
output_dir.mkdir(parents=True, exist_ok=True)
(output_dir / "metrics.json").write_text(json.dumps(result["metrics"]))
(output_dir / "predictions.json").write_text(json.dumps({
"preds": result["final_preds"],
"targets": result["final_targets"],
}))
return await Dir.from_local(str(output_dir))
# {{/docs-fragment train_model}}
# {{docs-fragment create_report}}
@report_env.task(report=True)
async def create_report(results_dir: Dir) -> None:
"""
Download training metrics and render loss/accuracy curves, confusion matrix,
and per-class F1 chart in the Union UI report panel.
"""
import numpy as np
from pathlib import Path
from utils import create_confusion_matrix_plot, create_metrics_plots, create_per_class_f1_plot
local_dir = Path("/tmp/tumor_report")
local_dir.mkdir(parents=True, exist_ok=True)
await results_dir.download(local_path=str(local_dir))
matches = list(local_dir.glob("**/metrics.json"))
if not matches:
raise RuntimeError(f"metrics.json not found under {local_dir}")
local_path = matches[0].parent
history = json.loads((local_path / "metrics.json").read_text())
predictions = json.loads((local_path / "predictions.json").read_text())
preds = np.array(predictions["preds"])
targets = np.array(predictions["targets"])
loss_fig, acc_fig = create_metrics_plots(history)
cm_fig = create_confusion_matrix_plot(preds, targets)
f1_fig = create_per_class_f1_plot(preds, targets)
combined_html = (
acc_fig.to_html(include_plotlyjs=True, full_html=False)
+ loss_fig.to_html(include_plotlyjs=False, full_html=False)
+ cm_fig.to_html(include_plotlyjs=False, full_html=False)
+ f1_fig.to_html(include_plotlyjs=False, full_html=False)
)
flyte.report.log(combined_html, do_flush=True)
# {{/docs-fragment create_report}}
# {{docs-fragment pipeline}}
@pipeline_env.task
async def tumor_detection_pipeline() -> None:
"""Orchestrate dataset loading, GPU training, and report generation."""
dataset_dir = await load_dataset()
results_dir = await train_model(
dataset_dir=dataset_dir,
config_json=json.dumps(TRAINING_CONFIG.to_dict()),
)
await create_report(results_dir=results_dir)
# {{/docs-fragment pipeline}}
if __name__ == "__main__":
import pathlib
flyte.init_from_config(root_dir=pathlib.Path(__file__).parent)
run = flyte.with_runcontext().run(tumor_detection_pipeline)
print(f"\n✓ Pipeline submitted!")
print(f"Run URL: {run.url}")
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/tumor_detection/run.py*
### Resumable checkpointing
To make retries cheap, training mirrors its Lightning checkpoint directory to a `flyte.Checkpoint` after every epoch, and resumes from the latest checkpoint when the task restarts.
```
"""
Training pipeline for brain tumor MRI classification.
Implements two-phase training:
- Phase 1: Frozen backbone (feature extractor), train classification head
- Phase 2: Fine-tune full model with differential LRs + cosine annealing
"""
from config import TrainingConfig
from dataset import compute_class_weights, create_data_loaders
from model import TumorClassifierLightningModule
from utils import get_model_size, get_trainable_params
def train_tumor_classifier(
config: TrainingConfig,
dataset_path: str,
) -> dict:
"""
Run two-phase training on the preprocessed dataset and return metrics + final predictions.
dataset_path: local directory where the flyte.io.Dir was downloaded by the training task.
"""
import pathlib
import flyte
import lightning as L
import torch
from lightning.pytorch.callbacks import ModelCheckpoint
from typing_extensions import override
# {{docs-fragment flyte_checkpoint}}
class FlyteLightningCheckpointCallback(ModelCheckpoint):
"""Mirrors the checkpoint directory to Flyte after every epoch so retries can resume."""
def __init__(self, flyte_checkpoint: flyte.Checkpoint, *, dirpath: str, **kwargs):
super().__init__(dirpath=dirpath, **kwargs)
self._flyte_checkpoint = flyte_checkpoint
@override
def on_train_epoch_end(self, trainer: L.Trainer, pl_module: L.LightningModule) -> None:
super().on_train_epoch_end(trainer, pl_module)
if self.dirpath:
self._flyte_checkpoint.save_sync(pathlib.Path(self.dirpath))
# {{/docs-fragment flyte_checkpoint}}
class MetricsLoggerCallback(L.Callback):
def __init__(self, phase1_epochs: int):
super().__init__()
self.phase1_epochs = phase1_epochs
self.history = []
def on_validation_epoch_end(self, trainer, _pl_module):
epoch = trainer.current_epoch
metrics = trainer.callback_metrics
self.history.append({
"epoch": epoch,
"phase": 1 if epoch < self.phase1_epochs else 2,
"train_loss": float(metrics.get("train/loss_epoch", 0)),
"val_loss": float(metrics.get("val/loss", 0)),
"val_acc": float(metrics.get("val/acc", 0)),
"macro_f1": float(metrics.get("val/macro_f1", 0)),
})
class PhaseChangeCallback(L.Callback):
def __init__(self, phase1_epochs: int, phase2_lr: float):
super().__init__()
self.phase1_epochs = phase1_epochs
self.phase2_lr = phase2_lr
self.phase_changed = False
def on_train_epoch_end(self, trainer, pl_module):
if not self.phase_changed and (trainer.current_epoch + 1) == self.phase1_epochs:
print("\n" + "=" * 80)
print("TRANSITIONING TO PHASE 2: UNFREEZING BACKBONE AND ADJUSTING LR")
print("=" * 80 + "\n")
pl_module.model.unfreeze_backbone()
for param_group in trainer.optimizers[0].param_groups:
param_group["lr"] = self.phase2_lr
# Add backbone params to optimizer with 10x lower LR.
# Backbone was excluded at init because it was frozen.
backbone_lr = self.phase2_lr * 0.1
backbone_decay, backbone_no_decay = [], []
for param in pl_module.model.backbone.parameters():
if param.ndim >= 2:
backbone_decay.append(param)
else:
backbone_no_decay.append(param)
optimizer = trainer.optimizers[0]
optimizer.add_param_group({"params": backbone_decay, "lr": backbone_lr, "weight_decay": pl_module.weight_decay})
optimizer.add_param_group({"params": backbone_no_decay, "lr": backbone_lr, "weight_decay": 0.0})
# Fresh cosine schedule over remaining Phase 2 steps to avoid
# the Phase 1 schedule arriving near-zero before Phase 2 begins.
steps_remaining = trainer.estimated_stepping_batches - trainer.global_step
new_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
trainer.optimizers[0],
T_max=max(1, steps_remaining),
eta_min=1e-6,
)
for lr_scheduler_config in trainer.lr_scheduler_configs:
lr_scheduler_config.scheduler = new_scheduler
print(f"Phase 2 started: lr={self.phase2_lr}")
print(f"Total parameters: {get_model_size(pl_module.model):,}")
print(f"Trainable parameters: {get_trainable_params(pl_module.model):,}")
self.phase_changed = True
print("\n" + "=" * 80)
print("BRAIN TUMOR MRI CLASSIFICATION WITH EFFICIENTNET-B4")
print("=" * 80)
print(f"Config: {config.to_dict()}\n")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
if torch.cuda.is_available():
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(f"GPU Memory: {torch.cuda.get_device_properties(0).total_memory / 1e9:.2f} GB")
print("\nLoading MRI images...")
train_loader, val_loader = create_data_loaders(
dataset_path=dataset_path,
image_size=config.image_size,
batch_size=config.batch_size,
num_workers=config.num_workers,
val_split=config.val_split,
)
print(f"Data loaders created: {len(train_loader)} train batches, {len(val_loader)} val batches")
print("\nComputing class weights for focal loss...")
class_weights = compute_class_weights(dataset_path)
print(f"Class weights: {class_weights.tolist()}")
# Per-class gamma: Meningioma gets 7.0, all others 3.0.
# CLASS_NAMES alphabetical order: Glioma=0, Meningioma=1, No Tumor=2, Pituitary=3
gamma_per_class = torch.tensor([3.0, 7.0, 3.0, 3.0])
print("\nInitializing model...")
model = TumorClassifierLightningModule(
num_classes=config.num_classes,
model_name=config.model_name,
pretrained=config.pretrained,
learning_rate=config.phase1_lr,
freeze_backbone=config.phase1_freeze_backbone,
weight_decay=config.weight_decay,
warmup_steps=config.warmup_steps,
max_epochs=config.phase1_epochs + config.phase2_epochs,
focal_gamma=config.focal_gamma,
mixup_alpha=config.mixup_alpha,
class_weights=class_weights,
gamma_per_class=gamma_per_class,
)
print(f"Model: {config.model_name}")
print(f"Total parameters: {get_model_size(model.model):,}")
print(f"Trainable parameters: {get_trainable_params(model.model):,}")
from pathlib import Path
checkpoint_dir = Path("/tmp/tumor_checkpoints")
checkpoint_dir.mkdir(parents=True, exist_ok=True)
# {{docs-fragment resume}}
# --- Flyte checkpoint: resume from previous attempt if one exists ---
resume_ckpt: str | None = None
ctx = flyte.ctx()
flyte_checkpoint = getattr(ctx, "checkpoint", None) if ctx else None
if flyte_checkpoint:
prev_path = flyte_checkpoint.load_sync()
if prev_path:
last = flyte.latest_checkpoint(prev_path)
if last:
ck = torch.load(str(last), map_location="cpu", weights_only=False)
epoch_start = int(ck.get("epoch", 0))
resume_ckpt = str(last)
print(f"Resuming from epoch {epoch_start}, checkpoint: {last}")
# --------------------------------------------------------------------
# {{/docs-fragment resume}}
metrics_cb = MetricsLoggerCallback(phase1_epochs=config.phase1_epochs)
resume_callback = (
FlyteLightningCheckpointCallback(
flyte_checkpoint,
dirpath=str(checkpoint_dir),
filename="last",
save_last=True,
save_top_k=1,
)
if flyte_checkpoint else
ModelCheckpoint(
dirpath=str(checkpoint_dir),
filename="best-{epoch:03d}-{val_acc:.3f}",
monitor="val/acc",
mode="max",
save_top_k=3,
verbose=True,
auto_insert_metric_name=False,
)
)
callbacks = [
resume_callback,
metrics_cb,
PhaseChangeCallback(
phase1_epochs=config.phase1_epochs,
phase2_lr=config.phase2_lr,
),
]
trainer = L.Trainer(
max_epochs=config.phase1_epochs + config.phase2_epochs,
accelerator="gpu" if torch.cuda.is_available() else "cpu",
devices=1,
precision="16-mixed",
callbacks=callbacks,
enable_progress_bar=True,
enable_model_summary=True,
log_every_n_steps=config.log_interval,
gradient_clip_val=1.0,
)
trainer.fit(model, train_loader, val_loader, ckpt_path=resume_ckpt)
best_checkpoint = trainer.checkpoint_callback.best_model_path
print(f"\n✓ Training complete!")
print(f"Best checkpoint: {best_checkpoint}")
# Final inference with TTA (test-time augmentation): average logits over
# original + h-flip + v-flip + 90° rotations for a free accuracy boost.
print("\nRunning final inference with TTA for confusion matrix...")
import numpy as np
import torchvision.transforms.functional as TF
model.eval()
model.to(device)
all_preds, all_targets = [], []
with torch.no_grad():
for images, labels in val_loader:
images = images.to(device)
aug_logits = [
model.model(images),
model.model(TF.hflip(images)),
model.model(TF.vflip(images)),
model.model(torch.rot90(images, k=1, dims=[2, 3])),
model.model(torch.rot90(images, k=3, dims=[2, 3])),
]
avg_logits = torch.stack(aug_logits).mean(dim=0)
all_preds.append(avg_logits.argmax(dim=1).cpu())
all_targets.append(labels.cpu())
final_preds = torch.cat(all_preds).numpy()
final_targets = torch.cat(all_targets).numpy()
return {
"best_checkpoint": best_checkpoint,
"metrics": metrics_cb.history,
"final_preds": final_preds.tolist(),
"final_targets": final_targets.tolist(),
}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/tumor_detection/training.py*
On startup, the training loop looks for a checkpoint from a previous attempt and resumes from it if present:
```
"""
Training pipeline for brain tumor MRI classification.
Implements two-phase training:
- Phase 1: Frozen backbone (feature extractor), train classification head
- Phase 2: Fine-tune full model with differential LRs + cosine annealing
"""
from config import TrainingConfig
from dataset import compute_class_weights, create_data_loaders
from model import TumorClassifierLightningModule
from utils import get_model_size, get_trainable_params
def train_tumor_classifier(
config: TrainingConfig,
dataset_path: str,
) -> dict:
"""
Run two-phase training on the preprocessed dataset and return metrics + final predictions.
dataset_path: local directory where the flyte.io.Dir was downloaded by the training task.
"""
import pathlib
import flyte
import lightning as L
import torch
from lightning.pytorch.callbacks import ModelCheckpoint
from typing_extensions import override
# {{docs-fragment flyte_checkpoint}}
class FlyteLightningCheckpointCallback(ModelCheckpoint):
"""Mirrors the checkpoint directory to Flyte after every epoch so retries can resume."""
def __init__(self, flyte_checkpoint: flyte.Checkpoint, *, dirpath: str, **kwargs):
super().__init__(dirpath=dirpath, **kwargs)
self._flyte_checkpoint = flyte_checkpoint
@override
def on_train_epoch_end(self, trainer: L.Trainer, pl_module: L.LightningModule) -> None:
super().on_train_epoch_end(trainer, pl_module)
if self.dirpath:
self._flyte_checkpoint.save_sync(pathlib.Path(self.dirpath))
# {{/docs-fragment flyte_checkpoint}}
class MetricsLoggerCallback(L.Callback):
def __init__(self, phase1_epochs: int):
super().__init__()
self.phase1_epochs = phase1_epochs
self.history = []
def on_validation_epoch_end(self, trainer, _pl_module):
epoch = trainer.current_epoch
metrics = trainer.callback_metrics
self.history.append({
"epoch": epoch,
"phase": 1 if epoch < self.phase1_epochs else 2,
"train_loss": float(metrics.get("train/loss_epoch", 0)),
"val_loss": float(metrics.get("val/loss", 0)),
"val_acc": float(metrics.get("val/acc", 0)),
"macro_f1": float(metrics.get("val/macro_f1", 0)),
})
class PhaseChangeCallback(L.Callback):
def __init__(self, phase1_epochs: int, phase2_lr: float):
super().__init__()
self.phase1_epochs = phase1_epochs
self.phase2_lr = phase2_lr
self.phase_changed = False
def on_train_epoch_end(self, trainer, pl_module):
if not self.phase_changed and (trainer.current_epoch + 1) == self.phase1_epochs:
print("\n" + "=" * 80)
print("TRANSITIONING TO PHASE 2: UNFREEZING BACKBONE AND ADJUSTING LR")
print("=" * 80 + "\n")
pl_module.model.unfreeze_backbone()
for param_group in trainer.optimizers[0].param_groups:
param_group["lr"] = self.phase2_lr
# Add backbone params to optimizer with 10x lower LR.
# Backbone was excluded at init because it was frozen.
backbone_lr = self.phase2_lr * 0.1
backbone_decay, backbone_no_decay = [], []
for param in pl_module.model.backbone.parameters():
if param.ndim >= 2:
backbone_decay.append(param)
else:
backbone_no_decay.append(param)
optimizer = trainer.optimizers[0]
optimizer.add_param_group({"params": backbone_decay, "lr": backbone_lr, "weight_decay": pl_module.weight_decay})
optimizer.add_param_group({"params": backbone_no_decay, "lr": backbone_lr, "weight_decay": 0.0})
# Fresh cosine schedule over remaining Phase 2 steps to avoid
# the Phase 1 schedule arriving near-zero before Phase 2 begins.
steps_remaining = trainer.estimated_stepping_batches - trainer.global_step
new_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
trainer.optimizers[0],
T_max=max(1, steps_remaining),
eta_min=1e-6,
)
for lr_scheduler_config in trainer.lr_scheduler_configs:
lr_scheduler_config.scheduler = new_scheduler
print(f"Phase 2 started: lr={self.phase2_lr}")
print(f"Total parameters: {get_model_size(pl_module.model):,}")
print(f"Trainable parameters: {get_trainable_params(pl_module.model):,}")
self.phase_changed = True
print("\n" + "=" * 80)
print("BRAIN TUMOR MRI CLASSIFICATION WITH EFFICIENTNET-B4")
print("=" * 80)
print(f"Config: {config.to_dict()}\n")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
if torch.cuda.is_available():
print(f"GPU: {torch.cuda.get_device_name(0)}")
print(f"GPU Memory: {torch.cuda.get_device_properties(0).total_memory / 1e9:.2f} GB")
print("\nLoading MRI images...")
train_loader, val_loader = create_data_loaders(
dataset_path=dataset_path,
image_size=config.image_size,
batch_size=config.batch_size,
num_workers=config.num_workers,
val_split=config.val_split,
)
print(f"Data loaders created: {len(train_loader)} train batches, {len(val_loader)} val batches")
print("\nComputing class weights for focal loss...")
class_weights = compute_class_weights(dataset_path)
print(f"Class weights: {class_weights.tolist()}")
# Per-class gamma: Meningioma gets 7.0, all others 3.0.
# CLASS_NAMES alphabetical order: Glioma=0, Meningioma=1, No Tumor=2, Pituitary=3
gamma_per_class = torch.tensor([3.0, 7.0, 3.0, 3.0])
print("\nInitializing model...")
model = TumorClassifierLightningModule(
num_classes=config.num_classes,
model_name=config.model_name,
pretrained=config.pretrained,
learning_rate=config.phase1_lr,
freeze_backbone=config.phase1_freeze_backbone,
weight_decay=config.weight_decay,
warmup_steps=config.warmup_steps,
max_epochs=config.phase1_epochs + config.phase2_epochs,
focal_gamma=config.focal_gamma,
mixup_alpha=config.mixup_alpha,
class_weights=class_weights,
gamma_per_class=gamma_per_class,
)
print(f"Model: {config.model_name}")
print(f"Total parameters: {get_model_size(model.model):,}")
print(f"Trainable parameters: {get_trainable_params(model.model):,}")
from pathlib import Path
checkpoint_dir = Path("/tmp/tumor_checkpoints")
checkpoint_dir.mkdir(parents=True, exist_ok=True)
# {{docs-fragment resume}}
# --- Flyte checkpoint: resume from previous attempt if one exists ---
resume_ckpt: str | None = None
ctx = flyte.ctx()
flyte_checkpoint = getattr(ctx, "checkpoint", None) if ctx else None
if flyte_checkpoint:
prev_path = flyte_checkpoint.load_sync()
if prev_path:
last = flyte.latest_checkpoint(prev_path)
if last:
ck = torch.load(str(last), map_location="cpu", weights_only=False)
epoch_start = int(ck.get("epoch", 0))
resume_ckpt = str(last)
print(f"Resuming from epoch {epoch_start}, checkpoint: {last}")
# --------------------------------------------------------------------
# {{/docs-fragment resume}}
metrics_cb = MetricsLoggerCallback(phase1_epochs=config.phase1_epochs)
resume_callback = (
FlyteLightningCheckpointCallback(
flyte_checkpoint,
dirpath=str(checkpoint_dir),
filename="last",
save_last=True,
save_top_k=1,
)
if flyte_checkpoint else
ModelCheckpoint(
dirpath=str(checkpoint_dir),
filename="best-{epoch:03d}-{val_acc:.3f}",
monitor="val/acc",
mode="max",
save_top_k=3,
verbose=True,
auto_insert_metric_name=False,
)
)
callbacks = [
resume_callback,
metrics_cb,
PhaseChangeCallback(
phase1_epochs=config.phase1_epochs,
phase2_lr=config.phase2_lr,
),
]
trainer = L.Trainer(
max_epochs=config.phase1_epochs + config.phase2_epochs,
accelerator="gpu" if torch.cuda.is_available() else "cpu",
devices=1,
precision="16-mixed",
callbacks=callbacks,
enable_progress_bar=True,
enable_model_summary=True,
log_every_n_steps=config.log_interval,
gradient_clip_val=1.0,
)
trainer.fit(model, train_loader, val_loader, ckpt_path=resume_ckpt)
best_checkpoint = trainer.checkpoint_callback.best_model_path
print(f"\n✓ Training complete!")
print(f"Best checkpoint: {best_checkpoint}")
# Final inference with TTA (test-time augmentation): average logits over
# original + h-flip + v-flip + 90° rotations for a free accuracy boost.
print("\nRunning final inference with TTA for confusion matrix...")
import numpy as np
import torchvision.transforms.functional as TF
model.eval()
model.to(device)
all_preds, all_targets = [], []
with torch.no_grad():
for images, labels in val_loader:
images = images.to(device)
aug_logits = [
model.model(images),
model.model(TF.hflip(images)),
model.model(TF.vflip(images)),
model.model(torch.rot90(images, k=1, dims=[2, 3])),
model.model(torch.rot90(images, k=3, dims=[2, 3])),
]
avg_logits = torch.stack(aug_logits).mean(dim=0)
all_preds.append(avg_logits.argmax(dim=1).cpu())
all_targets.append(labels.cpu())
final_preds = torch.cat(all_preds).numpy()
final_targets = torch.cat(all_targets).numpy()
return {
"best_checkpoint": best_checkpoint,
"metrics": metrics_cb.history,
"final_preds": final_preds.tolist(),
"final_targets": final_targets.tolist(),
}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/tumor_detection/training.py*
## Generate the report
The reporting task reads the metrics and predictions, then renders accuracy/loss curves, a confusion matrix, and a per-class F1 chart with Plotly. `report=True` surfaces the HTML directly in the run's report panel.
```
"""
Flyte/Union pipeline for brain tumor MRI classification.
Three-task pipeline:
1. load_dataset — download Brain Tumor MRI from Hugging Face, cache as Dir (CPU)
2. train_model — two-phase EfficientNet-B4 training with focal loss (GPU)
3. create_report — render training curves and confusion matrix in the Union UI (CPU)
"""
import json
import flyte
from flyte.io import Dir
from config import TrainingConfig, dataset_env, pipeline_env, report_env, training_env
from dataset import download_tumor_dataset
# {{docs-fragment config}}
TRAINING_CONFIG = TrainingConfig(
phase1_epochs=8,
phase2_epochs=25,
phase1_lr=1e-3,
phase2_lr=5e-5,
batch_size=16,
num_workers=0,
log_interval=50,
mixup_alpha=0.0,
image_size=380,
focal_gamma=3.0,
)
# {{/docs-fragment config}}
# {{docs-fragment load_dataset}}
@dataset_env.task
async def load_dataset() -> Dir:
"""
Download raw Brain Tumor MRI JPEG files from Hugging Face and cache as flyte.io.Dir.
Runs once — result is reused on subsequent pipeline runs (cache="auto").
"""
return await download_tumor_dataset()
# {{/docs-fragment load_dataset}}
# {{docs-fragment train_model}}
@training_env.task(retries=3)
async def train_model(dataset_dir: Dir, config_json: str) -> Dir:
"""
Download the raw dataset Dir, run two-phase training,
and return training metrics and final predictions as a Dir for the report task.
"""
from pathlib import Path
local_dir = Path("/tmp/tumor_local")
local_dir.mkdir(parents=True, exist_ok=True)
await dataset_dir.download(local_path=str(local_dir))
from training import train_tumor_classifier
config = TrainingConfig(**json.loads(config_json))
result = train_tumor_classifier(config=config, dataset_path=str(local_dir))
output_dir = Path("/tmp/training_results")
output_dir.mkdir(parents=True, exist_ok=True)
(output_dir / "metrics.json").write_text(json.dumps(result["metrics"]))
(output_dir / "predictions.json").write_text(json.dumps({
"preds": result["final_preds"],
"targets": result["final_targets"],
}))
return await Dir.from_local(str(output_dir))
# {{/docs-fragment train_model}}
# {{docs-fragment create_report}}
@report_env.task(report=True)
async def create_report(results_dir: Dir) -> None:
"""
Download training metrics and render loss/accuracy curves, confusion matrix,
and per-class F1 chart in the Union UI report panel.
"""
import numpy as np
from pathlib import Path
from utils import create_confusion_matrix_plot, create_metrics_plots, create_per_class_f1_plot
local_dir = Path("/tmp/tumor_report")
local_dir.mkdir(parents=True, exist_ok=True)
await results_dir.download(local_path=str(local_dir))
matches = list(local_dir.glob("**/metrics.json"))
if not matches:
raise RuntimeError(f"metrics.json not found under {local_dir}")
local_path = matches[0].parent
history = json.loads((local_path / "metrics.json").read_text())
predictions = json.loads((local_path / "predictions.json").read_text())
preds = np.array(predictions["preds"])
targets = np.array(predictions["targets"])
loss_fig, acc_fig = create_metrics_plots(history)
cm_fig = create_confusion_matrix_plot(preds, targets)
f1_fig = create_per_class_f1_plot(preds, targets)
combined_html = (
acc_fig.to_html(include_plotlyjs=True, full_html=False)
+ loss_fig.to_html(include_plotlyjs=False, full_html=False)
+ cm_fig.to_html(include_plotlyjs=False, full_html=False)
+ f1_fig.to_html(include_plotlyjs=False, full_html=False)
)
flyte.report.log(combined_html, do_flush=True)
# {{/docs-fragment create_report}}
# {{docs-fragment pipeline}}
@pipeline_env.task
async def tumor_detection_pipeline() -> None:
"""Orchestrate dataset loading, GPU training, and report generation."""
dataset_dir = await load_dataset()
results_dir = await train_model(
dataset_dir=dataset_dir,
config_json=json.dumps(TRAINING_CONFIG.to_dict()),
)
await create_report(results_dir=results_dir)
# {{/docs-fragment pipeline}}
if __name__ == "__main__":
import pathlib
flyte.init_from_config(root_dir=pathlib.Path(__file__).parent)
run = flyte.with_runcontext().run(tumor_detection_pipeline)
print(f"\n✓ Pipeline submitted!")
print(f"Run URL: {run.url}")
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/tumor_detection/run.py*
## Orchestrate the pipeline
The driver task wires the three steps together.
```
"""
Flyte/Union pipeline for brain tumor MRI classification.
Three-task pipeline:
1. load_dataset — download Brain Tumor MRI from Hugging Face, cache as Dir (CPU)
2. train_model — two-phase EfficientNet-B4 training with focal loss (GPU)
3. create_report — render training curves and confusion matrix in the Union UI (CPU)
"""
import json
import flyte
from flyte.io import Dir
from config import TrainingConfig, dataset_env, pipeline_env, report_env, training_env
from dataset import download_tumor_dataset
# {{docs-fragment config}}
TRAINING_CONFIG = TrainingConfig(
phase1_epochs=8,
phase2_epochs=25,
phase1_lr=1e-3,
phase2_lr=5e-5,
batch_size=16,
num_workers=0,
log_interval=50,
mixup_alpha=0.0,
image_size=380,
focal_gamma=3.0,
)
# {{/docs-fragment config}}
# {{docs-fragment load_dataset}}
@dataset_env.task
async def load_dataset() -> Dir:
"""
Download raw Brain Tumor MRI JPEG files from Hugging Face and cache as flyte.io.Dir.
Runs once — result is reused on subsequent pipeline runs (cache="auto").
"""
return await download_tumor_dataset()
# {{/docs-fragment load_dataset}}
# {{docs-fragment train_model}}
@training_env.task(retries=3)
async def train_model(dataset_dir: Dir, config_json: str) -> Dir:
"""
Download the raw dataset Dir, run two-phase training,
and return training metrics and final predictions as a Dir for the report task.
"""
from pathlib import Path
local_dir = Path("/tmp/tumor_local")
local_dir.mkdir(parents=True, exist_ok=True)
await dataset_dir.download(local_path=str(local_dir))
from training import train_tumor_classifier
config = TrainingConfig(**json.loads(config_json))
result = train_tumor_classifier(config=config, dataset_path=str(local_dir))
output_dir = Path("/tmp/training_results")
output_dir.mkdir(parents=True, exist_ok=True)
(output_dir / "metrics.json").write_text(json.dumps(result["metrics"]))
(output_dir / "predictions.json").write_text(json.dumps({
"preds": result["final_preds"],
"targets": result["final_targets"],
}))
return await Dir.from_local(str(output_dir))
# {{/docs-fragment train_model}}
# {{docs-fragment create_report}}
@report_env.task(report=True)
async def create_report(results_dir: Dir) -> None:
"""
Download training metrics and render loss/accuracy curves, confusion matrix,
and per-class F1 chart in the Union UI report panel.
"""
import numpy as np
from pathlib import Path
from utils import create_confusion_matrix_plot, create_metrics_plots, create_per_class_f1_plot
local_dir = Path("/tmp/tumor_report")
local_dir.mkdir(parents=True, exist_ok=True)
await results_dir.download(local_path=str(local_dir))
matches = list(local_dir.glob("**/metrics.json"))
if not matches:
raise RuntimeError(f"metrics.json not found under {local_dir}")
local_path = matches[0].parent
history = json.loads((local_path / "metrics.json").read_text())
predictions = json.loads((local_path / "predictions.json").read_text())
preds = np.array(predictions["preds"])
targets = np.array(predictions["targets"])
loss_fig, acc_fig = create_metrics_plots(history)
cm_fig = create_confusion_matrix_plot(preds, targets)
f1_fig = create_per_class_f1_plot(preds, targets)
combined_html = (
acc_fig.to_html(include_plotlyjs=True, full_html=False)
+ loss_fig.to_html(include_plotlyjs=False, full_html=False)
+ cm_fig.to_html(include_plotlyjs=False, full_html=False)
+ f1_fig.to_html(include_plotlyjs=False, full_html=False)
)
flyte.report.log(combined_html, do_flush=True)
# {{/docs-fragment create_report}}
# {{docs-fragment pipeline}}
@pipeline_env.task
async def tumor_detection_pipeline() -> None:
"""Orchestrate dataset loading, GPU training, and report generation."""
dataset_dir = await load_dataset()
results_dir = await train_model(
dataset_dir=dataset_dir,
config_json=json.dumps(TRAINING_CONFIG.to_dict()),
)
await create_report(results_dir=results_dir)
# {{/docs-fragment pipeline}}
if __name__ == "__main__":
import pathlib
flyte.init_from_config(root_dir=pathlib.Path(__file__).parent)
run = flyte.with_runcontext().run(tumor_detection_pipeline)
print(f"\n✓ Pipeline submitted!")
print(f"Run URL: {run.url}")
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/tumor_detection/run.py*
## Run the pipeline
This example has no secrets — the dataset is public. Because the pipeline imports sibling modules and uses `with_source_folder`, run it from inside the example directory so the local files are picked up.
From the [example directory](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/tumor_detection):
```
cd v2/tutorials/tumor_detection
python run.py
```
Or submit it with the Flyte CLI from the same directory:
```
flyte run run.py tumor_detection_pipeline
```
When the run completes, open the `create_report` task in the UI to view the training curves, confusion matrix, and per-class F1 scores.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/biotech-healthcare/genomic-gene-comparison ===
# Cross-species gene comparison
> [!NOTE]
> Code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/genomic_gene_comparison).
This tutorial builds a bioinformatics pipeline that compares homologous genes across species. The workflow loads curated gene sequences (insulin, hemoglobin, or p53 by default), scores each sequence with the [Carbon](https://huggingface.co/HuggingFaceBio/Carbon-3B) genomic language model, aligns DNA and translated protein sequences, folds proteins with [ESMFold](https://github.com/facebookresearch/esm), and renders interactive HTML reports with identity heatmaps, phylogenetic trees, and 3D structure viewers.
Flyte makes the multi-stage GPU/CPU pipeline reliable:
- **Separate CPU and GPU `TaskEnvironment`s** so alignment runs on modest CPU boxes while Carbon scoring and ESMFold run on GPUs.
- **`report=True`** on every stage for live HTML progress and final summaries in the Flyte UI.
- **Cached data loading** and orchestrated fan-out across pipeline stages.
## Define the task environments
GPU tasks handle Carbon log-likelihood scoring and ESMFold structure prediction; CPU tasks load gene sets, run Needleman-Wunsch alignments, and generate the final summary.
```
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flyte>=2.4.0",
# "torch>=2.9.0",
# "transformers>=4.49.0",
# "accelerate>=0.34.0",
# "numpy",
# ]
# main = "pipeline"
# params = ""
# ///
import json
import logging
import math
import os
import tempfile
import flyte
import flyte.io
import flyte.report
# {{docs-fragment env}}
main_img = flyte.Image.from_uv_script(__file__, name="genomic-gene-comparison", pre=True)
gpu_env = flyte.TaskEnvironment(
name="genomic-gene-comparison-gpu",
image=main_img,
resources=flyte.Resources(cpu=4, memory="32Gi", gpu=1),
)
cpu_env = flyte.TaskEnvironment(
name="genomic-gene-comparison-cpu",
image=main_img,
resources=flyte.Resources(cpu=2, memory="8Gi"),
depends_on=[gpu_env],
)
# {{/docs-fragment env}}
logging.basicConfig(level=logging.WARNING, format="%(message)s", force=True)
log = logging.getLogger(__name__)
log.setLevel(logging.INFO)
# ------------------------------------------------------------------
# Homologous gene sets - same gene across species
# ------------------------------------------------------------------
# Full-length coding sequences from NCBI RefSeq (stop codon excluded).
GENE_SETS = {
"insulin": {
"gene_name": "Insulin",
"description": "Insulin regulates blood sugar in all vertebrates. Highly conserved across 500M+ years of evolution - even fish insulin can lower blood sugar in humans. Comparing across species reveals which regions are functionally essential (conserved) vs free to drift.",
"sequences": {
"Human": {
"dna": "ATGGCCCTGTGGATGCGCCTCCTGCCCCTGCTGGCGCTGCTGGCCCTCTGGGGACCTGACCCAGCCGCAGCCTTTGTGAACCAACACCTGTGCGGCTCACACCTGGTGGAAGCTCTCTACCTAGTGTGCGGGGAACGAGGCTTCTTCTACACACCCAAGACCCGCCGGGAGGCAGAGGACCTGCAGGTGGGGCAGGTGGAGCTGGGCGGGGGCCCTGGTGCAGGCAGCCTGCAGCCCTTGGCCCTGGAGGGGTCCCTGCAGAAGCGTGGCATTGTGGAACAATGCTGTACCAGCATCTGCTCCCTCTACCAGCTGGAGAACTACTGCAAC",
"common_name": "Homo sapiens",
},
"Mouse": {
"dna": "ATGGCCCTGTGGATGCGCTTCCTGCCCCTGCTGGCCCTGCTCTTCCTCTGGGAGTCCCACCCCACCCAGGCTTTTGTCAAGCAGCACCTTTGTGGTTCCCACCTGGTGGAGGCTCTCTACCTGGTGTGTGGGGAGCGTGGCTTCTTCTACACACCCATGTCCCGCCGTGAAGTGGAGGACCCACAAGTGGCACAACTGGAGCTGGGTGGAGGCCCGGGAGCAGGTGACCTTCAGACCTTGGCACTGGAGGTGGCCCAGCAGAAGCGTGGCATTGTAGATCAGTGCTGCACCAGCATCTGCTCCCTCTACCAGCTGGAGAACTACTGCAAC",
"common_name": "Mus musculus",
},
"Chicken": {
"dna": "ATGGCTCTCTGGATCCGATCACTGCCTCTTCTGGCTCTCCTTGTCTTTTCTGGCCCTGGAACCAGCTATGCAGCTGCCAACCAGCACCTCTGTGGCTCCCACTTGGTGGAGGCTCTCTACCTGGTGTGTGGAGAGCGTGGCTTCTTCTACTCCCCCAAAGCCCGACGGGATGTCGAGCAGCCCCTAGTGAGCAGTCCCTTGCGTGGCGAGGCAGGAGTGCTGCCTTTCCAGCAGGAGGAATACGAGAAAGTCAAGCGAGGGATTGTTGAGCAATGCTGCCATAACACGTGTTCCCTCTACCAACTGGAGAACTACTGCAAC",
"common_name": "Gallus gallus",
},
"Zebrafish": {
"dna": "ATGGCAGTGTGGCTTCAGGCTGGTGCTCTGTTGGTCCTGTTGGTCGTGTCCAGTGTAAGCACTAACCCAGGCACACCGCAGCACCTGTGTGGATCTCATCTGGTCGATGCCCTTTATCTGGTCTGTGGCCCAACAGGCTTCTTCTACAACCCCAAGAGAGACGTTGAGCCCCTTCTGGGTTTCCTTCCTCCTAAATCTGCCCAGGAAACTGAGGTGGCTGACTTTGCATTTAAAGATCATGCCGAGCTGATAAGGAAGAGAGGCATTGTAGAGCAGTGCTGCCACAAACCCTGCAGCATCTTTGAGCTGCAGAACTACTGTAAC",
"common_name": "Danio rerio",
},
"Frog": {
"dna": "ATGGCTCTATGGATGCAGTGTCTGCCCCTGGTTCTTGTCCTCTTTTTCTCTACACCCAACACCGAAGCTCTAGTTAACCAGCACTTGTGTGGGTCTCACCTGGTAGAAGCCCTGTACTTAGTATGTGGGGATCGAGGCTTCTTCTACTACCCTAAGGTCAAACGGGACATGGAACAAGCACTTGTCAGTGGACCCCAGGATAATGAGTTGGATGGAATGCAGCTCCAGCCTCAGGAGTATCAGAAAATGAAGAGGGGGATTGTGGAGCAATGTTGCCACAGCACATGTTCTCTCTTCCAGCTGGAGAGTTACTGCAAC",
"common_name": "Xenopus laevis",
},
"Cow": {
"dna": "ATGGCCCTGTGGACACGCCTGGCGCCCCTGCTGGCCCTGCTGGCGCTCTGGGCCCCCGCCCCGGCCCGCGCCTTCGTCAACCAGCATCTGTGTGGCTCCCACCTGGTGGAGGCGCTGTACCTGGTGTGCGGAGAGCGCGGCTTCTTCTACACGCCCAAGGCCCGCCGGGAGGTGGAGGGCCCCCAGGTGGGGGCGCTGGAGCTGGCCGGAGGCCCGGGCGCGGGCGGCCTGGAGGGGCCCCCGCAGAAGCGTGGCATCGTGGAGCAGTGCTGTGCCAGCGTCTGCTCGCTCTACCAGCTGGAGAACTACTGTAAC",
"common_name": "Bos taurus",
},
},
},
"hemoglobin": {
"gene_name": "Hemoglobin Beta",
"description": "Beta-globin carries oxygen from lungs to tissues. The most studied gene in molecular evolution - sequence differences power the 'molecular clock' hypothesis. Sickle cell mutation (E6V) in humans shows how a single base change creates devastating disease.",
"sequences": {
"Human": {
"dna": "ATGGTGCATCTGACTCCTGAGGAGAAGTCTGCCGTTACTGCCCTGTGGGGCAAGGTGAACGTGGATGAAGTTGGTGGTGAGGCCCTGGGCAGGCTGCTGGTGGTCTACCCTTGGACCCAGAGGTTCTTTGAGTCCTTTGGGGATCTGTCCACTCCTGATGCTGTTATGGGCAACCCTAAGGTGAAGGCTCATGGCAAGAAAGTGCTCGGTGCCTTTAGTGATGGCCTGGCTCACCTGGACAACCTCAAGGGCACCTTTGCCACACTGAGTGAGCTGCACTGTGACAAGCTGCACGTGGATCCTGAGAACTTCAGGCTCCTGGGCAACGTGCTGGTCTGTGTGCTGGCCCATCACTTTGGCAAAGAATTCACCCCACCAGTGCAGGCTGCCTATCAGAAAGTGGTGGCTGGTGTGGCTAATGCCCTGGCCCACAAGTATCAC",
"common_name": "Homo sapiens",
},
"Mouse": {
"dna": "ATGGTGCACCTGACTGATGCTGAGAAGGCTGCTGTCTCTGGCCTGTGGGGAAAGGTGAACGCCGATGAAGTTGGTGGTGAGGCCCTGGGCAGGCTGCTGGTTGTCTACCCTTGGACCCAGCGGTACTTTGATAGCTTTGGAGACCTATCCTCTGCCTCTGCTATCATGGGTAATGCCAAAGTGAAGGCCCATGGCAAGAAAGTGATAACTGCCTTTAACGATGGCCTGAATCACTTGGACAGCCTCAAGGGCACCTTTGCCAGCCTCAGTGAGCTCCACTGTGACAAGCTGCATGTGGATCCTGAGAACTTCAGGCTCCTGGGCAATATGATCGTGATTGTGCTGGGCCACCACCTGGGCAAGGATTTCACCCCCGCTGCACAGGCTGCCTTCCAGAAGGTGGTGGCTGGAGTGGCTGCTGCCCTGGCTCACAAGTACCAC",
"common_name": "Mus musculus",
},
"Chicken": {
"dna": "ATGGTGCACTGGACTGCTGAGGAGAAGCAGCTCATCACCGGCCTCTGGGGCAAGGTCAATGTGGCCGAATGTGGGGCTGAAGCCCTGGCCAGGCTGCTGATCGTCTACCCCTGGACCCAGAGGTTCTTTGCGTCCTTTGGGAACCTCTCCAGCCCCACTGCCATCCTTGGCAACCCCATGGTCCGCGCCCATGGCAAGAAAGTGCTCACCTCCTTTGGGGATGCTGTGAAGAACCTGGACAACATCAAGAACACCTTCTCCCAACTGTCCGAACTGCATTGTGACAAGCTGCATGTGGACCCCGAGAACTTCAGGCTCCTGGGTGACATCCTCATCATTGTCCTGGCCGCCCACTTCAGCAAGGACTTCACTCCTGAATGCCAGGCTGCCTGGCAGAAGCTGGTCCGCGTGGTGGCCCATGCCCTGGCTCGCAAGTACCAC",
"common_name": "Gallus gallus",
},
"Zebrafish": {
"dna": "ATGGTTGAGTGGACAGATGCCGAGCGCACAGCCATCCTTGGCCTGTGGGGAAAGCTCAATATCGATGAAATCGGACCTCAGGCCCTATCCAGATGTCTGATCGTGTATCCCTGGACTCAGAGATATTTCGCCACATTCGGCAACCTGTCAAGCCCCGCTGCGATCATGGGTAACCCCAAAGTGGCAGCTCATGGGAGGACTGTGATGGGAGGTCTTGAGAGAGCCATCAAGAACATGGACAACGTCAAGAACACCTATGCCGCCCTCAGTGTGATGCACTCTGAGAAACTGCATGTGGATCCCGACAACTTCAGGCTTCTCGCTGATTGCATCACCGTTTGCGCTGCCATGAAGTTCGGCCAAGCTGGTTTCAATGCTGATGTCCAGGAGGCCTGGCAGAAGTTTCTGGCTGTGGTCGTTTCTGCTCTGTGCAGACAGTACCAC",
"common_name": "Danio rerio",
},
"Frog": {
"dna": "ATGGTTCATTGGACAGCTGAAGAGAAGGCCGCCATCACCTCTGTGTGGCAGGAGGTCAACCAGGAGCAAGATGGCCATGATGCACTCACAAGGCTGCTGGTTGTGTACCCCTGGACCCAGAGATACTTCAGCAGTTTTGGAAATCTCGGTAATGCCACAGCTATTGCTGGAAATGTCAAGGTGCGTGCCCATGGCAAGAAGGTTCTTTCAGCTGTTGGTGATGCCATCGCCCATCTTGACAACGTGAAGGGAACTCTCCATGACCTCAGTGTGGTCCACGCCTTCAAGCTCTATGTGGATCCTGAGAACTTCAAGCGTCTTGGTGAAGTTCTGGTCATTGTCTTGGCTTCCAAACTGGGATCAGCCTTTACTCCTCAAGTCCAGGGAGCCTGGGAGAAATTTGTTGCTGTTCTGGTTGATGCCCTCAGCCAAGGATACAAC",
"common_name": "Xenopus laevis",
},
"Cow": {
"dna": "ATGCTGACTGCTGAGGAGAAGGCTGCCGTCACCGCCTTTTGGGGCAAGGTGAAAGTGGATGAAGTTGGTGGTGAGGCCCTGGGCAGGCTGCTGGTTGTCTACCCCTGGACTCAGAGGTTCTTTGAGTCCTTTGGGGACTTGTCCACTGCTGATGCTGTTATGAACAACCCTAAGGTGAAGGCCCATGGCAAGAAGGTGCTAGATTCCTTTAGTAATGGCATGAAGCATCTCGATGACCTCAAGGGCACCTTTGCTGCGCTGAGTGAGCTGCACTGTGATAAGCTGCATGTGGATCCTGAGAACTTCAAGCTCCTGGGCAACGTGCTAGTGGTTGTGCTGGCTCGCAATTTTGGCAAGGAATTCACCCCGGTGCTGCAGGCTGACTTTCAGAAGGTGGTGGCTGGTGTGGCCAATGCCCTGGCCCACAGATATCAT",
"common_name": "Bos taurus",
},
},
},
"p53": {
"gene_name": "p53 (TP53)",
"description": "The 'guardian of the genome' - p53 detects DNA damage and triggers repair or cell death. Mutated in >50% of human cancers. Elephants have 20 copies of p53 (humans have 1), which may explain their extremely low cancer rates despite their size (Peto's paradox).",
"sequences": {
"Human": {
"dna": "ATGGAGGAGCCGCAGTCAGATCCTAGCGTCGAGCCCCCTCTGAGTCAGGAAACATTTTCAGACCTATGGAAACTACTTCCTGAAAACAACGTTCTGTCCCCCTTGCCGTCCCAAGCAATGGATGATTTGATGCTGTCCCCGGACGATATTGAACAATGGTTCACTGAAGACCCAGGTCCAGATGAAGCTCCCAGAATGCCAGAGGCTGCTCCCCCCGTGGCCCCTGCACCAGCAGCTCCTACACCGGCGGCCCCTGCACCAGCCCCCTCCTGGCCCCTGTCATCTTCTGTCCCTTCCCAGAAAACCTACCAGGGCAGCTACGGTTTCCGTCTGGGCTTCTTGCATTCTGGGACAGCCAAGTCTGTGACTTGCACGTACTCCCCTGCCCTCAACAAGATGTTTTGCCAACTGGCCAAGACCTGCCCTGTGCAGCTGTGGGTTGATTCCACACCCCCGCCCGGCACCCGCGTCCGCGCCATGGCCATCTACAAGCAGTCACAGCACATGACGGAGGTTGTGAGGCGCTGCCCCCACCATGAGCGCTGCTCAGATAGCGATGGTCTGGCCCCTCCTCAGCATCTTATCCGAGTGGAAGGAAATTTGCGTGTGGAGTATTTGGATGACAGAAACACTTTTCGACATAGTGTGGTGGTGCCCTATGAGCCGCCTGAGGTTGGCTCTGACTGTACCACCATCCACTACAACTACATGTGTAACAGTTCCTGCATGGGCGGCATGAACCGGAGGCCCATCCTCACCATCATCACACTGGAAGACTCCAGTGGTAATCTACTGGGACGGAACAGCTTTGAGGTGCGTGTTTGTGCCTGTCCTGGGAGAGACCGGCGCACAGAGGAAGAGAATCTCCGCAAGAAAGGGGAGCCTCACCACGAGCTGCCCCCAGGGAGCACTAAGCGAGCACTGCCCAACAACACCAGCTCCTCTCCCCAGCCAAAGAAGAAACCACTGGATGGAGAATATTTCACCCTTCAGATCCGTGGGCGTGAGCGCTTCGAGATGTTCCGAGAGCTGAATGAGGCCTTGGAACTCAAGGATGCCCAGGCTGGGAAGGAGCCAGGGGGGAGCAGGGCTCACTCCAGCCACCTGAAGTCCAAAAAGGGTCAGTCTACCTCCCGCCATAAAAAACTCATGTTCAAGACAGAAGGGCCTGACTCAGAC",
"common_name": "Homo sapiens",
},
"Mouse": {
"dna": "ATGACTGCCATGGAGGAGTCACAGTCGGATATCAGCCTCGAGCTCCCTCTGAGCCAGGAGACATTTTCAGGCTTATGGAAACTACTTCCTCCAGAAGATATCCTGCCATCACCTCACTGCATGGACGATCTGTTGCTGCCCCAGGATGTTGAGGAGTTTTTTGAAGGCCCAAGTGAAGCCCTCCGAGTGTCAGGAGCTCCTGCAGCACAGGACCCTGTCACCGAGACCCCTGGGCCAGTGGCCCCTGCCCCAGCCACTCCATGGCCCCTGTCATCTTTTGTCCCTTCTCAAAAAACTTACCAGGGCAACTATGGCTTCCACCTGGGCTTCCTGCAGTCTGGGACAGCCAAGTCTGTTATGTGCACGTACTCTCCTCCCCTCAATAAGCTATTCTGCCAGCTGGCGAAGACGTGCCCTGTGCAGTTGTGGGTCAGCGCCACACCTCCAGCTGGGAGCCGTGTCCGCGCCATGGCCATCTACAAGAAGTCACAGCACATGACGGAGGTCGTGAGACGCTGCCCCCACCATGAGCGCTGCTCCGATGGTGATGGCCTGGCTCCTCCCCAGCATCTTATCCGGGTGGAAGGAAATTTGTATCCCGAGTATCTGGAAGACAGGCAGACTTTTCGCCACAGCGTGGTGGTACCTTATGAGCCACCCGAGGCCGGCTCTGAGTATACCACCATCCACTACAAGTACATGTGTAATAGCTCCTGCATGGGGGGCATGAACCGCCGACCTATCCTTACCATCATCACACTGGAAGACTCCAGTGGGAACCTTCTGGGACGGGACAGCTTTGAGGTTCGTGTTTGTGCCTGCCCTGGGAGAGACCGCCGTACAGAAGAAGAAAATTTCCGCAAAAAGGAAGTCCTTTGCCCTGAACTGCCCCCAGGGAGCGCAAAGAGAGCGCTGCCCACCTGCACAAGCGCCTCTCCCCCGCAAAAGAAAAAACCACTTGATGGAGAGTATTTCACCCTCAAGATCCGCGGGCGTAAACGCTTCGAGATGTTCCGGGAGCTGAATGAGGCCTTAGAGTTAAAGGATGCCCATGCTACAGAGGAGTCTGGAGACAGCAGGGCTCACTCCAGCTACCTGAAGACCAAGAAGGGCCAGTCTACTTCCCGCCATAAAAAAACAATGGTCAAGAAAGTGGGGCCTGACTCAGAC",
"common_name": "Mus musculus",
},
"Chicken": {
"dna": "ATGGCGGAGGAGATGGAACCATTGCTGGAACCCACTGAGGTCTTCATGGACCTCTGGAGCATGCTCCCCTATAGCATGCAACAGCTGCCCCTCCCTGAGGATCACAGCAACTGGCAGGAGCTGAGCCCCCTGGAACCCAGCGACCCCCCCCCACCACCGCCACCACCACCTCTGCCATTGGCCGCCGCCGCCCCCCCCCCATTAAACCCCCCCACCCCCCCCCGCGCTGCCCCCTCCCCGGTGGTCCCATCCACGGAGGATTATGGGGGGGACTTCGACTTCCGGGTGGGGTTCGTGGAGGCGGGCACAGCCAAATCGGTCACCTGCACTTACTCCCCGGTGCTGAATAAGGTCTATTGCCGCCTGGCCAAGCCGTGCCCGGTGCAGGTGAGGGTGGGGGTGGCGCCCCCCCCCGGTTCCTCCCTCCGCGCCGTGGCCGTCTATAAGAAATCAGAGCACGTGGCCGAAGTGGTGCGGCGCTGCCCCCACCACGAGCGCTGCGGGGGGGGCACCGACGGCCTGGCCCCCGCACAGCACCTCATCCGGGTGGAGGGGAACCCCCAGGCGCGTTACCACGACGACGAGACCACCAAACGGCACAGCGTCGTCGTCCCCTATGAGCCCCCCGAGGTGGGCTCTGACTGTACCACGGTGCTGTACAACTTCATGTGCAACAGTTCCTGCATGGGGGGGATGAACCGCCGCCCCATCCTCACCATCCTTACACTGGAGGGGCCGGGGGGGCAGCTGTTGGGGCGGCGCTGCTTCGAGGTGCGCGTGTGCGCATGTCCGGGGAGGGACCGCAAGATCGAGGAGGAGAACTTCCGCAAGAGGGGCGGGGCCGGGGGCGTGGCTAAGCGAGCCATGTCGCCCCCAACCGAAGCCCCCGAGCCCCCCAAGAAGCGCGTGCTGAACCCCGACAATGAGATATTCTACCTGCAGGTGCGCGGGCGCCGCCGCTATGAGATGCTGAAGGAGATCAATGAGGCGCTGCAGCTCGCCGAGGGGGGGTCCGCACCGCGGCCTTCCAAAGGCCGCCGTGTGAAGGTGGAGGGACCCCAACCCAGCTGCGGGAAGAAACTGCTGCAAAAAGGCTCGGAC",
"common_name": "Gallus gallus",
},
"Zebrafish": {
"dna": "ATGGCGCAAAACGACAGCCAAGAGTTCGCGGAGCTCTGGGAGAAGAATTTGATTATTCAGCCCCCAGGTGGTGGCTCTTGCTGGGACATCATTAATGATGAGGAGTACTTGCCGGGATCGTTTGACCCCAATTTTTTTGAAAATGTGCTTGAAGAACAGCCTCAGCCATCCACTCTCCCACCAACATCCACTGTTCCGGAGACAAGCGACTATCCCGGCGATCATGGATTTAGGCTCAGGTTCCCGCAGTCTGGCACAGCAAAATCTGTAACTTGCACTTATTCACCGGACCTGAATAAACTCTTCTGTCAGCTGGCAAAAACTTGCCCCGTTCAAATGGTGGTGGACGTTGCCCCTCCACAGGGCTCCGTGGTTCGAGCCACTGCCATCTATAAGAAGTCCGAGCATGTGGCTGAAGTGGTCCGCAGATGCCCCCATCATGAGCGAACCCCGGATGGAGATAACTTGGCGCCTGCTGGTCATTTGATAAGAGTGGAGGGCAATCAGCGAGCAAATTACAGGGAAGATAACATCACTTTAAGGCATAGTGTTTTTGTCCCATATGAAGCACCACAGCTTGGTGCTGAATGGACAACTGTGCTACTAAACTACATGTGCAATAGCAGCTGCATGGGGGGGATGAACCGCAGGCCCATCCTCACAATCATCACTCTGGAGACTCAGGAAGGTCAGTTGCTGGGCCGGAGGTCTTTTGAGGTGCGTGTGTGTGCATGTCCAGGCAGAGACAGGAAAACTGAGGAGAGCAACTTCAAGAAAGACCAAGAGACCAAAACCATGGCCAAAACCACCACTGGGACCAAACGTAGTTTGGTGAAAGAATCTTCTTCAGCTACATTACGACCTGAGGGGAGCAAAAAGGCCAAGGGCTCCAGCAGCGATGAGGAGATCTTTACCCTGCAGGTGAGGGGCAGGGAGCGTTATGAAATTTTAAAGAAATTGAACGACAGTCTGGAGTTAAGTGATGTGGTGCCTGCCTCAGATGCTGAAAAGTATCGTCAGAAATTCATGACAAAAAACAAAAAAGAGAATCGTGAATCATCTGAGCCCAAACAGGGAAAGAAGCTGATGGTGAAGGACGAAGGAAGAAGCGACTCTGAT",
"common_name": "Danio rerio",
},
"Elephant": {
"dna": "ATGGAGGAGCCCCAGTCAGATCTCAGCACCGAGCTCCCTCTGAGTCAAGAGACGTTTTCATACTTATGGGAACTCCTTCCTGAGAATCCGGTTCTGTCCCCCACACTACCCCCGGCAGTGGAGGTCATGGACGATCTGCTACTCTCAGAAGACACTGCAAACTGGCTAGAAAGCCAAGTTGAGGCTCAGGGAATGTCCACAACCCCTGCACCAGCCACCCCTACACCGGTGGCCCCCGCACCAGCCACCTCCTGGACCCTGTCATCTTCCGTCCCTTCCCAAAAGACCTACCCTGGCACCTATGGTTTCCGTCTGGGCTTCCTACATTCTGGGACAGCCAAGTCCGTCACCTGCACGTACTCCCCTGACCTTAACAAGCTGTTTTGCCAGCTGGCAAAAACCTGCCCAGTGCAGCTGTGGGTCGCCTCACCACCCCCGCCCGGCACCCGTGTTCGCACCATGGCCATCTACAAGAAGTCAGAGCATATGACGGAGGTCGTCAAGCGCTGCCCCCACCATGAGCGCTGCTCTGACTCTAGCGATGGCCTGGCCCCTCCTCAGCACCTCATCCGGGTGGAAGGAAACCTGCGTGCTGAGTATCTGGAGGACAGCATCACTCTCCGACACAGTGTGGTGGTGCCCTACGAGCCGCCCGAGGTTGGGTCTGACTGTACCACCATCCACTTCAACTTCATGTGTAACAGCTCCTGCATGGGGGGCATGAACCGGCGGCCCATCCTCACCATCATCACACTGGAAGACTCCAGTGGTAATCTGCTGGGACGTAACAGCTTTGAGGTGCGCATTTGTGCCTGTCCTGGAAGAGACAGACGTACAGAAGAAGAAAATTTCCACAAGAAGGGAGAGCCTTGCCCAGAGCCGCCACCCCCTGGGAGGAGCACTAAGCGAGCACTGCCCACCAACACCAGCTCCTCTACCCAGCCAAAGAAGAAGCCACTGGATGAAGAATATTTCACCCTTCAGATCCGTGGGCGTGAACGCTTCAAGATGTTCCTAGAGCTAAATGAGGCCTTGGAGCTGAAGGATGCCCAGGCTGGGAAGGAGCCAGAGGGGAGCCGGGCTCACTCCAGCCCTTCGAAGTCTAAGAAGGGACAGTCTACCTCCCGCCATAAAAAACCAATGTTCAAGAGAGAGGGACCTGACTCAGAC",
"common_name": "Loxodonta africana",
},
"Dog": {
"dna": "ATGGAGGAGTCGCAGTCAGAGCTCAATATCGACCCCCCTCTGAGCCAGGAGACATTTTCAGAATTGTGGAACCTGCTTCCTGAAAACAATGTTCTGTCTTCGGAGCTGTGCCCAGCAGTGGATGAGCTGCTGCTCCCAGAGAGCGTCGTGAACTGGCTAGACGAAGACTCAGATGATGCTCCCAGGATGCCAGCCACTTCTGCCCCCACAGCCCCTGGACCGGCCCCCTCGTGGCCCCTATCATCCTCTGTCCCTTCCCCGAAGACCTACCCTGGCACCTATGGGTTCCGTTTGGGGTTCCTGCATTCCGGGACAGCCAAGTCTGTTACTTGGACGTACTCCCCTCTCCTCAACAAGTTGTTTTGCCAGCTGGCGAAGACCTGCCCCGTGCAGCTGTGGGTCAGCTCCCCACCCCCACCCAATACCTGCGTCCGCGCTATGGCCATCTATAAGAAGTCGGAGTTCGTGACCGAGGTTGTGCGGCGCTGCCCCCACCATGAACGCTGCTCTGACAGTAGTGACGGTCTTGCCCCTCCTCAGCATCTCATCCGAGTGGAAGGAAATTTGCGGGCCAAGTACCTGGACGACAGAAACACTTTTCGACACAGTGTGGTGGTGCCTTATGAGCCACCCGAGGTTGGCTCTGACTATACCACCATCCACTACAACTACATGTGTAACAGTTCCTGCATGGGAGGCATGAACCGGCGGCCCATCCTCACTATCATCACCCTGGAAGACTCCAGTGGAAACGTGCTGGGACGCAACAGCTTTGAGGTACGCGTTTGTGCCTGTCCCGGGAGAGACCGCCGGACTGAGGAGGAGAATTTCCACAAGAAGGGGGAGCCTTGTCCTGAGCCACCCCCCGGGAGTACCAAGCGAGCACTGCCTCCCAGCACCAGCTCCTCTCCCCCGCAAAAGAAGAAGCCACTAGATGGAGAATATTTCACCCTTCAGATCCGTGGGCGTGAACGCTATGAGATGTTCAGGAATCTGAATGAAGCCTTGGAGCTGAAGGATGCCCAGAGTGGAAAGGAGCCAGGGGGAAGCAGGGCTCACTCCAGCCACCTGAAGGCAAAGAAGGGGCAATCTACCTCTCGCCATAAAAAACTGATGTTCAAGAGAGAAGGGCTTGACTCAGAC",
"common_name": "Canis lupus familiaris",
},
},
},
}
# Standard genetic code
CODON_TABLE = {
"TTT": "F", "TTC": "F", "TTA": "L", "TTG": "L", "CTT": "L", "CTC": "L",
"CTA": "L", "CTG": "L", "ATT": "I", "ATC": "I", "ATA": "I", "ATG": "M",
"GTT": "V", "GTC": "V", "GTA": "V", "GTG": "V", "TCT": "S", "TCC": "S",
"TCA": "S", "TCG": "S", "CCT": "P", "CCC": "P", "CCA": "P", "CCG": "P",
"ACT": "T", "ACC": "T", "ACA": "T", "ACG": "T", "GCT": "A", "GCC": "A",
"GCA": "A", "GCG": "A", "TAT": "Y", "TAC": "Y", "TAA": "*", "TAG": "*",
"CAT": "H", "CAC": "H", "CAA": "Q", "CAG": "Q", "AAT": "N", "AAC": "N",
"AAA": "K", "AAG": "K", "GAT": "D", "GAC": "D", "GAA": "E", "GAG": "E",
"TGT": "C", "TGC": "C", "TGA": "*", "TGG": "W", "CGT": "R", "CGC": "R",
"CGA": "R", "CGG": "R", "AGT": "S", "AGC": "S", "AGA": "R", "AGG": "R",
"GGT": "G", "GGC": "G", "GGA": "G", "GGG": "G",
}
BASE_COLORS = {"A": "#2ecc71", "T": "#e74c3c", "G": "#f39c12", "C": "#3498db"}
def _translate(dna: str) -> str:
"""Translate DNA to protein in reading frame 0."""
dna = dna.upper()
protein = []
for i in range(0, len(dna) - 2, 3):
codon = dna[i:i + 3]
aa = CODON_TABLE.get(codon, "X")
if aa == "*":
break
protein.append(aa)
return "".join(protein)
def _gc_content(seq: str) -> float:
if not seq:
return 0.0
return sum(1 for b in seq.upper() if b in "GC") / len(seq)
def _sequence_identity(seq1: str, seq2: str, match: int = 2, mismatch: int = -1, gap: int = -2) -> float:
"""Percent identity via Needleman-Wunsch global alignment."""
if not seq1 or not seq2:
return 0.0
n, m = len(seq1), len(seq2)
# Build score matrix
dp = [[0] * (m + 1) for _ in range(n + 1)]
for i in range(1, n + 1):
dp[i][0] = dp[i - 1][0] + gap
for j in range(1, m + 1):
dp[0][j] = dp[0][j - 1] + gap
for i in range(1, n + 1):
for j in range(1, m + 1):
s = match if seq1[i - 1] == seq2[j - 1] else mismatch
dp[i][j] = max(dp[i - 1][j - 1] + s, dp[i - 1][j] + gap, dp[i][j - 1] + gap)
# Traceback to count matches and alignment length
i, j = n, m
matches = 0
aligned = 0
while i > 0 or j > 0:
if i > 0 and j > 0:
s = match if seq1[i - 1] == seq2[j - 1] else mismatch
if dp[i][j] == dp[i - 1][j - 1] + s:
if seq1[i - 1] == seq2[j - 1]:
matches += 1
aligned += 1
i -= 1
j -= 1
continue
if i > 0 and dp[i][j] == dp[i - 1][j] + gap:
aligned += 1
i -= 1
else:
aligned += 1
j -= 1
return matches / aligned if aligned else 0.0
# ------------------------------------------------------------------
# Report styling
# ------------------------------------------------------------------
REPORT_CSS = """
"""
def _wrap_report(html: str) -> str:
return f'{REPORT_CSS}
{html}
'
# ------------------------------------------------------------------
# SVG chart helpers
# ------------------------------------------------------------------
def _make_heatmap(
matrix: list[list[float]],
row_labels: list[str],
col_labels: list[str],
title: str = "",
width: int = 600,
height: int = 500,
value_format: str = ".1f",
color_scale: str = "blue",
) -> str:
"""Generate an SVG heatmap."""
n_rows = len(matrix)
n_cols = len(matrix[0]) if matrix else 0
if not n_rows or not n_cols:
return ""
show_values = n_rows <= 10 and n_cols <= 10
flat = [v for row in matrix for v in row]
v_min = min(flat)
v_max = max(flat)
v_range = v_max - v_min or 1
if color_scale == "blue":
def get_color(v):
t = (v - v_min) / v_range
r = int(255 - t * (255 - 30))
g = int(255 - t * (255 - 58))
b = int(255 - t * (255 - 95))
return f"rgb({r},{g},{b})"
else: # green
def get_color(v):
t = (v - v_min) / v_range
r = int(255 - t * (255 - 6))
g = int(255 - t * (255 - 95))
b = int(255 - t * (255 - 70))
return f"rgb({r},{g},{b})"
ml = max(80, max(len(l) for l in row_labels) * 7 + 10) if row_labels else 80
mr = 20
mt = 80
mb = 20
cw = width - ml - mr
ch = height - mt - mb
cell_w = cw / n_cols
cell_h = ch / n_rows
svg = [
f'")
return "\n".join(svg)
def _make_dendrogram(
names: list[str],
matrix: list[list[float]],
title: str = "",
width: int = 700,
height: int = 350,
color: str = "#2563eb",
) -> str:
"""Generate an SVG dendrogram from a similarity matrix using UPGMA."""
n = len(names)
if n < 2:
return ""
dist = [[1.0 - matrix[i][j] for j in range(n)] for i in range(n)]
clusters = [{"members": [i], "height": 0.0, "left": None, "right": None} for i in range(n)]
active = list(range(n))
while len(active) > 1:
best_d = float("inf")
bi, bj = 0, 1
for ii in range(len(active)):
for jj in range(ii + 1, len(active)):
ci, cj = active[ii], active[jj]
d = 0
count = 0
for mi in clusters[ci]["members"]:
for mj in clusters[cj]["members"]:
d += dist[mi][mj]
count += 1
avg_d = d / count if count else 0
if avg_d < best_d:
best_d = avg_d
bi, bj = ii, jj
ci, cj = active[bi], active[bj]
new_cluster = {
"members": clusters[ci]["members"] + clusters[cj]["members"],
"height": best_d,
"left": clusters[ci],
"right": clusters[cj],
}
clusters.append(new_cluster)
new_idx = len(clusters) - 1
active.pop(bj)
active.pop(bi)
active.append(new_idx)
root = clusters[active[0]]
max_label_len = max((len(n) for n in names), default=0)
ml, mr, mt, mb = max(50, max_label_len * 5 + 10), 30, 40, 80
cw = width - ml - mr
ch = height - mt - mb
max_h = root["height"] or 1
leaf_positions = {}
leaf_counter = [0]
def assign_leaves(node):
if node["left"] is None and node["right"] is None:
leaf_positions[node["members"][0]] = leaf_counter[0]
leaf_counter[0] += 1
else:
if node["left"]:
assign_leaves(node["left"])
if node["right"]:
assign_leaves(node["right"])
assign_leaves(root)
n_leaves = len(leaf_positions)
leaf_spacing = cw / max(n_leaves - 1, 1)
svg = [
f'")
return "\n".join(svg)
def _make_bar_chart(
labels: list[str],
series: dict[str, list[float]],
title: str = "",
colors: list[str] | None = None,
width: int = 700,
height: int = 300,
value_format: str = ".1f",
) -> str:
"""Generate an SVG grouped bar chart."""
if not labels:
return ""
default_colors = ["#2563eb", "#059669", "#f59e0b", "#dc2626", "#7c3aed"]
colors = colors or default_colors
ml, mr, mt, mb = 60, 20, 40, 80
cw = width - ml - mr
ch = height - mt - mb
all_vals = [v for vals in series.values() for v in vals]
y_min = min(all_vals) if all_vals else 0
y_max = max(all_vals) if all_vals else 1
if y_min >= 0:
y_min_plot = 0
y_max_plot = y_max * 1.15 or 1
else:
y_range = y_max - y_min or 1
y_min_plot = y_min - y_range * 0.05
y_max_plot = y_max + y_range * 0.15
n_groups = len(labels)
n_series = len(series)
group_width = cw / n_groups
bar_width = group_width * 0.7 / max(n_series, 1)
gap = group_width * 0.15
def sy(v):
return mt + ch - ((v - y_min_plot) / (y_max_plot - y_min_plot)) * ch
svg = [
f'")
return "\n".join(svg)
def _make_plddt_sparkline(values: list[float], width: int = 400, height: int = 50) -> str:
"""pLDDT sparkline with AlphaFold-style coloring."""
if not values or len(values) < 2:
return ""
pad = 4
cw = width - 2 * pad
ch = height - 2 * pad
seg_w = cw / len(values)
svg = [
f'")
return "\n".join(svg)
def _outputs_to_pdb(outputs, sequence: str) -> str:
"""Convert ESMFold outputs to PDB format string."""
import numpy as np
pos = outputs.positions[0]
if pos.dim() == 4:
pos = pos[-1]
positions = pos.cpu().numpy()
atom_names = ["N", "CA", "C", "O"]
aa_3letter = {
"A": "ALA", "R": "ARG", "N": "ASN", "D": "ASP", "C": "CYS",
"Q": "GLN", "E": "GLU", "G": "GLY", "H": "HIS", "I": "ILE",
"L": "LEU", "K": "LYS", "M": "MET", "F": "PHE", "P": "PRO",
"S": "SER", "T": "THR", "W": "TRP", "Y": "TYR", "V": "VAL",
}
pdb_lines = []
atom_idx = 1
for res_idx, aa in enumerate(sequence):
res_name = aa_3letter.get(aa, "UNK")
for atom_i, atom_name in enumerate(atom_names):
if atom_i >= positions.shape[1]:
break
x, y, z = positions[res_idx, atom_i]
if any(math.isnan(c) for c in (x, y, z)):
continue
pdb_lines.append(
f"ATOM {atom_idx:5d} {atom_name:<3s} {res_name} A{res_idx + 1:4d} "
f"{x:8.3f}{y:8.3f}{z:8.3f} 1.00 0.00 {atom_name[0]:>2s}"
)
atom_idx += 1
pdb_lines.append("END")
return "\n".join(pdb_lines)
# ------------------------------------------------------------------
# Task 1: Load gene set
# ------------------------------------------------------------------
@cpu_env.task()
async def load_genes(
gene_set: str = "insulin",
custom_json: str = "",
) -> flyte.io.Dir:
"""Load a set of homologous genes from different species."""
if custom_json:
data = json.loads(custom_json)
elif gene_set in GENE_SETS:
data = GENE_SETS[gene_set]
else:
available = ", ".join(GENE_SETS.keys())
raise ValueError(f"Unknown gene set '{gene_set}'. Available: {available}")
log.info(f"Loaded gene set: {data['gene_name']} - {len(data['sequences'])} species")
out_dir = tempfile.mkdtemp(prefix="gene_compare_")
with open(os.path.join(out_dir, "genes.json"), "w") as f:
json.dump(data, f)
return await flyte.io.Dir.from_local(out_dir)
# ------------------------------------------------------------------
# Task 2: Score sequences with Carbon
# ------------------------------------------------------------------
@gpu_env.task(report=True)
async def score_sequences(
genes_dir: flyte.io.Dir,
model_name: str = "HuggingFaceBio/Carbon-3B",
) -> str:
"""Score each species' gene with Carbon-3B genomic language model.
Returns per-species log-likelihood scores and sequence metadata.
"""
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
log.info(f"Loading Carbon model: {model_name}")
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name, trust_remote_code=True,
dtype=torch.bfloat16 if device == "cuda" else torch.float32,
).to(device)
model.eval()
genes_path = await genes_dir.download()
with open(os.path.join(genes_path, "genes.json")) as f:
data = json.load(f)
species_names = list(data["sequences"].keys())
n = len(species_names)
scores = {}
for i, species in enumerate(species_names):
await flyte.report.replace.aio(_wrap_report(
f"
"
)
for species in species_names:
s = scores[species]
html_parts.append(
f'
{species}
{s["common_name"]}
'
f'
{s["length"]}bp
{s["gc_content"]:.1%}
'
f'
{s["protein_length"]}aa
'
f'
{s["log_likelihood"]:.2f}
'
)
html_parts.append("
")
html_parts.append('
')
html_parts.append(_make_bar_chart(
species_names,
{"Log-Likelihood": [scores[s]["log_likelihood"] for s in species_names]},
title="Carbon Log-Likelihood per Species",
value_format=".1f",
))
html_parts.append("
")
await flyte.report.replace.aio(_wrap_report("\n".join(html_parts)), do_flush=True)
result = {
"gene_name": data["gene_name"],
"description": data["description"],
"species": species_names,
"scores": scores,
}
return json.dumps(result)
# ------------------------------------------------------------------
# Task 3: Align sequences and compute similarity
# ------------------------------------------------------------------
@cpu_env.task(report=True)
async def align_and_compare(
scores_json: str,
genes_dir: flyte.io.Dir,
) -> str:
"""Align sequences with Needleman-Wunsch and compute pairwise identity.
Translates DNA to protein, builds DNA and protein identity matrices,
and generates phylogenetic trees from sequence divergence.
"""
scores_data = json.loads(scores_json)
species_names = scores_data["species"]
scores = scores_data["scores"]
gene_name = scores_data["gene_name"]
n = len(species_names)
genes_path = await genes_dir.download()
with open(os.path.join(genes_path, "genes.json")) as f:
data = json.load(f)
await flyte.report.replace.aio(_wrap_report(
f"
{gene_name} - Sequence Alignment
"
f"
Aligning {n} species with Needleman-Wunsch...
"
), do_flush=True)
# Pairwise DNA identity matrix
identity_matrix = []
for sp1 in species_names:
row = []
for sp2 in species_names:
dna1 = data["sequences"][sp1]["dna"]
dna2 = data["sequences"][sp2]["dna"]
identity = _sequence_identity(dna1, dna2)
row.append(round(identity, 4))
identity_matrix.append(row)
# Pairwise protein identity matrix
protein_matrix = []
for sp1 in species_names:
row = []
for sp2 in species_names:
identity = _sequence_identity(scores[sp1]["protein"], scores[sp2]["protein"])
row.append(round(identity, 4))
protein_matrix.append(row)
# Average pairwise identities (exclude diagonal)
dna_pairs = [identity_matrix[i][j] for i in range(n) for j in range(i + 1, n)]
prot_pairs = [protein_matrix[i][j] for i in range(n) for j in range(i + 1, n)]
avg_dna = sum(dna_pairs) / len(dna_pairs) if dna_pairs else 0
avg_prot = sum(prot_pairs) / len(prot_pairs) if prot_pairs else 0
# Most/least similar pair
best_pair = max(range(len(dna_pairs)), key=lambda k: dna_pairs[k])
worst_pair = min(range(len(dna_pairs)), key=lambda k: dna_pairs[k])
pair_indices = [(i, j) for i in range(n) for j in range(i + 1, n)]
best_sp = f"{species_names[pair_indices[best_pair][0]]}-{species_names[pair_indices[best_pair][1]]}"
worst_sp = f"{species_names[pair_indices[worst_pair][0]]}-{species_names[pair_indices[worst_pair][1]]}"
# Report
html_parts = [
f"
{gene_name} - Sequence Alignment
",
f'
Pairwise alignment using Needleman-Wunsch (match=2, mismatch=-1, gap=-2). '
f"Identity is computed as matches / aligned length from the optimal global alignment.
")
# DNA vs Protein conservation comparison
html_parts.append('
')
html_parts.append(_make_bar_chart(
species_names,
{
"DNA vs Human": [identity_matrix[0][j] for j in range(n)],
"Protein vs Human": [protein_matrix[0][j] for j in range(n)],
},
title=f"Conservation vs {species_names[0]} (DNA and Protein)",
value_format=".0%",
))
html_parts.append("
")
await flyte.report.replace.aio(_wrap_report("\n".join(html_parts)), do_flush=True)
result = {
"gene_name": gene_name,
"description": scores_data["description"],
"species": species_names,
"scores": scores,
"dna_identity_matrix": identity_matrix,
"protein_identity_matrix": protein_matrix,
}
return json.dumps(result)
# ------------------------------------------------------------------
# Task 4: Fold proteins with ESMFold
# ------------------------------------------------------------------
@gpu_env.task(report=True)
async def fold_proteins(
comparison_json: str,
max_length: int = 400,
) -> str:
"""Fold each species' translated protein with ESMFold for 3D comparison.
Returns PDB strings and pLDDT confidence scores for each species.
"""
import torch
import numpy as np
from transformers import AutoTokenizer, EsmForProteinFolding
comparison = json.loads(comparison_json)
species_names = comparison["species"]
scores = comparison["scores"]
log.info("Loading ESMFold model...")
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("facebook/esmfold_v1")
model = EsmForProteinFolding.from_pretrained("facebook/esmfold_v1", low_cpu_mem_usage=True)
model = model.to(device)
model.eval()
structure_data = {}
n = len(species_names)
for idx, species in enumerate(species_names):
protein = scores[species]["protein"]
if len(protein) > max_length:
log.info(f"Skipping {species} ({len(protein)} aa > {max_length} max)")
continue
log.info(f"ESMFold [{idx + 1}/{n}]: {species} ({len(protein)} aa)")
await flyte.report.replace.aio(_wrap_report(
f"
"
), do_flush=True)
inputs = tokenizer(protein, return_tensors="pt", add_special_tokens=False).to(device)
with torch.no_grad():
outputs = model(**inputs)
pdb_str = _outputs_to_pdb(outputs, protein)
plddt_raw = outputs.plddt[0].cpu().numpy()
if plddt_raw.ndim == 2:
plddt_raw = plddt_raw[-1]
plddt = plddt_raw.flatten()[:len(protein)]
if plddt.max() <= 1.0:
plddt = plddt * 100
plddt_mean = float(np.mean(plddt))
structure_data[species] = {
"pdb_str": pdb_str,
"plddt_mean": round(plddt_mean, 1),
"plddt_per_residue": [round(float(v), 1) for v in plddt[:len(protein)]],
"protein_length": len(protein),
}
log.info(f" → mean pLDDT: {plddt_mean:.1f}")
# Report with 3D viewers
n_folded = len(structure_data)
avg_plddt = sum(d["plddt_mean"] for d in structure_data.values()) / n_folded if n_folded else 0
threeDmol_script = ''
stats_html = f"""
ESMFold - Cross-Species Structure Comparison
ESMFold predicts 3D structure directly from amino acid sequence.
Comparing structures across species reveals which parts of the protein are
structurally conserved (functional core) vs divergent (surface loops, species-specific adaptations).
',
]
# Key metrics
# Average pairwise identity (exclude diagonal)
n = len(species)
dna_pairs = [dna_matrix[i][j] for i in range(n) for j in range(i + 1, n)]
protein_pairs = [protein_matrix[i][j] for i in range(n) for j in range(i + 1, n)]
avg_dna_id = sum(dna_pairs) / len(dna_pairs) if dna_pairs else 0
avg_protein_id = sum(protein_pairs) / len(protein_pairs) if protein_pairs else 0
avg_plddt = sum(d["plddt_mean"] for d in structures.values()) / len(structures) if structures else 0
html_parts.append('
')
html_parts.append(f'
{n}
Species
')
html_parts.append(f'
{avg_dna_id:.0%}
Avg DNA Identity
')
html_parts.append(f'
{avg_protein_id:.0%}
Avg Protein Identity
')
html_parts.append(f'
{avg_plddt:.1f}
Avg pLDDT
')
html_parts.append(f'
{len(structures)}
Structures Folded
')
html_parts.append("
")
# Full comparison table
html_parts.append("
Per-Species Detail
")
html_parts.append(
"
Species
Scientific Name
DNA (bp)
"
"
Protein (aa)
GC%
Carbon LL
pLDDT
"
)
for sp in species:
s = scores[sp]
plddt = structures.get(sp, {}).get("plddt_mean", "N/A")
plddt_str = f"{plddt:.1f}" if isinstance(plddt, float) else plddt
html_parts.append(
f'
{sp}
{s["common_name"]}
'
f'
{s["length"]}
{s["protein_length"]}
'
f'
{s["gc_content"]:.1%}
{s["log_likelihood"]:.2f}
'
f'
{plddt_str}
'
)
html_parts.append("
")
# GC content comparison
html_parts.append('
')
html_parts.append(_make_bar_chart(
species,
{"GC Content": [scores[s]["gc_content"] for s in species]},
title="GC Content Across Species",
value_format=".2f",
))
html_parts.append("
")
# DNA phylogenetic tree
html_parts.append("
Phylogenetic Relationships
")
html_parts.append(
'
'
"Trees built from pairwise sequence identity using UPGMA clustering. "
"Species that diverged more recently cluster together. DNA and protein trees "
"may differ when synonymous mutations dominate."
"
All 4 pipeline stages completed. View individual task reports for DNA/protein
identity heatmaps, phylogenetic trees, interactive 3D protein structures with
pLDDT confidence, Carbon log-likelihood scores, and evolutionary analysis.
"""
await flyte.report.replace.aio(_wrap_report(final_html), do_flush=True)
log.info("Pipeline complete.")
return comparison_json, structures_json
# {{/docs-fragment pipeline}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(pipeline)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/genomic_gene_comparison/genomic_gene_comparison.py*
Dependencies are declared at the top of the file using the `uv` script style:
```
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flyte>=2.4.0",
# "torch>=2.9.0",
# "transformers>=4.49.0",
# "accelerate>=0.34.0",
# "numpy",
# ]
# ///
```
## Orchestrate the pipeline
The top-level `pipeline` task chains four stages: load genes, Carbon scoring, sequence alignment, ESMFold folding, and a cross-species summary report.
```
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flyte>=2.4.0",
# "torch>=2.9.0",
# "transformers>=4.49.0",
# "accelerate>=0.34.0",
# "numpy",
# ]
# main = "pipeline"
# params = ""
# ///
import json
import logging
import math
import os
import tempfile
import flyte
import flyte.io
import flyte.report
# {{docs-fragment env}}
main_img = flyte.Image.from_uv_script(__file__, name="genomic-gene-comparison", pre=True)
gpu_env = flyte.TaskEnvironment(
name="genomic-gene-comparison-gpu",
image=main_img,
resources=flyte.Resources(cpu=4, memory="32Gi", gpu=1),
)
cpu_env = flyte.TaskEnvironment(
name="genomic-gene-comparison-cpu",
image=main_img,
resources=flyte.Resources(cpu=2, memory="8Gi"),
depends_on=[gpu_env],
)
# {{/docs-fragment env}}
logging.basicConfig(level=logging.WARNING, format="%(message)s", force=True)
log = logging.getLogger(__name__)
log.setLevel(logging.INFO)
# ------------------------------------------------------------------
# Homologous gene sets - same gene across species
# ------------------------------------------------------------------
# Full-length coding sequences from NCBI RefSeq (stop codon excluded).
GENE_SETS = {
"insulin": {
"gene_name": "Insulin",
"description": "Insulin regulates blood sugar in all vertebrates. Highly conserved across 500M+ years of evolution - even fish insulin can lower blood sugar in humans. Comparing across species reveals which regions are functionally essential (conserved) vs free to drift.",
"sequences": {
"Human": {
"dna": "ATGGCCCTGTGGATGCGCCTCCTGCCCCTGCTGGCGCTGCTGGCCCTCTGGGGACCTGACCCAGCCGCAGCCTTTGTGAACCAACACCTGTGCGGCTCACACCTGGTGGAAGCTCTCTACCTAGTGTGCGGGGAACGAGGCTTCTTCTACACACCCAAGACCCGCCGGGAGGCAGAGGACCTGCAGGTGGGGCAGGTGGAGCTGGGCGGGGGCCCTGGTGCAGGCAGCCTGCAGCCCTTGGCCCTGGAGGGGTCCCTGCAGAAGCGTGGCATTGTGGAACAATGCTGTACCAGCATCTGCTCCCTCTACCAGCTGGAGAACTACTGCAAC",
"common_name": "Homo sapiens",
},
"Mouse": {
"dna": "ATGGCCCTGTGGATGCGCTTCCTGCCCCTGCTGGCCCTGCTCTTCCTCTGGGAGTCCCACCCCACCCAGGCTTTTGTCAAGCAGCACCTTTGTGGTTCCCACCTGGTGGAGGCTCTCTACCTGGTGTGTGGGGAGCGTGGCTTCTTCTACACACCCATGTCCCGCCGTGAAGTGGAGGACCCACAAGTGGCACAACTGGAGCTGGGTGGAGGCCCGGGAGCAGGTGACCTTCAGACCTTGGCACTGGAGGTGGCCCAGCAGAAGCGTGGCATTGTAGATCAGTGCTGCACCAGCATCTGCTCCCTCTACCAGCTGGAGAACTACTGCAAC",
"common_name": "Mus musculus",
},
"Chicken": {
"dna": "ATGGCTCTCTGGATCCGATCACTGCCTCTTCTGGCTCTCCTTGTCTTTTCTGGCCCTGGAACCAGCTATGCAGCTGCCAACCAGCACCTCTGTGGCTCCCACTTGGTGGAGGCTCTCTACCTGGTGTGTGGAGAGCGTGGCTTCTTCTACTCCCCCAAAGCCCGACGGGATGTCGAGCAGCCCCTAGTGAGCAGTCCCTTGCGTGGCGAGGCAGGAGTGCTGCCTTTCCAGCAGGAGGAATACGAGAAAGTCAAGCGAGGGATTGTTGAGCAATGCTGCCATAACACGTGTTCCCTCTACCAACTGGAGAACTACTGCAAC",
"common_name": "Gallus gallus",
},
"Zebrafish": {
"dna": "ATGGCAGTGTGGCTTCAGGCTGGTGCTCTGTTGGTCCTGTTGGTCGTGTCCAGTGTAAGCACTAACCCAGGCACACCGCAGCACCTGTGTGGATCTCATCTGGTCGATGCCCTTTATCTGGTCTGTGGCCCAACAGGCTTCTTCTACAACCCCAAGAGAGACGTTGAGCCCCTTCTGGGTTTCCTTCCTCCTAAATCTGCCCAGGAAACTGAGGTGGCTGACTTTGCATTTAAAGATCATGCCGAGCTGATAAGGAAGAGAGGCATTGTAGAGCAGTGCTGCCACAAACCCTGCAGCATCTTTGAGCTGCAGAACTACTGTAAC",
"common_name": "Danio rerio",
},
"Frog": {
"dna": "ATGGCTCTATGGATGCAGTGTCTGCCCCTGGTTCTTGTCCTCTTTTTCTCTACACCCAACACCGAAGCTCTAGTTAACCAGCACTTGTGTGGGTCTCACCTGGTAGAAGCCCTGTACTTAGTATGTGGGGATCGAGGCTTCTTCTACTACCCTAAGGTCAAACGGGACATGGAACAAGCACTTGTCAGTGGACCCCAGGATAATGAGTTGGATGGAATGCAGCTCCAGCCTCAGGAGTATCAGAAAATGAAGAGGGGGATTGTGGAGCAATGTTGCCACAGCACATGTTCTCTCTTCCAGCTGGAGAGTTACTGCAAC",
"common_name": "Xenopus laevis",
},
"Cow": {
"dna": "ATGGCCCTGTGGACACGCCTGGCGCCCCTGCTGGCCCTGCTGGCGCTCTGGGCCCCCGCCCCGGCCCGCGCCTTCGTCAACCAGCATCTGTGTGGCTCCCACCTGGTGGAGGCGCTGTACCTGGTGTGCGGAGAGCGCGGCTTCTTCTACACGCCCAAGGCCCGCCGGGAGGTGGAGGGCCCCCAGGTGGGGGCGCTGGAGCTGGCCGGAGGCCCGGGCGCGGGCGGCCTGGAGGGGCCCCCGCAGAAGCGTGGCATCGTGGAGCAGTGCTGTGCCAGCGTCTGCTCGCTCTACCAGCTGGAGAACTACTGTAAC",
"common_name": "Bos taurus",
},
},
},
"hemoglobin": {
"gene_name": "Hemoglobin Beta",
"description": "Beta-globin carries oxygen from lungs to tissues. The most studied gene in molecular evolution - sequence differences power the 'molecular clock' hypothesis. Sickle cell mutation (E6V) in humans shows how a single base change creates devastating disease.",
"sequences": {
"Human": {
"dna": "ATGGTGCATCTGACTCCTGAGGAGAAGTCTGCCGTTACTGCCCTGTGGGGCAAGGTGAACGTGGATGAAGTTGGTGGTGAGGCCCTGGGCAGGCTGCTGGTGGTCTACCCTTGGACCCAGAGGTTCTTTGAGTCCTTTGGGGATCTGTCCACTCCTGATGCTGTTATGGGCAACCCTAAGGTGAAGGCTCATGGCAAGAAAGTGCTCGGTGCCTTTAGTGATGGCCTGGCTCACCTGGACAACCTCAAGGGCACCTTTGCCACACTGAGTGAGCTGCACTGTGACAAGCTGCACGTGGATCCTGAGAACTTCAGGCTCCTGGGCAACGTGCTGGTCTGTGTGCTGGCCCATCACTTTGGCAAAGAATTCACCCCACCAGTGCAGGCTGCCTATCAGAAAGTGGTGGCTGGTGTGGCTAATGCCCTGGCCCACAAGTATCAC",
"common_name": "Homo sapiens",
},
"Mouse": {
"dna": "ATGGTGCACCTGACTGATGCTGAGAAGGCTGCTGTCTCTGGCCTGTGGGGAAAGGTGAACGCCGATGAAGTTGGTGGTGAGGCCCTGGGCAGGCTGCTGGTTGTCTACCCTTGGACCCAGCGGTACTTTGATAGCTTTGGAGACCTATCCTCTGCCTCTGCTATCATGGGTAATGCCAAAGTGAAGGCCCATGGCAAGAAAGTGATAACTGCCTTTAACGATGGCCTGAATCACTTGGACAGCCTCAAGGGCACCTTTGCCAGCCTCAGTGAGCTCCACTGTGACAAGCTGCATGTGGATCCTGAGAACTTCAGGCTCCTGGGCAATATGATCGTGATTGTGCTGGGCCACCACCTGGGCAAGGATTTCACCCCCGCTGCACAGGCTGCCTTCCAGAAGGTGGTGGCTGGAGTGGCTGCTGCCCTGGCTCACAAGTACCAC",
"common_name": "Mus musculus",
},
"Chicken": {
"dna": "ATGGTGCACTGGACTGCTGAGGAGAAGCAGCTCATCACCGGCCTCTGGGGCAAGGTCAATGTGGCCGAATGTGGGGCTGAAGCCCTGGCCAGGCTGCTGATCGTCTACCCCTGGACCCAGAGGTTCTTTGCGTCCTTTGGGAACCTCTCCAGCCCCACTGCCATCCTTGGCAACCCCATGGTCCGCGCCCATGGCAAGAAAGTGCTCACCTCCTTTGGGGATGCTGTGAAGAACCTGGACAACATCAAGAACACCTTCTCCCAACTGTCCGAACTGCATTGTGACAAGCTGCATGTGGACCCCGAGAACTTCAGGCTCCTGGGTGACATCCTCATCATTGTCCTGGCCGCCCACTTCAGCAAGGACTTCACTCCTGAATGCCAGGCTGCCTGGCAGAAGCTGGTCCGCGTGGTGGCCCATGCCCTGGCTCGCAAGTACCAC",
"common_name": "Gallus gallus",
},
"Zebrafish": {
"dna": "ATGGTTGAGTGGACAGATGCCGAGCGCACAGCCATCCTTGGCCTGTGGGGAAAGCTCAATATCGATGAAATCGGACCTCAGGCCCTATCCAGATGTCTGATCGTGTATCCCTGGACTCAGAGATATTTCGCCACATTCGGCAACCTGTCAAGCCCCGCTGCGATCATGGGTAACCCCAAAGTGGCAGCTCATGGGAGGACTGTGATGGGAGGTCTTGAGAGAGCCATCAAGAACATGGACAACGTCAAGAACACCTATGCCGCCCTCAGTGTGATGCACTCTGAGAAACTGCATGTGGATCCCGACAACTTCAGGCTTCTCGCTGATTGCATCACCGTTTGCGCTGCCATGAAGTTCGGCCAAGCTGGTTTCAATGCTGATGTCCAGGAGGCCTGGCAGAAGTTTCTGGCTGTGGTCGTTTCTGCTCTGTGCAGACAGTACCAC",
"common_name": "Danio rerio",
},
"Frog": {
"dna": "ATGGTTCATTGGACAGCTGAAGAGAAGGCCGCCATCACCTCTGTGTGGCAGGAGGTCAACCAGGAGCAAGATGGCCATGATGCACTCACAAGGCTGCTGGTTGTGTACCCCTGGACCCAGAGATACTTCAGCAGTTTTGGAAATCTCGGTAATGCCACAGCTATTGCTGGAAATGTCAAGGTGCGTGCCCATGGCAAGAAGGTTCTTTCAGCTGTTGGTGATGCCATCGCCCATCTTGACAACGTGAAGGGAACTCTCCATGACCTCAGTGTGGTCCACGCCTTCAAGCTCTATGTGGATCCTGAGAACTTCAAGCGTCTTGGTGAAGTTCTGGTCATTGTCTTGGCTTCCAAACTGGGATCAGCCTTTACTCCTCAAGTCCAGGGAGCCTGGGAGAAATTTGTTGCTGTTCTGGTTGATGCCCTCAGCCAAGGATACAAC",
"common_name": "Xenopus laevis",
},
"Cow": {
"dna": "ATGCTGACTGCTGAGGAGAAGGCTGCCGTCACCGCCTTTTGGGGCAAGGTGAAAGTGGATGAAGTTGGTGGTGAGGCCCTGGGCAGGCTGCTGGTTGTCTACCCCTGGACTCAGAGGTTCTTTGAGTCCTTTGGGGACTTGTCCACTGCTGATGCTGTTATGAACAACCCTAAGGTGAAGGCCCATGGCAAGAAGGTGCTAGATTCCTTTAGTAATGGCATGAAGCATCTCGATGACCTCAAGGGCACCTTTGCTGCGCTGAGTGAGCTGCACTGTGATAAGCTGCATGTGGATCCTGAGAACTTCAAGCTCCTGGGCAACGTGCTAGTGGTTGTGCTGGCTCGCAATTTTGGCAAGGAATTCACCCCGGTGCTGCAGGCTGACTTTCAGAAGGTGGTGGCTGGTGTGGCCAATGCCCTGGCCCACAGATATCAT",
"common_name": "Bos taurus",
},
},
},
"p53": {
"gene_name": "p53 (TP53)",
"description": "The 'guardian of the genome' - p53 detects DNA damage and triggers repair or cell death. Mutated in >50% of human cancers. Elephants have 20 copies of p53 (humans have 1), which may explain their extremely low cancer rates despite their size (Peto's paradox).",
"sequences": {
"Human": {
"dna": "ATGGAGGAGCCGCAGTCAGATCCTAGCGTCGAGCCCCCTCTGAGTCAGGAAACATTTTCAGACCTATGGAAACTACTTCCTGAAAACAACGTTCTGTCCCCCTTGCCGTCCCAAGCAATGGATGATTTGATGCTGTCCCCGGACGATATTGAACAATGGTTCACTGAAGACCCAGGTCCAGATGAAGCTCCCAGAATGCCAGAGGCTGCTCCCCCCGTGGCCCCTGCACCAGCAGCTCCTACACCGGCGGCCCCTGCACCAGCCCCCTCCTGGCCCCTGTCATCTTCTGTCCCTTCCCAGAAAACCTACCAGGGCAGCTACGGTTTCCGTCTGGGCTTCTTGCATTCTGGGACAGCCAAGTCTGTGACTTGCACGTACTCCCCTGCCCTCAACAAGATGTTTTGCCAACTGGCCAAGACCTGCCCTGTGCAGCTGTGGGTTGATTCCACACCCCCGCCCGGCACCCGCGTCCGCGCCATGGCCATCTACAAGCAGTCACAGCACATGACGGAGGTTGTGAGGCGCTGCCCCCACCATGAGCGCTGCTCAGATAGCGATGGTCTGGCCCCTCCTCAGCATCTTATCCGAGTGGAAGGAAATTTGCGTGTGGAGTATTTGGATGACAGAAACACTTTTCGACATAGTGTGGTGGTGCCCTATGAGCCGCCTGAGGTTGGCTCTGACTGTACCACCATCCACTACAACTACATGTGTAACAGTTCCTGCATGGGCGGCATGAACCGGAGGCCCATCCTCACCATCATCACACTGGAAGACTCCAGTGGTAATCTACTGGGACGGAACAGCTTTGAGGTGCGTGTTTGTGCCTGTCCTGGGAGAGACCGGCGCACAGAGGAAGAGAATCTCCGCAAGAAAGGGGAGCCTCACCACGAGCTGCCCCCAGGGAGCACTAAGCGAGCACTGCCCAACAACACCAGCTCCTCTCCCCAGCCAAAGAAGAAACCACTGGATGGAGAATATTTCACCCTTCAGATCCGTGGGCGTGAGCGCTTCGAGATGTTCCGAGAGCTGAATGAGGCCTTGGAACTCAAGGATGCCCAGGCTGGGAAGGAGCCAGGGGGGAGCAGGGCTCACTCCAGCCACCTGAAGTCCAAAAAGGGTCAGTCTACCTCCCGCCATAAAAAACTCATGTTCAAGACAGAAGGGCCTGACTCAGAC",
"common_name": "Homo sapiens",
},
"Mouse": {
"dna": "ATGACTGCCATGGAGGAGTCACAGTCGGATATCAGCCTCGAGCTCCCTCTGAGCCAGGAGACATTTTCAGGCTTATGGAAACTACTTCCTCCAGAAGATATCCTGCCATCACCTCACTGCATGGACGATCTGTTGCTGCCCCAGGATGTTGAGGAGTTTTTTGAAGGCCCAAGTGAAGCCCTCCGAGTGTCAGGAGCTCCTGCAGCACAGGACCCTGTCACCGAGACCCCTGGGCCAGTGGCCCCTGCCCCAGCCACTCCATGGCCCCTGTCATCTTTTGTCCCTTCTCAAAAAACTTACCAGGGCAACTATGGCTTCCACCTGGGCTTCCTGCAGTCTGGGACAGCCAAGTCTGTTATGTGCACGTACTCTCCTCCCCTCAATAAGCTATTCTGCCAGCTGGCGAAGACGTGCCCTGTGCAGTTGTGGGTCAGCGCCACACCTCCAGCTGGGAGCCGTGTCCGCGCCATGGCCATCTACAAGAAGTCACAGCACATGACGGAGGTCGTGAGACGCTGCCCCCACCATGAGCGCTGCTCCGATGGTGATGGCCTGGCTCCTCCCCAGCATCTTATCCGGGTGGAAGGAAATTTGTATCCCGAGTATCTGGAAGACAGGCAGACTTTTCGCCACAGCGTGGTGGTACCTTATGAGCCACCCGAGGCCGGCTCTGAGTATACCACCATCCACTACAAGTACATGTGTAATAGCTCCTGCATGGGGGGCATGAACCGCCGACCTATCCTTACCATCATCACACTGGAAGACTCCAGTGGGAACCTTCTGGGACGGGACAGCTTTGAGGTTCGTGTTTGTGCCTGCCCTGGGAGAGACCGCCGTACAGAAGAAGAAAATTTCCGCAAAAAGGAAGTCCTTTGCCCTGAACTGCCCCCAGGGAGCGCAAAGAGAGCGCTGCCCACCTGCACAAGCGCCTCTCCCCCGCAAAAGAAAAAACCACTTGATGGAGAGTATTTCACCCTCAAGATCCGCGGGCGTAAACGCTTCGAGATGTTCCGGGAGCTGAATGAGGCCTTAGAGTTAAAGGATGCCCATGCTACAGAGGAGTCTGGAGACAGCAGGGCTCACTCCAGCTACCTGAAGACCAAGAAGGGCCAGTCTACTTCCCGCCATAAAAAAACAATGGTCAAGAAAGTGGGGCCTGACTCAGAC",
"common_name": "Mus musculus",
},
"Chicken": {
"dna": "ATGGCGGAGGAGATGGAACCATTGCTGGAACCCACTGAGGTCTTCATGGACCTCTGGAGCATGCTCCCCTATAGCATGCAACAGCTGCCCCTCCCTGAGGATCACAGCAACTGGCAGGAGCTGAGCCCCCTGGAACCCAGCGACCCCCCCCCACCACCGCCACCACCACCTCTGCCATTGGCCGCCGCCGCCCCCCCCCCATTAAACCCCCCCACCCCCCCCCGCGCTGCCCCCTCCCCGGTGGTCCCATCCACGGAGGATTATGGGGGGGACTTCGACTTCCGGGTGGGGTTCGTGGAGGCGGGCACAGCCAAATCGGTCACCTGCACTTACTCCCCGGTGCTGAATAAGGTCTATTGCCGCCTGGCCAAGCCGTGCCCGGTGCAGGTGAGGGTGGGGGTGGCGCCCCCCCCCGGTTCCTCCCTCCGCGCCGTGGCCGTCTATAAGAAATCAGAGCACGTGGCCGAAGTGGTGCGGCGCTGCCCCCACCACGAGCGCTGCGGGGGGGGCACCGACGGCCTGGCCCCCGCACAGCACCTCATCCGGGTGGAGGGGAACCCCCAGGCGCGTTACCACGACGACGAGACCACCAAACGGCACAGCGTCGTCGTCCCCTATGAGCCCCCCGAGGTGGGCTCTGACTGTACCACGGTGCTGTACAACTTCATGTGCAACAGTTCCTGCATGGGGGGGATGAACCGCCGCCCCATCCTCACCATCCTTACACTGGAGGGGCCGGGGGGGCAGCTGTTGGGGCGGCGCTGCTTCGAGGTGCGCGTGTGCGCATGTCCGGGGAGGGACCGCAAGATCGAGGAGGAGAACTTCCGCAAGAGGGGCGGGGCCGGGGGCGTGGCTAAGCGAGCCATGTCGCCCCCAACCGAAGCCCCCGAGCCCCCCAAGAAGCGCGTGCTGAACCCCGACAATGAGATATTCTACCTGCAGGTGCGCGGGCGCCGCCGCTATGAGATGCTGAAGGAGATCAATGAGGCGCTGCAGCTCGCCGAGGGGGGGTCCGCACCGCGGCCTTCCAAAGGCCGCCGTGTGAAGGTGGAGGGACCCCAACCCAGCTGCGGGAAGAAACTGCTGCAAAAAGGCTCGGAC",
"common_name": "Gallus gallus",
},
"Zebrafish": {
"dna": "ATGGCGCAAAACGACAGCCAAGAGTTCGCGGAGCTCTGGGAGAAGAATTTGATTATTCAGCCCCCAGGTGGTGGCTCTTGCTGGGACATCATTAATGATGAGGAGTACTTGCCGGGATCGTTTGACCCCAATTTTTTTGAAAATGTGCTTGAAGAACAGCCTCAGCCATCCACTCTCCCACCAACATCCACTGTTCCGGAGACAAGCGACTATCCCGGCGATCATGGATTTAGGCTCAGGTTCCCGCAGTCTGGCACAGCAAAATCTGTAACTTGCACTTATTCACCGGACCTGAATAAACTCTTCTGTCAGCTGGCAAAAACTTGCCCCGTTCAAATGGTGGTGGACGTTGCCCCTCCACAGGGCTCCGTGGTTCGAGCCACTGCCATCTATAAGAAGTCCGAGCATGTGGCTGAAGTGGTCCGCAGATGCCCCCATCATGAGCGAACCCCGGATGGAGATAACTTGGCGCCTGCTGGTCATTTGATAAGAGTGGAGGGCAATCAGCGAGCAAATTACAGGGAAGATAACATCACTTTAAGGCATAGTGTTTTTGTCCCATATGAAGCACCACAGCTTGGTGCTGAATGGACAACTGTGCTACTAAACTACATGTGCAATAGCAGCTGCATGGGGGGGATGAACCGCAGGCCCATCCTCACAATCATCACTCTGGAGACTCAGGAAGGTCAGTTGCTGGGCCGGAGGTCTTTTGAGGTGCGTGTGTGTGCATGTCCAGGCAGAGACAGGAAAACTGAGGAGAGCAACTTCAAGAAAGACCAAGAGACCAAAACCATGGCCAAAACCACCACTGGGACCAAACGTAGTTTGGTGAAAGAATCTTCTTCAGCTACATTACGACCTGAGGGGAGCAAAAAGGCCAAGGGCTCCAGCAGCGATGAGGAGATCTTTACCCTGCAGGTGAGGGGCAGGGAGCGTTATGAAATTTTAAAGAAATTGAACGACAGTCTGGAGTTAAGTGATGTGGTGCCTGCCTCAGATGCTGAAAAGTATCGTCAGAAATTCATGACAAAAAACAAAAAAGAGAATCGTGAATCATCTGAGCCCAAACAGGGAAAGAAGCTGATGGTGAAGGACGAAGGAAGAAGCGACTCTGAT",
"common_name": "Danio rerio",
},
"Elephant": {
"dna": "ATGGAGGAGCCCCAGTCAGATCTCAGCACCGAGCTCCCTCTGAGTCAAGAGACGTTTTCATACTTATGGGAACTCCTTCCTGAGAATCCGGTTCTGTCCCCCACACTACCCCCGGCAGTGGAGGTCATGGACGATCTGCTACTCTCAGAAGACACTGCAAACTGGCTAGAAAGCCAAGTTGAGGCTCAGGGAATGTCCACAACCCCTGCACCAGCCACCCCTACACCGGTGGCCCCCGCACCAGCCACCTCCTGGACCCTGTCATCTTCCGTCCCTTCCCAAAAGACCTACCCTGGCACCTATGGTTTCCGTCTGGGCTTCCTACATTCTGGGACAGCCAAGTCCGTCACCTGCACGTACTCCCCTGACCTTAACAAGCTGTTTTGCCAGCTGGCAAAAACCTGCCCAGTGCAGCTGTGGGTCGCCTCACCACCCCCGCCCGGCACCCGTGTTCGCACCATGGCCATCTACAAGAAGTCAGAGCATATGACGGAGGTCGTCAAGCGCTGCCCCCACCATGAGCGCTGCTCTGACTCTAGCGATGGCCTGGCCCCTCCTCAGCACCTCATCCGGGTGGAAGGAAACCTGCGTGCTGAGTATCTGGAGGACAGCATCACTCTCCGACACAGTGTGGTGGTGCCCTACGAGCCGCCCGAGGTTGGGTCTGACTGTACCACCATCCACTTCAACTTCATGTGTAACAGCTCCTGCATGGGGGGCATGAACCGGCGGCCCATCCTCACCATCATCACACTGGAAGACTCCAGTGGTAATCTGCTGGGACGTAACAGCTTTGAGGTGCGCATTTGTGCCTGTCCTGGAAGAGACAGACGTACAGAAGAAGAAAATTTCCACAAGAAGGGAGAGCCTTGCCCAGAGCCGCCACCCCCTGGGAGGAGCACTAAGCGAGCACTGCCCACCAACACCAGCTCCTCTACCCAGCCAAAGAAGAAGCCACTGGATGAAGAATATTTCACCCTTCAGATCCGTGGGCGTGAACGCTTCAAGATGTTCCTAGAGCTAAATGAGGCCTTGGAGCTGAAGGATGCCCAGGCTGGGAAGGAGCCAGAGGGGAGCCGGGCTCACTCCAGCCCTTCGAAGTCTAAGAAGGGACAGTCTACCTCCCGCCATAAAAAACCAATGTTCAAGAGAGAGGGACCTGACTCAGAC",
"common_name": "Loxodonta africana",
},
"Dog": {
"dna": "ATGGAGGAGTCGCAGTCAGAGCTCAATATCGACCCCCCTCTGAGCCAGGAGACATTTTCAGAATTGTGGAACCTGCTTCCTGAAAACAATGTTCTGTCTTCGGAGCTGTGCCCAGCAGTGGATGAGCTGCTGCTCCCAGAGAGCGTCGTGAACTGGCTAGACGAAGACTCAGATGATGCTCCCAGGATGCCAGCCACTTCTGCCCCCACAGCCCCTGGACCGGCCCCCTCGTGGCCCCTATCATCCTCTGTCCCTTCCCCGAAGACCTACCCTGGCACCTATGGGTTCCGTTTGGGGTTCCTGCATTCCGGGACAGCCAAGTCTGTTACTTGGACGTACTCCCCTCTCCTCAACAAGTTGTTTTGCCAGCTGGCGAAGACCTGCCCCGTGCAGCTGTGGGTCAGCTCCCCACCCCCACCCAATACCTGCGTCCGCGCTATGGCCATCTATAAGAAGTCGGAGTTCGTGACCGAGGTTGTGCGGCGCTGCCCCCACCATGAACGCTGCTCTGACAGTAGTGACGGTCTTGCCCCTCCTCAGCATCTCATCCGAGTGGAAGGAAATTTGCGGGCCAAGTACCTGGACGACAGAAACACTTTTCGACACAGTGTGGTGGTGCCTTATGAGCCACCCGAGGTTGGCTCTGACTATACCACCATCCACTACAACTACATGTGTAACAGTTCCTGCATGGGAGGCATGAACCGGCGGCCCATCCTCACTATCATCACCCTGGAAGACTCCAGTGGAAACGTGCTGGGACGCAACAGCTTTGAGGTACGCGTTTGTGCCTGTCCCGGGAGAGACCGCCGGACTGAGGAGGAGAATTTCCACAAGAAGGGGGAGCCTTGTCCTGAGCCACCCCCCGGGAGTACCAAGCGAGCACTGCCTCCCAGCACCAGCTCCTCTCCCCCGCAAAAGAAGAAGCCACTAGATGGAGAATATTTCACCCTTCAGATCCGTGGGCGTGAACGCTATGAGATGTTCAGGAATCTGAATGAAGCCTTGGAGCTGAAGGATGCCCAGAGTGGAAAGGAGCCAGGGGGAAGCAGGGCTCACTCCAGCCACCTGAAGGCAAAGAAGGGGCAATCTACCTCTCGCCATAAAAAACTGATGTTCAAGAGAGAAGGGCTTGACTCAGAC",
"common_name": "Canis lupus familiaris",
},
},
},
}
# Standard genetic code
CODON_TABLE = {
"TTT": "F", "TTC": "F", "TTA": "L", "TTG": "L", "CTT": "L", "CTC": "L",
"CTA": "L", "CTG": "L", "ATT": "I", "ATC": "I", "ATA": "I", "ATG": "M",
"GTT": "V", "GTC": "V", "GTA": "V", "GTG": "V", "TCT": "S", "TCC": "S",
"TCA": "S", "TCG": "S", "CCT": "P", "CCC": "P", "CCA": "P", "CCG": "P",
"ACT": "T", "ACC": "T", "ACA": "T", "ACG": "T", "GCT": "A", "GCC": "A",
"GCA": "A", "GCG": "A", "TAT": "Y", "TAC": "Y", "TAA": "*", "TAG": "*",
"CAT": "H", "CAC": "H", "CAA": "Q", "CAG": "Q", "AAT": "N", "AAC": "N",
"AAA": "K", "AAG": "K", "GAT": "D", "GAC": "D", "GAA": "E", "GAG": "E",
"TGT": "C", "TGC": "C", "TGA": "*", "TGG": "W", "CGT": "R", "CGC": "R",
"CGA": "R", "CGG": "R", "AGT": "S", "AGC": "S", "AGA": "R", "AGG": "R",
"GGT": "G", "GGC": "G", "GGA": "G", "GGG": "G",
}
BASE_COLORS = {"A": "#2ecc71", "T": "#e74c3c", "G": "#f39c12", "C": "#3498db"}
def _translate(dna: str) -> str:
"""Translate DNA to protein in reading frame 0."""
dna = dna.upper()
protein = []
for i in range(0, len(dna) - 2, 3):
codon = dna[i:i + 3]
aa = CODON_TABLE.get(codon, "X")
if aa == "*":
break
protein.append(aa)
return "".join(protein)
def _gc_content(seq: str) -> float:
if not seq:
return 0.0
return sum(1 for b in seq.upper() if b in "GC") / len(seq)
def _sequence_identity(seq1: str, seq2: str, match: int = 2, mismatch: int = -1, gap: int = -2) -> float:
"""Percent identity via Needleman-Wunsch global alignment."""
if not seq1 or not seq2:
return 0.0
n, m = len(seq1), len(seq2)
# Build score matrix
dp = [[0] * (m + 1) for _ in range(n + 1)]
for i in range(1, n + 1):
dp[i][0] = dp[i - 1][0] + gap
for j in range(1, m + 1):
dp[0][j] = dp[0][j - 1] + gap
for i in range(1, n + 1):
for j in range(1, m + 1):
s = match if seq1[i - 1] == seq2[j - 1] else mismatch
dp[i][j] = max(dp[i - 1][j - 1] + s, dp[i - 1][j] + gap, dp[i][j - 1] + gap)
# Traceback to count matches and alignment length
i, j = n, m
matches = 0
aligned = 0
while i > 0 or j > 0:
if i > 0 and j > 0:
s = match if seq1[i - 1] == seq2[j - 1] else mismatch
if dp[i][j] == dp[i - 1][j - 1] + s:
if seq1[i - 1] == seq2[j - 1]:
matches += 1
aligned += 1
i -= 1
j -= 1
continue
if i > 0 and dp[i][j] == dp[i - 1][j] + gap:
aligned += 1
i -= 1
else:
aligned += 1
j -= 1
return matches / aligned if aligned else 0.0
# ------------------------------------------------------------------
# Report styling
# ------------------------------------------------------------------
REPORT_CSS = """
"""
def _wrap_report(html: str) -> str:
return f'{REPORT_CSS}
{html}
'
# ------------------------------------------------------------------
# SVG chart helpers
# ------------------------------------------------------------------
def _make_heatmap(
matrix: list[list[float]],
row_labels: list[str],
col_labels: list[str],
title: str = "",
width: int = 600,
height: int = 500,
value_format: str = ".1f",
color_scale: str = "blue",
) -> str:
"""Generate an SVG heatmap."""
n_rows = len(matrix)
n_cols = len(matrix[0]) if matrix else 0
if not n_rows or not n_cols:
return ""
show_values = n_rows <= 10 and n_cols <= 10
flat = [v for row in matrix for v in row]
v_min = min(flat)
v_max = max(flat)
v_range = v_max - v_min or 1
if color_scale == "blue":
def get_color(v):
t = (v - v_min) / v_range
r = int(255 - t * (255 - 30))
g = int(255 - t * (255 - 58))
b = int(255 - t * (255 - 95))
return f"rgb({r},{g},{b})"
else: # green
def get_color(v):
t = (v - v_min) / v_range
r = int(255 - t * (255 - 6))
g = int(255 - t * (255 - 95))
b = int(255 - t * (255 - 70))
return f"rgb({r},{g},{b})"
ml = max(80, max(len(l) for l in row_labels) * 7 + 10) if row_labels else 80
mr = 20
mt = 80
mb = 20
cw = width - ml - mr
ch = height - mt - mb
cell_w = cw / n_cols
cell_h = ch / n_rows
svg = [
f'")
return "\n".join(svg)
def _make_dendrogram(
names: list[str],
matrix: list[list[float]],
title: str = "",
width: int = 700,
height: int = 350,
color: str = "#2563eb",
) -> str:
"""Generate an SVG dendrogram from a similarity matrix using UPGMA."""
n = len(names)
if n < 2:
return ""
dist = [[1.0 - matrix[i][j] for j in range(n)] for i in range(n)]
clusters = [{"members": [i], "height": 0.0, "left": None, "right": None} for i in range(n)]
active = list(range(n))
while len(active) > 1:
best_d = float("inf")
bi, bj = 0, 1
for ii in range(len(active)):
for jj in range(ii + 1, len(active)):
ci, cj = active[ii], active[jj]
d = 0
count = 0
for mi in clusters[ci]["members"]:
for mj in clusters[cj]["members"]:
d += dist[mi][mj]
count += 1
avg_d = d / count if count else 0
if avg_d < best_d:
best_d = avg_d
bi, bj = ii, jj
ci, cj = active[bi], active[bj]
new_cluster = {
"members": clusters[ci]["members"] + clusters[cj]["members"],
"height": best_d,
"left": clusters[ci],
"right": clusters[cj],
}
clusters.append(new_cluster)
new_idx = len(clusters) - 1
active.pop(bj)
active.pop(bi)
active.append(new_idx)
root = clusters[active[0]]
max_label_len = max((len(n) for n in names), default=0)
ml, mr, mt, mb = max(50, max_label_len * 5 + 10), 30, 40, 80
cw = width - ml - mr
ch = height - mt - mb
max_h = root["height"] or 1
leaf_positions = {}
leaf_counter = [0]
def assign_leaves(node):
if node["left"] is None and node["right"] is None:
leaf_positions[node["members"][0]] = leaf_counter[0]
leaf_counter[0] += 1
else:
if node["left"]:
assign_leaves(node["left"])
if node["right"]:
assign_leaves(node["right"])
assign_leaves(root)
n_leaves = len(leaf_positions)
leaf_spacing = cw / max(n_leaves - 1, 1)
svg = [
f'")
return "\n".join(svg)
def _make_bar_chart(
labels: list[str],
series: dict[str, list[float]],
title: str = "",
colors: list[str] | None = None,
width: int = 700,
height: int = 300,
value_format: str = ".1f",
) -> str:
"""Generate an SVG grouped bar chart."""
if not labels:
return ""
default_colors = ["#2563eb", "#059669", "#f59e0b", "#dc2626", "#7c3aed"]
colors = colors or default_colors
ml, mr, mt, mb = 60, 20, 40, 80
cw = width - ml - mr
ch = height - mt - mb
all_vals = [v for vals in series.values() for v in vals]
y_min = min(all_vals) if all_vals else 0
y_max = max(all_vals) if all_vals else 1
if y_min >= 0:
y_min_plot = 0
y_max_plot = y_max * 1.15 or 1
else:
y_range = y_max - y_min or 1
y_min_plot = y_min - y_range * 0.05
y_max_plot = y_max + y_range * 0.15
n_groups = len(labels)
n_series = len(series)
group_width = cw / n_groups
bar_width = group_width * 0.7 / max(n_series, 1)
gap = group_width * 0.15
def sy(v):
return mt + ch - ((v - y_min_plot) / (y_max_plot - y_min_plot)) * ch
svg = [
f'")
return "\n".join(svg)
def _make_plddt_sparkline(values: list[float], width: int = 400, height: int = 50) -> str:
"""pLDDT sparkline with AlphaFold-style coloring."""
if not values or len(values) < 2:
return ""
pad = 4
cw = width - 2 * pad
ch = height - 2 * pad
seg_w = cw / len(values)
svg = [
f'")
return "\n".join(svg)
def _outputs_to_pdb(outputs, sequence: str) -> str:
"""Convert ESMFold outputs to PDB format string."""
import numpy as np
pos = outputs.positions[0]
if pos.dim() == 4:
pos = pos[-1]
positions = pos.cpu().numpy()
atom_names = ["N", "CA", "C", "O"]
aa_3letter = {
"A": "ALA", "R": "ARG", "N": "ASN", "D": "ASP", "C": "CYS",
"Q": "GLN", "E": "GLU", "G": "GLY", "H": "HIS", "I": "ILE",
"L": "LEU", "K": "LYS", "M": "MET", "F": "PHE", "P": "PRO",
"S": "SER", "T": "THR", "W": "TRP", "Y": "TYR", "V": "VAL",
}
pdb_lines = []
atom_idx = 1
for res_idx, aa in enumerate(sequence):
res_name = aa_3letter.get(aa, "UNK")
for atom_i, atom_name in enumerate(atom_names):
if atom_i >= positions.shape[1]:
break
x, y, z = positions[res_idx, atom_i]
if any(math.isnan(c) for c in (x, y, z)):
continue
pdb_lines.append(
f"ATOM {atom_idx:5d} {atom_name:<3s} {res_name} A{res_idx + 1:4d} "
f"{x:8.3f}{y:8.3f}{z:8.3f} 1.00 0.00 {atom_name[0]:>2s}"
)
atom_idx += 1
pdb_lines.append("END")
return "\n".join(pdb_lines)
# ------------------------------------------------------------------
# Task 1: Load gene set
# ------------------------------------------------------------------
@cpu_env.task()
async def load_genes(
gene_set: str = "insulin",
custom_json: str = "",
) -> flyte.io.Dir:
"""Load a set of homologous genes from different species."""
if custom_json:
data = json.loads(custom_json)
elif gene_set in GENE_SETS:
data = GENE_SETS[gene_set]
else:
available = ", ".join(GENE_SETS.keys())
raise ValueError(f"Unknown gene set '{gene_set}'. Available: {available}")
log.info(f"Loaded gene set: {data['gene_name']} - {len(data['sequences'])} species")
out_dir = tempfile.mkdtemp(prefix="gene_compare_")
with open(os.path.join(out_dir, "genes.json"), "w") as f:
json.dump(data, f)
return await flyte.io.Dir.from_local(out_dir)
# ------------------------------------------------------------------
# Task 2: Score sequences with Carbon
# ------------------------------------------------------------------
@gpu_env.task(report=True)
async def score_sequences(
genes_dir: flyte.io.Dir,
model_name: str = "HuggingFaceBio/Carbon-3B",
) -> str:
"""Score each species' gene with Carbon-3B genomic language model.
Returns per-species log-likelihood scores and sequence metadata.
"""
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
log.info(f"Loading Carbon model: {model_name}")
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name, trust_remote_code=True,
dtype=torch.bfloat16 if device == "cuda" else torch.float32,
).to(device)
model.eval()
genes_path = await genes_dir.download()
with open(os.path.join(genes_path, "genes.json")) as f:
data = json.load(f)
species_names = list(data["sequences"].keys())
n = len(species_names)
scores = {}
for i, species in enumerate(species_names):
await flyte.report.replace.aio(_wrap_report(
f"
"
)
for species in species_names:
s = scores[species]
html_parts.append(
f'
{species}
{s["common_name"]}
'
f'
{s["length"]}bp
{s["gc_content"]:.1%}
'
f'
{s["protein_length"]}aa
'
f'
{s["log_likelihood"]:.2f}
'
)
html_parts.append("
")
html_parts.append('
')
html_parts.append(_make_bar_chart(
species_names,
{"Log-Likelihood": [scores[s]["log_likelihood"] for s in species_names]},
title="Carbon Log-Likelihood per Species",
value_format=".1f",
))
html_parts.append("
")
await flyte.report.replace.aio(_wrap_report("\n".join(html_parts)), do_flush=True)
result = {
"gene_name": data["gene_name"],
"description": data["description"],
"species": species_names,
"scores": scores,
}
return json.dumps(result)
# ------------------------------------------------------------------
# Task 3: Align sequences and compute similarity
# ------------------------------------------------------------------
@cpu_env.task(report=True)
async def align_and_compare(
scores_json: str,
genes_dir: flyte.io.Dir,
) -> str:
"""Align sequences with Needleman-Wunsch and compute pairwise identity.
Translates DNA to protein, builds DNA and protein identity matrices,
and generates phylogenetic trees from sequence divergence.
"""
scores_data = json.loads(scores_json)
species_names = scores_data["species"]
scores = scores_data["scores"]
gene_name = scores_data["gene_name"]
n = len(species_names)
genes_path = await genes_dir.download()
with open(os.path.join(genes_path, "genes.json")) as f:
data = json.load(f)
await flyte.report.replace.aio(_wrap_report(
f"
{gene_name} - Sequence Alignment
"
f"
Aligning {n} species with Needleman-Wunsch...
"
), do_flush=True)
# Pairwise DNA identity matrix
identity_matrix = []
for sp1 in species_names:
row = []
for sp2 in species_names:
dna1 = data["sequences"][sp1]["dna"]
dna2 = data["sequences"][sp2]["dna"]
identity = _sequence_identity(dna1, dna2)
row.append(round(identity, 4))
identity_matrix.append(row)
# Pairwise protein identity matrix
protein_matrix = []
for sp1 in species_names:
row = []
for sp2 in species_names:
identity = _sequence_identity(scores[sp1]["protein"], scores[sp2]["protein"])
row.append(round(identity, 4))
protein_matrix.append(row)
# Average pairwise identities (exclude diagonal)
dna_pairs = [identity_matrix[i][j] for i in range(n) for j in range(i + 1, n)]
prot_pairs = [protein_matrix[i][j] for i in range(n) for j in range(i + 1, n)]
avg_dna = sum(dna_pairs) / len(dna_pairs) if dna_pairs else 0
avg_prot = sum(prot_pairs) / len(prot_pairs) if prot_pairs else 0
# Most/least similar pair
best_pair = max(range(len(dna_pairs)), key=lambda k: dna_pairs[k])
worst_pair = min(range(len(dna_pairs)), key=lambda k: dna_pairs[k])
pair_indices = [(i, j) for i in range(n) for j in range(i + 1, n)]
best_sp = f"{species_names[pair_indices[best_pair][0]]}-{species_names[pair_indices[best_pair][1]]}"
worst_sp = f"{species_names[pair_indices[worst_pair][0]]}-{species_names[pair_indices[worst_pair][1]]}"
# Report
html_parts = [
f"
{gene_name} - Sequence Alignment
",
f'
Pairwise alignment using Needleman-Wunsch (match=2, mismatch=-1, gap=-2). '
f"Identity is computed as matches / aligned length from the optimal global alignment.
")
# DNA vs Protein conservation comparison
html_parts.append('
')
html_parts.append(_make_bar_chart(
species_names,
{
"DNA vs Human": [identity_matrix[0][j] for j in range(n)],
"Protein vs Human": [protein_matrix[0][j] for j in range(n)],
},
title=f"Conservation vs {species_names[0]} (DNA and Protein)",
value_format=".0%",
))
html_parts.append("
")
await flyte.report.replace.aio(_wrap_report("\n".join(html_parts)), do_flush=True)
result = {
"gene_name": gene_name,
"description": scores_data["description"],
"species": species_names,
"scores": scores,
"dna_identity_matrix": identity_matrix,
"protein_identity_matrix": protein_matrix,
}
return json.dumps(result)
# ------------------------------------------------------------------
# Task 4: Fold proteins with ESMFold
# ------------------------------------------------------------------
@gpu_env.task(report=True)
async def fold_proteins(
comparison_json: str,
max_length: int = 400,
) -> str:
"""Fold each species' translated protein with ESMFold for 3D comparison.
Returns PDB strings and pLDDT confidence scores for each species.
"""
import torch
import numpy as np
from transformers import AutoTokenizer, EsmForProteinFolding
comparison = json.loads(comparison_json)
species_names = comparison["species"]
scores = comparison["scores"]
log.info("Loading ESMFold model...")
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("facebook/esmfold_v1")
model = EsmForProteinFolding.from_pretrained("facebook/esmfold_v1", low_cpu_mem_usage=True)
model = model.to(device)
model.eval()
structure_data = {}
n = len(species_names)
for idx, species in enumerate(species_names):
protein = scores[species]["protein"]
if len(protein) > max_length:
log.info(f"Skipping {species} ({len(protein)} aa > {max_length} max)")
continue
log.info(f"ESMFold [{idx + 1}/{n}]: {species} ({len(protein)} aa)")
await flyte.report.replace.aio(_wrap_report(
f"
"
), do_flush=True)
inputs = tokenizer(protein, return_tensors="pt", add_special_tokens=False).to(device)
with torch.no_grad():
outputs = model(**inputs)
pdb_str = _outputs_to_pdb(outputs, protein)
plddt_raw = outputs.plddt[0].cpu().numpy()
if plddt_raw.ndim == 2:
plddt_raw = plddt_raw[-1]
plddt = plddt_raw.flatten()[:len(protein)]
if plddt.max() <= 1.0:
plddt = plddt * 100
plddt_mean = float(np.mean(plddt))
structure_data[species] = {
"pdb_str": pdb_str,
"plddt_mean": round(plddt_mean, 1),
"plddt_per_residue": [round(float(v), 1) for v in plddt[:len(protein)]],
"protein_length": len(protein),
}
log.info(f" → mean pLDDT: {plddt_mean:.1f}")
# Report with 3D viewers
n_folded = len(structure_data)
avg_plddt = sum(d["plddt_mean"] for d in structure_data.values()) / n_folded if n_folded else 0
threeDmol_script = ''
stats_html = f"""
ESMFold - Cross-Species Structure Comparison
ESMFold predicts 3D structure directly from amino acid sequence.
Comparing structures across species reveals which parts of the protein are
structurally conserved (functional core) vs divergent (surface loops, species-specific adaptations).
',
]
# Key metrics
# Average pairwise identity (exclude diagonal)
n = len(species)
dna_pairs = [dna_matrix[i][j] for i in range(n) for j in range(i + 1, n)]
protein_pairs = [protein_matrix[i][j] for i in range(n) for j in range(i + 1, n)]
avg_dna_id = sum(dna_pairs) / len(dna_pairs) if dna_pairs else 0
avg_protein_id = sum(protein_pairs) / len(protein_pairs) if protein_pairs else 0
avg_plddt = sum(d["plddt_mean"] for d in structures.values()) / len(structures) if structures else 0
html_parts.append('
')
html_parts.append(f'
{n}
Species
')
html_parts.append(f'
{avg_dna_id:.0%}
Avg DNA Identity
')
html_parts.append(f'
{avg_protein_id:.0%}
Avg Protein Identity
')
html_parts.append(f'
{avg_plddt:.1f}
Avg pLDDT
')
html_parts.append(f'
{len(structures)}
Structures Folded
')
html_parts.append("
")
# Full comparison table
html_parts.append("
Per-Species Detail
")
html_parts.append(
"
Species
Scientific Name
DNA (bp)
"
"
Protein (aa)
GC%
Carbon LL
pLDDT
"
)
for sp in species:
s = scores[sp]
plddt = structures.get(sp, {}).get("plddt_mean", "N/A")
plddt_str = f"{plddt:.1f}" if isinstance(plddt, float) else plddt
html_parts.append(
f'
{sp}
{s["common_name"]}
'
f'
{s["length"]}
{s["protein_length"]}
'
f'
{s["gc_content"]:.1%}
{s["log_likelihood"]:.2f}
'
f'
{plddt_str}
'
)
html_parts.append("
")
# GC content comparison
html_parts.append('
')
html_parts.append(_make_bar_chart(
species,
{"GC Content": [scores[s]["gc_content"] for s in species]},
title="GC Content Across Species",
value_format=".2f",
))
html_parts.append("
")
# DNA phylogenetic tree
html_parts.append("
Phylogenetic Relationships
")
html_parts.append(
'
'
"Trees built from pairwise sequence identity using UPGMA clustering. "
"Species that diverged more recently cluster together. DNA and protein trees "
"may differ when synonymous mutations dominate."
"
All 4 pipeline stages completed. View individual task reports for DNA/protein
identity heatmaps, phylogenetic trees, interactive 3D protein structures with
pLDDT confidence, Carbon log-likelihood scores, and evolutionary analysis.
"""
await flyte.report.replace.aio(_wrap_report(final_html), do_flush=True)
log.info("Pipeline complete.")
return comparison_json, structures_json
# {{/docs-fragment pipeline}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(pipeline)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/genomic_gene_comparison/genomic_gene_comparison.py*
## Run the workflow
From the [example directory](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/genomic_gene_comparison):
```
cd v2/tutorials/genomic_gene_comparison
uv run --script genomic_gene_comparison.py
```
Or submit a specific gene set with the Flyte CLI:
```
flyte run genomic_gene_comparison.py pipeline --gene_set hemoglobin
```
This example needs a GPU for Carbon and ESMFold. Open the run URL and check each task's report tab for heatmaps, dendrograms, and interactive 3D viewers.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/biotech-healthcare/genomic-variant-effect ===
# Genomic variant effect prediction
> [!NOTE]
> Code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/genomic_variant_effect).
This tutorial demonstrates zero-shot variant effect prediction (VEP) with HuggingFace [Carbon](https://huggingface.co/HuggingFaceBio/Carbon-3B). The pipeline loads clinically relevant variants across genes such as BRCA2, TP53, CFTR, KRAS, and HBB, scores each mutation with a log-likelihood ratio, and produces rich HTML reports with DNA tracks, lollipop plots, confusion matrices, and ranked pathogenicity tables.
Flyte provides:
- **GPU-backed inference** for Carbon scoring with live progress reports.
- **CPU analysis tasks** for visualization and accuracy metrics without holding a GPU.
- **End-to-end orchestration** from variant loading through summary reporting.
## Define the task environments
```
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flyte>=2.4.0",
# "torch>=2.9.0",
# "transformers>=4.49.0",
# "accelerate>=0.34.0",
# "numpy",
# ]
# main = "pipeline"
# params = ""
# ///
import json
import logging
import math
import os
import tempfile
import flyte
import flyte.io
import flyte.report
# {{docs-fragment env}}
main_img = flyte.Image.from_uv_script(__file__, name="genomic-variant-effect", pre=True)
gpu_env = flyte.TaskEnvironment(
name="genomic-variant-effect-gpu",
image=main_img,
resources=flyte.Resources(cpu=4, memory="24Gi", gpu=1),
)
cpu_env = flyte.TaskEnvironment(
name="genomic-variant-effect-cpu",
image=main_img,
resources=flyte.Resources(cpu=2, memory="6Gi"),
depends_on=[gpu_env],
)
# {{/docs-fragment env}}
logging.basicConfig(level=logging.WARNING, format="%(message)s", force=True)
log = logging.getLogger(__name__)
log.setLevel(logging.INFO)
# ------------------------------------------------------------------
# Default gene variants — clinically relevant mutations
# ------------------------------------------------------------------
# Each entry: gene name -> { "sequence": reference DNA, "variants": [{ "pos": 0-indexed, "ref": base, "alt": base, "name": "...", "known_effect": "..." }] }
# Sequences are short windows (~120-200bp) around the variant site for tractable inference.
DEFAULT_GENE_VARIANTS = {
"BRCA2 (Breast Cancer)": {
"description": "Tumor suppressor critical for DNA repair via homologous recombination. Mutations dramatically increase breast and ovarian cancer risk.",
"sequence": "ATGGCCTCGAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAG",
"variants": [
{"pos": 12, "ref": "A", "alt": "T", "name": "c.37A>T", "known_effect": "pathogenic", "clinical": "Nonsense mutation — truncates protein early"},
{"pos": 18, "ref": "G", "alt": "A", "name": "c.55G>A", "known_effect": "benign", "clinical": "Synonymous — no amino acid change"},
{"pos": 30, "ref": "C", "alt": "T", "name": "c.91C>T", "known_effect": "pathogenic", "clinical": "Missense in DNA-binding domain"},
{"pos": 45, "ref": "G", "alt": "C", "name": "c.136G>C", "known_effect": "uncertain", "clinical": "Variant of uncertain significance (VUS)"},
],
},
"TP53 (Tumor Suppressor)": {
"description": "Guardian of the genome. Activates DNA repair, cell cycle arrest, and apoptosis. Mutated in >50% of human cancers.",
"sequence": "ATGGAGGAGCCGCAGTCAGATCCTAGCGTGAGTTTGCACCCTTCAGAGACAGAAACCACTGGATTGGAGACTACTTCCTGAAACAACGTTCTGTCCCCCTTGCCGTCCCAAGCAATGGATGAT",
"variants": [
{"pos": 15, "ref": "C", "alt": "T", "name": "R175H", "known_effect": "pathogenic", "clinical": "Hotspot — gain-of-function, dominant negative. Most common TP53 mutation in cancer"},
{"pos": 36, "ref": "T", "alt": "C", "name": "P72R", "known_effect": "benign", "clinical": "Common polymorphism — subtle effect on apoptosis efficiency"},
{"pos": 54, "ref": "C", "alt": "A", "name": "G245S", "known_effect": "pathogenic", "clinical": "Contact mutant — disrupts DNA binding"},
{"pos": 72, "ref": "T", "alt": "G", "name": "R248W", "known_effect": "pathogenic", "clinical": "Structural mutant — destabilizes DNA-binding loop"},
{"pos": 90, "ref": "C", "alt": "T", "name": "R273H", "known_effect": "pathogenic", "clinical": "Contact mutant — directly contacts DNA bases"},
],
},
"CFTR (Cystic Fibrosis)": {
"description": "Chloride channel protein. Mutations cause cystic fibrosis — the most common lethal genetic disease in people of European descent.",
"sequence": "ATGCAGAGGTCGCCTCTGGAAAAGGCCAGCGTTGTCTCCAAACTTTTTTTCAGCTGGACCAGACCAATTTTGAGGAAAGGATACAGACAGCGCCTGGAATTGTCAGACATATACCAAATCCCTTC",
"variants": [
{"pos": 9, "ref": "G", "alt": "A", "name": "G85E", "known_effect": "pathogenic", "clinical": "Disrupts chloride channel processing"},
{"pos": 24, "ref": "C", "alt": "T", "name": "R117H", "known_effect": "pathogenic", "clinical": "Reduces channel conductance — milder CF phenotype"},
{"pos": 48, "ref": "T", "alt": "C", "name": "I148T", "known_effect": "benign", "clinical": "Previously misclassified — now known benign polymorphism"},
{"pos": 66, "ref": "A", "alt": "G", "name": "R334W", "known_effect": "pathogenic", "clinical": "Gating mutation — channel opens less frequently"},
],
},
"KRAS (Oncogene)": {
"description": "GTPase signal switch. KRAS mutations are the most common oncogenic driver — found in ~25% of all human cancers, especially pancreatic, colorectal, and lung.",
"sequence": "ATGACTGAATATAAACTTGTGGTAGTTGGAGCTGGTGGCGTAGGCAAGAGTGCCTTGACGATACAGCTAATTCAGAATCATTTTGTGGACGAATATGATCCAACAATAGAGGATTCCTACAGGAA",
"variants": [
{"pos": 34, "ref": "G", "alt": "T", "name": "G12V", "known_effect": "pathogenic", "clinical": "Locks KRAS in active state — constitutive proliferation signal"},
{"pos": 35, "ref": "G", "alt": "A", "name": "G12D", "known_effect": "pathogenic", "clinical": "Most common KRAS mutation in pancreatic cancer"},
{"pos": 37, "ref": "G", "alt": "T", "name": "G13D", "known_effect": "pathogenic", "clinical": "Constitutively active — common in colorectal cancer"},
{"pos": 60, "ref": "C", "alt": "A", "name": "Q61K", "known_effect": "pathogenic", "clinical": "Impairs GTP hydrolysis — locked ON state"},
],
},
"HBB (Sickle Cell)": {
"description": "Beta-globin subunit of hemoglobin. The sickle cell mutation (E6V) is the most well-known single-base disease variant in humans.",
"sequence": "ATGGTGCATCTGACTCCTGAGGAGAAGTCTGCCGTTACTGCCCTGTGGGGCAAGGTGAACGTGGATGAAGTTGGTGGTGAGGCCCTGGGCAGGCTGCTGGTGGTCTACCCTTGGACCCAGAGG",
"variants": [
{"pos": 17, "ref": "A", "alt": "T", "name": "E6V (HbS)", "known_effect": "pathogenic", "clinical": "THE sickle cell mutation — causes hemoglobin polymerization under low O2"},
{"pos": 19, "ref": "G", "alt": "A", "name": "E6K (HbC)", "known_effect": "pathogenic", "clinical": "Hemoglobin C disease — milder than sickle cell but causes crystal formation"},
{"pos": 36, "ref": "G", "alt": "A", "name": "E26K", "known_effect": "benign", "clinical": "Hemoglobin E — most common Hb variant worldwide, mild effect"},
{"pos": 78, "ref": "C", "alt": "T", "name": "Q39X", "known_effect": "pathogenic", "clinical": "Nonsense — causes beta-thalassemia (no functional beta-globin)"},
],
},
}
# DNA base colors (classic genomics color scheme)
BASE_COLORS = {"A": "#2ecc71", "T": "#e74c3c", "G": "#f39c12", "C": "#3498db"}
BASE_COMPLEMENT = {"A": "T", "T": "A", "G": "C", "C": "G"}
# Pathogenicity color scheme
EFFECT_COLORS = {
"pathogenic": "#dc2626",
"benign": "#059669",
"uncertain": "#f59e0b",
}
EFFECT_BADGES = {
"pathogenic": "badge-danger",
"benign": "badge-success",
"uncertain": "badge-warning",
}
# ------------------------------------------------------------------
# Report styling — genomics-themed deep blues and teals
# ------------------------------------------------------------------
REPORT_CSS = """
"""
def _wrap_report(html: str) -> str:
return f'{REPORT_CSS}
{html}
'
# ------------------------------------------------------------------
# SVG chart helpers
# ------------------------------------------------------------------
def _make_bar_chart(
labels: list[str],
series: dict[str, list[float]],
title: str = "",
colors: list[str] | None = None,
width: int = 700,
height: int = 300,
value_format: str = ".2f",
) -> str:
"""Generate an SVG grouped bar chart."""
if not labels:
return ""
default_colors = ["#2563eb", "#1e3a5f", "#3b82f6", "#60a5fa", "#93c5fd"]
colors = colors or default_colors
ml, mr, mt, mb = 70, 20, 40, 80
cw = width - ml - mr
ch = height - mt - mb
all_vals = [v for vals in series.values() for v in vals]
y_max = max(abs(v) for v in all_vals) if all_vals else 1
y_min = min(all_vals) if all_vals else 0
# For VEP scores (negative = more damaging), we need to handle negative values
if y_min >= 0:
y_min_plot = 0
y_max_plot = y_max * 1.15 or 1
else:
y_max_plot = max(y_max * 1.15, 0.1)
y_min_plot = y_min * 1.15
y_range = y_max_plot - y_min_plot or 1
n_groups = len(labels)
n_series = len(series)
group_width = cw / n_groups
bar_width = group_width * 0.7 / max(n_series, 1)
gap = group_width * 0.15
def sy(v):
return mt + ch - (v - y_min_plot) / y_range * ch
svg = [
f'")
return "\n".join(svg)
def _make_heatmap(
matrix: list[list[float]],
row_labels: list[str],
col_labels: list[str],
title: str = "",
width: int = 700,
height: int = 500,
value_format: str = ".2f",
diverging: bool = False,
) -> str:
"""Generate an SVG heatmap. If diverging=True, uses red-white-blue scale centered at 0."""
n_rows = len(matrix)
n_cols = len(matrix[0]) if matrix else 0
if not n_rows or not n_cols:
return ""
show_values = n_rows <= 10 and n_cols <= 12
flat = [v for row in matrix for v in row]
v_min = min(flat)
v_max = max(flat)
if diverging:
abs_max = max(abs(v_min), abs(v_max)) or 1
def get_color(v):
t = v / abs_max # -1 to 1
if t < 0:
# White to red (negative = damaging)
r = 255
g = int(255 * (1 + t))
b = int(255 * (1 + t))
else:
# White to blue (positive = benign)
r = int(255 * (1 - t))
g = int(255 * (1 - t))
b = 255
return f"rgb({r},{g},{b})"
else:
v_range = v_max - v_min or 1
def get_color(v):
t = (v - v_min) / v_range
r = int(255 - t * (255 - 30))
g = int(255 - t * (255 - 58))
b = int(255 - t * (255 - 95))
return f"rgb({r},{g},{b})"
# Layout
ml = max(140, max(len(l) for l in row_labels) * 7 + 20) if row_labels else 140
mr = 20
mt = 80 if col_labels else 40
mb = 30
cw = width - ml - mr
ch = height - mt - mb
cell_w = cw / n_cols
cell_h = ch / n_rows
svg = [
f'")
return "\n".join(svg)
def _make_dna_track(
sequence: str,
variants: list[dict],
gene_name: str = "",
width: int = 900,
) -> str:
"""Render a color-coded DNA sequence track with variant positions highlighted."""
chars_per_line = 60
char_w = 11
line_h = 22
label_w = 50
n_lines = (len(sequence) + chars_per_line - 1) // chars_per_line
# Extra space for variant annotations
variant_positions = {v["pos"] for v in variants}
svg_h = n_lines * line_h + 60
svg = [
f'")
return "\n".join(svg)
def _make_lollipop_plot(
variants: list[dict],
seq_length: int,
title: str = "",
width: int = 700,
height: int = 200,
) -> str:
"""Generate a lollipop plot showing variant positions along a gene with effect scores."""
if not variants:
return ""
ml, mr, mt, mb = 50, 30, 40, 40
cw = width - ml - mr
ch = height - mt - mb
svg = [
f'")
return "\n".join(svg)
def _make_score_comparison_chart(
gene_results: dict,
width: int = 800,
height: int = 350,
) -> str:
"""Generate a dot plot comparing VEP scores across all genes, colored by known effect."""
all_variants = []
for gene_name, gene_data in gene_results.items():
for v in gene_data["variants"]:
all_variants.append({
"gene": gene_name.split("(")[0].strip(),
"name": v["name"],
"score": v.get("score", 0),
"known_effect": v["known_effect"],
})
if not all_variants:
return ""
ml, mr, mt, mb = 120, 30, 40, 30
cw = width - ml - mr
ch = height - mt - mb
scores = [v["score"] for v in all_variants]
s_min, s_max = min(scores), max(scores)
s_pad = (s_max - s_min) * 0.1 or 0.5
s_min -= s_pad
s_max += s_pad
s_range = s_max - s_min or 1
def sx(s):
return ml + (s - s_min) / s_range * cw
svg = [
f'")
return "\n".join(svg)
# ------------------------------------------------------------------
# Task 1: Load and validate gene variants
# ------------------------------------------------------------------
@cpu_env.task(cache="auto")
async def load_variants(
variants_json: str = "",
) -> flyte.io.Dir:
"""Load gene variant definitions, validate sequences, and save to a temp directory."""
if variants_json:
genes = json.loads(variants_json)
else:
genes = DEFAULT_GENE_VARIANTS
# Validate
valid_bases = set("ATGC")
for gene_name, gene_data in genes.items():
seq = gene_data["sequence"].upper()
invalid = set(seq) - valid_bases
if invalid:
log.warning(f"{gene_name}: invalid bases {invalid} — removing them")
seq = "".join(b for b in seq if b in valid_bases)
gene_data["sequence"] = seq
for v in gene_data["variants"]:
pos = v["pos"]
if pos < 0 or pos >= len(seq):
log.warning(f"{gene_name} variant {v['name']}: position {pos} out of range [0, {len(seq)})")
elif seq[pos] != v["ref"]:
log.warning(f"{gene_name} variant {v['name']}: expected ref={v['ref']} at pos {pos}, found {seq[pos]}")
total_variants = sum(len(g["variants"]) for g in genes.values())
log.info(f"Loaded {len(genes)} genes with {total_variants} variants")
out_dir = tempfile.mkdtemp(prefix="genomic_vep_")
with open(os.path.join(out_dir, "genes.json"), "w") as f:
json.dump(genes, f)
return await flyte.io.Dir.from_local(out_dir)
# ------------------------------------------------------------------
# Task 2: Run Carbon model for variant effect scoring
# ------------------------------------------------------------------
@gpu_env.task(report=True)
async def score_variants(
variants_dir: flyte.io.Dir,
model_name: str = "HuggingFaceBio/Carbon-3B",
) -> str:
"""Score each variant using Carbon's log-likelihood ratio.
For each variant, we compute:
score = log P(alt_sequence) - log P(ref_sequence)
A negative score means the model considers the variant less likely than
the reference — suggestive of a damaging/pathogenic effect. A score near
zero means the model sees little difference (likely benign).
"""
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
log.info(f"Loading Carbon model: {model_name}")
# Load model
device = "cuda" if torch.cuda.is_available() else "cpu"
if device == "cpu":
log.warning("Running on CPU — inference will be slow. GPU recommended for production.")
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
dtype=torch.bfloat16 if device == "cuda" else torch.float32,
).to(device)
model.eval()
# Load variants
variants_path = await variants_dir.download()
with open(os.path.join(variants_path, "genes.json")) as f:
genes = json.load(f)
results = {}
total_variants = sum(len(g["variants"]) for g in genes.values())
scored = 0
progress_html = """
",
]
# Per-gene tables
for gene_name, gene_data in results.items():
html_parts.append(f'
{gene_name}
')
html_parts.append(f'
{gene_data["description"]}
')
html_parts.append("
Variant
Ref
Alt
VEP Score
Known Effect
Clinical
")
for v in gene_data["variants"]:
badge = EFFECT_BADGES.get(v["known_effect"], "badge-info")
direction = "damaging" if v["score"] < -0.1 else "neutral" if abs(v["score"]) <= 0.1 else "tolerated"
html_parts.append(
f'
"]
# ------------------------------------------------------------------
# Overall accuracy: does the model's score direction match known labels?
# ------------------------------------------------------------------
all_variants = []
correct = 0
total_known = 0
true_pos = 0
false_pos = 0
true_neg = 0
false_neg = 0
for gene_name, gene_data in results.items():
for v in gene_data["variants"]:
all_variants.append({**v, "gene": gene_name})
if v["known_effect"] in ("pathogenic", "benign"):
total_known += 1
predicted_pathogenic = v["score"] < -0.05
actual_pathogenic = v["known_effect"] == "pathogenic"
if predicted_pathogenic == actual_pathogenic:
correct += 1
if predicted_pathogenic and actual_pathogenic:
true_pos += 1
elif predicted_pathogenic and not actual_pathogenic:
false_pos += 1
elif not predicted_pathogenic and actual_pathogenic:
false_neg += 1
else:
true_neg += 1
accuracy = correct / total_known if total_known else 0
precision = true_pos / (true_pos + false_pos) if (true_pos + false_pos) else 0
recall = true_pos / (true_pos + false_neg) if (true_pos + false_neg) else 0
html_parts.append('
')
html_parts.append(f'
{accuracy:.0%}
Direction Accuracy
')
html_parts.append(f'
{precision:.0%}
Precision (Pathogenic)
')
html_parts.append(f'
{recall:.0%}
Recall (Pathogenic)
')
html_parts.append(f'
{len(all_variants)}
Total Variants
')
html_parts.append("
")
html_parts.append(
'
'
"How to read VEP scores: Negative scores mean Carbon considers the variant "
"less likely than the reference sequence — suggestive of a damaging effect. Scores near "
"zero indicate the model sees little difference (likely benign). The magnitude indicates "
"confidence."
"
")
# Score bar chart for this gene
variant_names = [v["name"] for v in gene_data["variants"]]
variant_scores = [v["score"] for v in gene_data["variants"]]
html_parts.append('
')
html_parts.append(_make_bar_chart(
variant_names,
{"VEP Score": variant_scores},
title=f"{short_name} — Log-Likelihood Ratio Scores",
colors=[EFFECT_COLORS.get(v["known_effect"], "#6b7280") for v in gene_data["variants"]],
value_format=".3f",
))
html_parts.append("
")
# Variant detail cards
for v in gene_data["variants"]:
badge = EFFECT_BADGES.get(v["known_effect"], "badge-info")
score_color = "#dc2626" if v["score"] < -0.1 else "#059669" if v["score"] > 0.05 else "#f59e0b"
html_parts.append(
f'
")
# ------------------------------------------------------------------
# Score distribution by known effect
# ------------------------------------------------------------------
html_parts.append("
Score Distribution by Known Effect
")
pathogenic_scores = [v["score"] for v in all_variants if v["known_effect"] == "pathogenic"]
benign_scores = [v["score"] for v in all_variants if v["known_effect"] == "benign"]
uncertain_scores = [v["score"] for v in all_variants if v["known_effect"] == "uncertain"]
stats_html = '
'
for label, scores, color in [
("Pathogenic", pathogenic_scores, "#dc2626"),
("Benign", benign_scores, "#059669"),
("Uncertain", uncertain_scores, "#f59e0b"),
]:
if scores:
mean_s = sum(scores) / len(scores)
min_s = min(scores)
max_s = max(scores)
stats_html += (
f'
'
"This pipeline uses HuggingFace Carbon, an autoregressive genomic foundation model "
"trained on 1 trillion tokens of DNA sequence, to perform zero-shot variant effect "
"prediction. No fine-tuning or labeled training data was used — the model scores "
"variants purely based on its learned understanding of DNA sequence grammar."
"
",
]
# Key metrics
html_parts.append('
')
html_parts.append(f'
{len(results)}
Genes Analyzed
')
html_parts.append(f'
{analysis["total_variants"]}
Variants Scored
')
html_parts.append(f'
{analysis["accuracy"]:.0%}
Direction Accuracy
')
html_parts.append(f'
{analysis["precision"]:.0%}
Precision
')
html_parts.append(f'
{analysis["recall"]:.0%}
Recall
')
html_parts.append("
")
# Gene summary table
html_parts.append("
Per-Gene Summary
")
html_parts.append(
"
Gene
Variants
Mean Score
"
"
Pathogenic
Benign
Uncertain
"
)
for gene_name, gene_data in results.items():
variants = gene_data["variants"]
scores = [v["score"] for v in variants]
mean_score = sum(scores) / len(scores) if scores else 0
n_path = sum(1 for v in variants if v["known_effect"] == "pathogenic")
n_benign = sum(1 for v in variants if v["known_effect"] == "benign")
n_unc = sum(1 for v in variants if v["known_effect"] == "uncertain")
short = gene_name.split("(")[0].strip()
html_parts.append(
f"
{short}
{len(variants)}
"
f"
{mean_score:.4f}
"
f'
{n_path}
'
f'
{n_benign}
'
f'
{n_unc}
'
)
html_parts.append("
")
# Cross-gene heatmap: gene x metric
gene_names = [g.split("(")[0].strip() for g in results.keys()]
metrics = ["Mean Score", "Min Score", "Max Score", "# Variants"]
matrix = []
for gene_data in results.values():
scores = [v["score"] for v in gene_data["variants"]]
matrix.append([
sum(scores) / len(scores) if scores else 0,
min(scores) if scores else 0,
max(scores) if scores else 0,
len(scores),
])
html_parts.append("
")
# All variants ranked by score (most damaging first)
html_parts.append("
All Variants Ranked by Impact
")
all_vars_sorted = []
for gene_name, gene_data in results.items():
for v in gene_data["variants"]:
all_vars_sorted.append({**v, "gene": gene_name.split("(")[0].strip()})
all_vars_sorted.sort(key=lambda x: x["score"])
html_parts.append(
"
#
Gene
Variant
Score
"
"
Known
Clinical Significance
"
)
for i, v in enumerate(all_vars_sorted):
badge = EFFECT_BADGES.get(v["known_effect"], "badge-info")
score_color = "#dc2626" if v["score"] < -0.1 else "#059669" if v["score"] > 0.05 else "#f59e0b"
html_parts.append(
f'
{i + 1}
{v["gene"]}
{v["name"]}
'
f'
{v["score"]:.4f}
'
f'
{v["known_effect"]}
'
f'
{v.get("clinical", "")}
'
)
html_parts.append("
")
# Method note
html_parts.append(
'
'
"Method: Zero-shot variant effect prediction using log-likelihood ratio scoring. "
"For each variant, we compute score = log P(mutant sequence | Carbon) - log P(reference sequence | Carbon). "
"Negative scores indicate the model considers the mutant less probable than the reference, "
"which correlates with pathogenicity. This approach requires no fine-tuning and generalizes "
"across genes and variant types.
"
"Limitations: These are short sequence windows — real clinical VEP would use longer "
"genomic context (Carbon supports up to 786kbp). The threshold for pathogenicity classification "
"(-0.05) is a simple heuristic; clinical use requires calibrated thresholds per gene."
"
",
]
# Per-gene tables
for gene_name, gene_data in results.items():
html_parts.append(f'
{gene_name}
')
html_parts.append(f'
{gene_data["description"]}
')
html_parts.append("
Variant
Ref
Alt
VEP Score
Known Effect
Clinical
")
for v in gene_data["variants"]:
badge = EFFECT_BADGES.get(v["known_effect"], "badge-info")
direction = "damaging" if v["score"] < -0.1 else "neutral" if abs(v["score"]) <= 0.1 else "tolerated"
html_parts.append(
f'
"]
# ------------------------------------------------------------------
# Overall accuracy: does the model's score direction match known labels?
# ------------------------------------------------------------------
all_variants = []
correct = 0
total_known = 0
true_pos = 0
false_pos = 0
true_neg = 0
false_neg = 0
for gene_name, gene_data in results.items():
for v in gene_data["variants"]:
all_variants.append({**v, "gene": gene_name})
if v["known_effect"] in ("pathogenic", "benign"):
total_known += 1
predicted_pathogenic = v["score"] < -0.05
actual_pathogenic = v["known_effect"] == "pathogenic"
if predicted_pathogenic == actual_pathogenic:
correct += 1
if predicted_pathogenic and actual_pathogenic:
true_pos += 1
elif predicted_pathogenic and not actual_pathogenic:
false_pos += 1
elif not predicted_pathogenic and actual_pathogenic:
false_neg += 1
else:
true_neg += 1
accuracy = correct / total_known if total_known else 0
precision = true_pos / (true_pos + false_pos) if (true_pos + false_pos) else 0
recall = true_pos / (true_pos + false_neg) if (true_pos + false_neg) else 0
html_parts.append('
')
html_parts.append(f'
{accuracy:.0%}
Direction Accuracy
')
html_parts.append(f'
{precision:.0%}
Precision (Pathogenic)
')
html_parts.append(f'
{recall:.0%}
Recall (Pathogenic)
')
html_parts.append(f'
{len(all_variants)}
Total Variants
')
html_parts.append("
")
html_parts.append(
'
'
"How to read VEP scores: Negative scores mean Carbon considers the variant "
"less likely than the reference sequence — suggestive of a damaging effect. Scores near "
"zero indicate the model sees little difference (likely benign). The magnitude indicates "
"confidence."
"
")
# Score bar chart for this gene
variant_names = [v["name"] for v in gene_data["variants"]]
variant_scores = [v["score"] for v in gene_data["variants"]]
html_parts.append('
')
html_parts.append(_make_bar_chart(
variant_names,
{"VEP Score": variant_scores},
title=f"{short_name} — Log-Likelihood Ratio Scores",
colors=[EFFECT_COLORS.get(v["known_effect"], "#6b7280") for v in gene_data["variants"]],
value_format=".3f",
))
html_parts.append("
")
# Variant detail cards
for v in gene_data["variants"]:
badge = EFFECT_BADGES.get(v["known_effect"], "badge-info")
score_color = "#dc2626" if v["score"] < -0.1 else "#059669" if v["score"] > 0.05 else "#f59e0b"
html_parts.append(
f'
")
# ------------------------------------------------------------------
# Score distribution by known effect
# ------------------------------------------------------------------
html_parts.append("
Score Distribution by Known Effect
")
pathogenic_scores = [v["score"] for v in all_variants if v["known_effect"] == "pathogenic"]
benign_scores = [v["score"] for v in all_variants if v["known_effect"] == "benign"]
uncertain_scores = [v["score"] for v in all_variants if v["known_effect"] == "uncertain"]
stats_html = '
'
for label, scores, color in [
("Pathogenic", pathogenic_scores, "#dc2626"),
("Benign", benign_scores, "#059669"),
("Uncertain", uncertain_scores, "#f59e0b"),
]:
if scores:
mean_s = sum(scores) / len(scores)
min_s = min(scores)
max_s = max(scores)
stats_html += (
f'
'
"This pipeline uses HuggingFace Carbon, an autoregressive genomic foundation model "
"trained on 1 trillion tokens of DNA sequence, to perform zero-shot variant effect "
"prediction. No fine-tuning or labeled training data was used — the model scores "
"variants purely based on its learned understanding of DNA sequence grammar."
"
",
]
# Key metrics
html_parts.append('
')
html_parts.append(f'
{len(results)}
Genes Analyzed
')
html_parts.append(f'
{analysis["total_variants"]}
Variants Scored
')
html_parts.append(f'
{analysis["accuracy"]:.0%}
Direction Accuracy
')
html_parts.append(f'
{analysis["precision"]:.0%}
Precision
')
html_parts.append(f'
{analysis["recall"]:.0%}
Recall
')
html_parts.append("
")
# Gene summary table
html_parts.append("
Per-Gene Summary
")
html_parts.append(
"
Gene
Variants
Mean Score
"
"
Pathogenic
Benign
Uncertain
"
)
for gene_name, gene_data in results.items():
variants = gene_data["variants"]
scores = [v["score"] for v in variants]
mean_score = sum(scores) / len(scores) if scores else 0
n_path = sum(1 for v in variants if v["known_effect"] == "pathogenic")
n_benign = sum(1 for v in variants if v["known_effect"] == "benign")
n_unc = sum(1 for v in variants if v["known_effect"] == "uncertain")
short = gene_name.split("(")[0].strip()
html_parts.append(
f"
{short}
{len(variants)}
"
f"
{mean_score:.4f}
"
f'
{n_path}
'
f'
{n_benign}
'
f'
{n_unc}
'
)
html_parts.append("
")
# Cross-gene heatmap: gene x metric
gene_names = [g.split("(")[0].strip() for g in results.keys()]
metrics = ["Mean Score", "Min Score", "Max Score", "# Variants"]
matrix = []
for gene_data in results.values():
scores = [v["score"] for v in gene_data["variants"]]
matrix.append([
sum(scores) / len(scores) if scores else 0,
min(scores) if scores else 0,
max(scores) if scores else 0,
len(scores),
])
html_parts.append("
")
# All variants ranked by score (most damaging first)
html_parts.append("
All Variants Ranked by Impact
")
all_vars_sorted = []
for gene_name, gene_data in results.items():
for v in gene_data["variants"]:
all_vars_sorted.append({**v, "gene": gene_name.split("(")[0].strip()})
all_vars_sorted.sort(key=lambda x: x["score"])
html_parts.append(
"
#
Gene
Variant
Score
"
"
Known
Clinical Significance
"
)
for i, v in enumerate(all_vars_sorted):
badge = EFFECT_BADGES.get(v["known_effect"], "badge-info")
score_color = "#dc2626" if v["score"] < -0.1 else "#059669" if v["score"] > 0.05 else "#f59e0b"
html_parts.append(
f'
{i + 1}
{v["gene"]}
{v["name"]}
'
f'
{v["score"]:.4f}
'
f'
{v["known_effect"]}
'
f'
{v.get("clinical", "")}
'
)
html_parts.append("
")
# Method note
html_parts.append(
'
'
"Method: Zero-shot variant effect prediction using log-likelihood ratio scoring. "
"For each variant, we compute score = log P(mutant sequence | Carbon) - log P(reference sequence | Carbon). "
"Negative scores indicate the model considers the mutant less probable than the reference, "
"which correlates with pathogenicity. This approach requires no fine-tuning and generalizes "
"across genes and variant types.
"
"Limitations: These are short sequence windows — real clinical VEP would use longer "
"genomic context (Carbon supports up to 786kbp). The threshold for pathogenicity classification "
"(-0.05) is a simple heuristic; clinical use requires calibrated thresholds per gene."
"
Model: HuggingFace Carbon |
Method: Zero-shot log-likelihood ratio scoring |
Genes: {', '.join(g.split('(')[0].strip() for g in results.keys())}
All 4 pipeline stages completed successfully. View individual task reports for detailed
visualizations including DNA sequence tracks, variant lollipop plots, VEP score charts,
confusion matrices, and ranked variant tables.
"""
await flyte.report.replace.aio(_wrap_report(final_html), do_flush=True)
log.info("Pipeline complete.")
return scores_json, analysis_json
# {{/docs-fragment pipeline}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(pipeline)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/genomic_variant_effect/genomic_variant_effect.py*
## Run the workflow
From the [example directory](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/genomic_variant_effect):
```
cd v2/tutorials/genomic_variant_effect
uv run --script genomic_variant_effect.py
```
Use a smaller Carbon model for faster iteration:
```
flyte run genomic_variant_effect.py pipeline --model_name HuggingFaceBio/Carbon-500M
```
Negative VEP scores indicate the model prefers the reference allele over the alternate — a signal correlated with pathogenicity in this zero-shot setup.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/biotech-healthcare/drug-molecule-screening ===
# Drug molecule screening agent
> [!NOTE]
> Code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/drug_molecule_screening).
This tutorial builds an **agentic** virtual drug-screening workflow on Flyte. A medicinal-chemistry agent interprets your therapeutic goal in plain language, derives screening criteria, and composes durable RDKit stage tasks — while the scientific core (property computation, Lipinski filters, Tanimoto similarity, ranking, and HTML reports) stays in trusted, deterministic tools.
The pattern follows how cheminformatics agents like ChemCrow and PharmAgents are built: **the LLM plans and reflects; RDKit computes.**
Flyte provides:
- **Flyte-native agent orchestration** via `flyte.ai.agents.Agent` — see [Flyte-native agents](https://www.union.ai/docs/v2/union/user-guide/build-agent/flyte-agents/page.md)
- **Typed agent tool I/O** — Flyte 2.5.4+ passes `flyte.io.Dir`, `File`, and `DataFrame` between agent tool calls so the LLM can compose multi-step pipelines directly
- **Cached molecule loading** so repeated runs skip re-parsing SMILES
- **Report-enabled stage tasks** that stream property charts, similarity matrices, and candidate spotlights as each step completes
- **Hybrid iteration** — the agent re-runs `screen_candidates` and `generate_report` with adjusted criteria when the funnel is too narrow, reusing cached `molecule_dir` and `properties_json`
> [!NOTE] Prerequisites
> Create an Anthropic API key secret (the key name must match the `TaskEnvironment`):
>
> ```
> flyte create secret internal-anthropic-api-key
> ```
>
> See [Secrets](https://www.union.ai/docs/v2/union/user-guide/task-configuration/secrets/page.md) for scoping and file-based secrets.
## Define the task environment
The pipeline runs on CPU with RDKit, LiteLLM, and system libraries for 2D structure rendering.
```
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flyte>=2.5.4",
# "litellm",
# "rdkit",
# "numpy",
# "scikit-learn",
# "pillow",
# ]
# main = "pipeline"
# params = ""
# ///
"""Virtual drug molecule screening — compute properties, apply Lipinski filters, rank candidates."""
import base64
import io
import json
import logging
import math
import os
import tempfile
import flyte
import flyte.io
import flyte.report
from flyte.ai.agents import Agent, tool
MODEL = os.getenv("DRUG_SCREENING_MODEL", "claude-haiku-4-5")
# {{docs-fragment env}}
main_img = flyte.Image.from_uv_script(__file__, name="drug-molecule-screening", pre=True).with_apt_packages(
"libxrender1", "libxext6", "libexpat1",
)
env = flyte.TaskEnvironment(
name="drug-molecule-screening",
image=main_img,
resources=flyte.Resources(cpu=2, memory="6Gi"),
secrets=[
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
)
# {{/docs-fragment env}}
logging.basicConfig(level=logging.WARNING, format="%(message)s", force=True)
log = logging.getLogger(__name__)
log.setLevel(logging.INFO)
# ------------------------------------------------------------------
# Default molecule library — real SMILES for well-known drugs
# ------------------------------------------------------------------
DEFAULT_MOLECULES = {
"Aspirin": "CC(=O)OC1=CC=CC=C1C(=O)O",
"Ibuprofen": "CC(C)CC1=CC=C(C=C1)C(C)C(=O)O",
"Caffeine": "CN1C=NC2=C1C(=O)N(C(=O)N2C)C",
"Penicillin G": "CC1(C(N2C(S1)C(C2=O)NC(=O)CC3=CC=CC=C3)C(=O)O)C",
"Metformin": "CN(C)C(=N)NC(=N)N",
"Paracetamol": "CC(=O)NC1=CC=C(C=C1)O",
"Diazepam": "ClC1=CC2=C(C=C1)N(C(=O)CN=C2C3=CC=CC=C3)C",
"Omeprazole": "CC1=CN=C(C(=C1OC)C)CS(=O)C2=NC3=CC=CC=C3N2",
"Atorvastatin": "CC(C)C1=C(C(=C(N1CCC(CC(CC(=O)O)O)O)C2=CC=C(C=C2)F)C3=CC=CC=C3)C(=O)NC4=CC=CC=C4",
"Methotrexate": "CN(CC1=CN=C2N=C(N=C(N)C2=N1)N)C3=CC=C(C=C3)C(=O)NC(CCC(=O)O)C(=O)O",
"Doxorubicin": "CC1C(C(CC(O1)OC2CC(CC3=C2C(=C4C(=C3O)C(=O)C5=C(C4=O)C(=CC=C5)OC)O)(C(=O)CO)O)N)O",
"Tamoxifen": "CCC(=C(C1=CC=CC=C1)C2=CC=C(C=C2)OCCN(C)C)C3=CC=CC=C3",
"Lopinavir": "CC1=C(C(=CC=C1)C)OCC(=O)NC(CC2=CC=CC=C2)C(CC(CC3=CC=CC=C3)NC(=O)C(C(C)C)N4CCCNC4=O)O",
"Remdesivir": "CCC(CC)COC(=O)C(C)NP(=O)(OCC1C(C(C(O1)C2=CC=C3N2N=CN=C3N)O)O)OC4=CC=CC=C4",
"Erlotinib": "COCCOC1=CC2=C(C=C1OCCOC)C(=NC=N2)NC3=CC=CC(=C3)C#C",
}
# ------------------------------------------------------------------
# Report styling — pharma blue/cyan theme
# ------------------------------------------------------------------
REPORT_CSS = """
"""
def _wrap_report(html: str) -> str:
"""Wrap HTML content with report styling."""
return f'{REPORT_CSS}
{html}
'
# ------------------------------------------------------------------
# SVG chart helpers
# ------------------------------------------------------------------
def _mol_to_data_uri(mol, size: tuple[int, int] = (300, 300)) -> str:
"""Convert an RDKit molecule to a PNG base64 data URI."""
from rdkit.Chem import Draw
img = Draw.MolToImage(mol, size=size)
buf = io.BytesIO()
img.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode()
return f"data:image/png;base64,{b64}"
def _make_bar_chart(
labels: list[str],
series: dict[str, list[float]],
title: str = "",
colors: list[str] | None = None,
width: int = 700,
height: int = 340,
y_max_cap: float | None = None,
horizontal: bool = False,
value_fmt: str = ".1f",
) -> str:
"""Generate an SVG grouped bar chart.
Args:
labels: Category labels.
series: Dict mapping series name to list of values.
title: Chart title.
colors: Colors for each series.
width/height: SVG dimensions.
y_max_cap: Cap the y-axis at this value.
horizontal: If True, draw horizontal bars.
value_fmt: Format string for value labels.
Returns:
SVG string.
"""
if not labels:
return ""
default_colors = ["#0891b2", "#0e4f6e", "#06d6a0", "#a5f3fc", "#155e75"]
colors = colors or default_colors
if horizontal:
return _make_horizontal_bar_chart(labels, series, title, colors, width, height, value_fmt)
ml, mr, mt, mb = 60, 20, 40, 60
cw = width - ml - mr
ch = height - mt - mb
all_vals = [v for vals in series.values() for v in vals]
y_max = max(all_vals) if all_vals else 1
y_max_plot = y_max * 1.15 or 1
if y_max_cap is not None:
y_max_plot = min(y_max_plot, y_max_cap) or y_max_cap
n_groups = len(labels)
n_series = len(series)
group_width = cw / n_groups
bar_width = group_width * 0.7 / max(n_series, 1)
gap = group_width * 0.15
def sy(v):
return mt + ch - (v / y_max_plot) * ch
svg = [
f'")
return "\n".join(svg)
def _make_horizontal_bar_chart(
labels: list[str],
series: dict[str, list[float]],
title: str = "",
colors: list[str] | None = None,
width: int = 700,
height: int = 400,
value_fmt: str = ".1f",
) -> str:
"""Generate an SVG horizontal bar chart (sorted)."""
default_colors = ["#0891b2", "#0e4f6e", "#06d6a0"]
colors = colors or default_colors
n = len(labels)
row_height = max(22, min(35, (height - 80) // max(n, 1)))
actual_height = max(height, 80 + n * row_height)
ml, mr, mt, mb = 120, 60, 40, 20
cw = width - ml - mr
ch = actual_height - mt - mb
# Use first series
first_key = list(series.keys())[0]
vals = series[first_key]
x_max = max(vals) * 1.15 if vals else 1
svg = [
f'")
return "\n".join(svg)
def _make_heatmap(
matrix: list[list[float]],
row_labels: list[str],
col_labels: list[str],
title: str = "",
color_scale: str = "cyan",
width: int = 700,
height: int = 500,
value_fmt: str = ".2f",
) -> str:
"""Generate an SVG heatmap.
Args:
matrix: 2D list of values (rows x cols).
row_labels: Labels for rows.
col_labels: Labels for columns.
title: Chart title.
color_scale: Color scheme ("cyan", "red", "green").
width/height: SVG dimensions.
value_fmt: Format string for cell values.
Returns:
SVG string.
"""
if not matrix or not matrix[0]:
return ""
n_rows = len(matrix)
n_cols = len(matrix[0])
ml, mr, mt, mb = 110, 20, 70, 20
cw = width - ml - mr
ch = height - mt - mb
cell_w = cw / n_cols
cell_h = ch / n_rows
# Flatten to find range
flat = [v for row in matrix for v in row]
v_min = min(flat)
v_max = max(flat)
v_range = v_max - v_min or 1
def color_for(v):
t = (v - v_min) / v_range
if color_scale == "cyan":
# White to deep teal
r = int(255 - t * (255 - 14))
g = int(255 - t * (255 - 79))
b = int(255 - t * (255 - 110))
elif color_scale == "red":
r = int(255 - t * 50)
g = int(255 - t * 200)
b = int(255 - t * 200)
else: # green
r = int(255 - t * 200)
g = int(255 - t * 50)
b = int(255 - t * 200)
return f"rgb({r},{g},{b})"
svg = [
f'")
return "\n".join(svg)
def _make_scatter_plot(
points: list[dict],
x_label: str = "MW",
y_label: str = "LogP",
title: str = "",
reference_lines: list[dict] | None = None,
width: int = 700,
height: int = 400,
) -> str:
"""Generate an SVG scatter plot.
Args:
points: List of dicts with "x", "y", "label" keys.
x_label/y_label: Axis labels.
title: Chart title.
reference_lines: List of dicts with "axis" ("x"/"y"), "value", "label".
width/height: SVG dimensions.
Returns:
SVG string.
"""
if not points:
return ""
ml, mr, mt, mb = 60, 30, 40, 50
cw = width - ml - mr
ch = height - mt - mb
x_vals = [p["x"] for p in points]
y_vals = [p["y"] for p in points]
x_min, x_max = min(x_vals) * 0.9, max(x_vals) * 1.1
y_min, y_max = min(y_vals) - 1, max(y_vals) + 1
# Extend ranges to include reference lines
if reference_lines:
for rl in reference_lines:
if rl["axis"] == "x":
x_max = max(x_max, rl["value"] * 1.1)
else:
y_max = max(y_max, rl["value"] * 1.1)
x_range = x_max - x_min or 1
y_range = y_max - y_min or 1
def sx(v):
return ml + (v - x_min) / x_range * cw
def sy(v):
return mt + ch - (v - y_min) / y_range * ch
svg = [
f'")
return "\n".join(svg)
def _make_funnel(
stages: list[dict],
title: str = "",
width: int = 600,
height: int = 400,
) -> str:
"""Generate an SVG funnel visualization.
Args:
stages: List of dicts with "label", "count", "total" keys.
title: Chart title.
width/height: SVG dimensions.
Returns:
SVG string.
"""
if not stages:
return ""
n = len(stages)
mt = 50
mb = 20
available_h = height - mt - mb
stage_h = available_h / n
cx = width / 2
# Color gradient from light cyan to deep teal
colors = []
for i in range(n):
t = i / max(n - 1, 1)
r = int(207 - t * (207 - 14))
g = int(250 - t * (250 - 79))
b = int(254 - t * (254 - 110))
colors.append(f"rgb({r},{g},{b})")
svg = [
f'")
return "\n".join(svg)
# ------------------------------------------------------------------
# Task 1: Load and validate molecules
# ------------------------------------------------------------------
@tool
@env.task(cache="auto")
async def load_molecules(
molecules_json: str = "",
) -> flyte.io.Dir:
"""Parse SMILES strings, validate with RDKit, generate 2D depictions.
Args:
molecules_json: JSON string mapping molecule names to SMILES.
Defaults to a curated library of ~15 well-known drugs.
Returns:
flyte.io.Dir containing molecule data (JSON + PNG depictions).
Pass this directory to compute_properties and generate_report.
"""
from rdkit import Chem
from rdkit.Chem import Draw
if molecules_json.strip():
molecules = json.loads(molecules_json)
else:
molecules = DEFAULT_MOLECULES
out_dir = tempfile.mkdtemp(prefix="mol_library_")
results = []
valid_count = 0
invalid_count = 0
log.info(f"Parsing {len(molecules)} molecules...")
for name, smiles in molecules.items():
mol = Chem.MolFromSmiles(smiles)
if mol is None:
log.warning(f" [INVALID] {name}: {smiles}")
invalid_count += 1
continue
valid_count += 1
# Generate 2D depiction as PNG
img = Draw.MolToImage(mol, size=(300, 300))
img_path = os.path.join(out_dir, f"{name.replace(' ', '_')}.png")
img.save(img_path)
results.append({
"name": name,
"smiles": smiles,
"valid": True,
"image_file": os.path.basename(img_path),
})
# Save molecule manifest
manifest = {
"total": len(molecules),
"valid": valid_count,
"invalid": invalid_count,
"molecules": results,
}
manifest_path = os.path.join(out_dir, "manifest.json")
with open(manifest_path, "w") as f:
json.dump(manifest, f, indent=2)
log.info(f"Loaded {valid_count} valid molecules ({invalid_count} invalid)")
return await flyte.io.Dir.from_local(out_dir)
# ------------------------------------------------------------------
# Task 2: Compute physicochemical properties
# ------------------------------------------------------------------
@tool
@env.task(report=True)
async def compute_properties(
molecule_dir: flyte.io.Dir,
) -> str:
"""Compute drug-likeness properties for all molecules.
Computes MW, LogP, HBD, HBA, TPSA, rotatable bonds, formal charge,
ring count, QED, and Lipinski Rule of Five compliance.
Args:
molecule_dir: Directory from load_molecules.
Returns:
JSON string with all computed properties. Pass to screen_candidates
and generate_report.
"""
from rdkit import Chem
from rdkit.Chem import Descriptors, Lipinski
from rdkit.Chem.QED import qed
# --- Loading report ---
await flyte.report.replace.aio(
_wrap_report("
Computing Molecular Properties...
"
"
Analyzing physicochemical descriptors for all molecules.
"),
do_flush=True,
)
mol_dir = await molecule_dir.download()
with open(os.path.join(mol_dir, "manifest.json")) as f:
manifest = json.load(f)
molecules_data = []
lipinski_pass = 0
for mol_info in manifest["molecules"]:
mol = Chem.MolFromSmiles(mol_info["smiles"])
if mol is None:
continue
mw = Descriptors.MolWt(mol)
logp = Descriptors.MolLogP(mol)
hbd = Lipinski.NumHDonors(mol)
hba = Lipinski.NumHAcceptors(mol)
tpsa = Descriptors.TPSA(mol)
rotatable = Lipinski.NumRotatableBonds(mol)
formal_charge = Chem.GetFormalCharge(mol)
num_rings = Lipinski.RingCount(mol)
qed_score = qed(mol)
# Lipinski Rule of Five
lipinski = {
"mw_ok": mw <= 500,
"logp_ok": logp <= 5,
"hbd_ok": hbd <= 5,
"hba_ok": hba <= 10,
}
lipinski_all = all(lipinski.values())
if lipinski_all:
lipinski_pass += 1
# Read image for data URI
img_path = os.path.join(mol_dir, mol_info["image_file"])
data_uri = ""
if os.path.exists(img_path):
with open(img_path, "rb") as img_f:
b64 = base64.b64encode(img_f.read()).decode()
data_uri = f"data:image/png;base64,{b64}"
molecules_data.append({
"name": mol_info["name"],
"smiles": mol_info["smiles"],
"mw": round(mw, 2),
"logp": round(logp, 2),
"hbd": hbd,
"hba": hba,
"tpsa": round(tpsa, 2),
"rotatable_bonds": rotatable,
"formal_charge": formal_charge,
"num_rings": num_rings,
"qed": round(qed_score, 4),
"lipinski": lipinski,
"lipinski_pass": lipinski_all,
"image_data_uri": data_uri,
})
total = len(molecules_data)
avg_mw = sum(m["mw"] for m in molecules_data) / total if total else 0
avg_logp = sum(m["logp"] for m in molecules_data) / total if total else 0
lipinski_rate = lipinski_pass / total * 100 if total else 0
# ---- Build report ----
html_parts = []
# Header
html_parts.append("
Molecular Properties Analysis
")
# Stat grid
html_parts.append('
')
for val, label in [
(str(total), "Total Molecules"),
(f"{lipinski_rate:.0f}%", "Lipinski Pass Rate"),
(f"{avg_mw:.1f}", "Avg. MW (Da)"),
(f"{avg_logp:.2f}", "Avg. LogP"),
]:
html_parts.append(
f'
{val}
'
f'
{label}
'
)
html_parts.append("
")
# Molecule gallery
html_parts.append("
Molecule Library
")
html_parts.append('
')
for m in molecules_data:
if m["image_data_uri"]:
badge_class = "badge-success" if m["lipinski_pass"] else "badge-danger"
badge_text = "Lipinski Pass" if m["lipinski_pass"] else "Lipinski Fail"
html_parts.append(
f'
'
f''
f'
{m["name"]}
'
f'
MW: {m["mw"]:.1f} | LogP: {m["logp"]:.2f}
'
f'
{badge_text}
'
f'
'
)
html_parts.append("
")
# MW bar chart (horizontal, sorted)
sorted_by_mw = sorted(molecules_data, key=lambda m: m["mw"], reverse=True)
mw_labels = [m["name"] for m in sorted_by_mw]
mw_vals = [m["mw"] for m in sorted_by_mw]
mw_chart = _make_bar_chart(
mw_labels, {"MW (Da)": mw_vals},
title="Molecular Weight Distribution",
horizontal=True,
width=700, height=max(300, len(mw_labels) * 30 + 80),
value_fmt=".1f",
)
html_parts.append("
')
# Property heatmap (molecules x properties)
prop_names = ["MW", "LogP", "HBD", "HBA", "TPSA", "Rot. Bonds"]
# Normalize each property to 0-1 for heatmap
raw_matrix = []
for m in molecules_data:
raw_matrix.append([m["mw"], m["logp"], m["hbd"], m["hba"], m["tpsa"], m["rotatable_bonds"]])
# Normalize per column
n_props = len(prop_names)
col_min = [min(row[c] for row in raw_matrix) for c in range(n_props)]
col_max = [max(row[c] for row in raw_matrix) for c in range(n_props)]
norm_matrix = []
for row in raw_matrix:
norm_row = []
for c in range(n_props):
rng = col_max[c] - col_min[c]
norm_row.append((row[c] - col_min[c]) / rng if rng else 0.5)
norm_matrix.append(norm_row)
heatmap_labels = [m["name"] for m in molecules_data]
heatmap = _make_heatmap(
norm_matrix, heatmap_labels, prop_names,
title="Normalized Property Heatmap",
color_scale="cyan",
width=700,
height=max(400, len(heatmap_labels) * 28 + 100),
)
html_parts.append("
")
for m in molecules_data:
lip = m["lipinski"]
def _badge(ok):
if ok:
return 'Pass'
return 'Fail'
overall_badge = _badge(m["lipinski_pass"])
html_parts.append(
f'
{m["name"]}
'
f'
{_badge(lip["mw_ok"])}
'
f'
{_badge(lip["logp_ok"])}
'
f'
{_badge(lip["hbd_ok"])}
'
f'
{_badge(lip["hba_ok"])}
'
f'
{overall_badge}
'
)
html_parts.append("
")
# QED bar chart
sorted_by_qed = sorted(molecules_data, key=lambda m: m["qed"], reverse=True)
qed_labels = [m["name"] for m in sorted_by_qed]
qed_vals = [m["qed"] for m in sorted_by_qed]
qed_chart = _make_bar_chart(
qed_labels, {"QED Score": qed_vals},
title="Drug-likeness (QED Score)",
horizontal=True,
width=700, height=max(300, len(qed_labels) * 30 + 80),
value_fmt=".3f",
colors=["#06d6a0"],
)
html_parts.append("
Drug-likeness (QED)
")
html_parts.append(f'
{qed_chart}
')
# Flush full report
await flyte.report.replace.aio(
_wrap_report("\n".join(html_parts)),
do_flush=True,
)
# Return properties as JSON (strip image data URIs to reduce size)
output = {
"total": total,
"lipinski_pass_count": lipinski_pass,
"lipinski_pass_rate": round(lipinski_rate, 2),
"avg_mw": round(avg_mw, 2),
"avg_logp": round(avg_logp, 2),
"molecules": [
{k: v for k, v in m.items() if k != "image_data_uri"}
for m in molecules_data
],
}
return json.dumps(output)
# ------------------------------------------------------------------
# Task 3: Screen candidates against target profile
# ------------------------------------------------------------------
@tool
@env.task(report=True)
async def screen_candidates(
properties_json: str,
target_profile: str = "",
) -> str:
"""Screen molecules against a target drug profile and rank candidates.
Scores each molecule on how well it matches the target profile, computes
pairwise Tanimoto similarity, and produces a ranked list.
Args:
properties_json: JSON from compute_properties.
target_profile: JSON string with desired property ranges
(e.g. {"mw": [150, 500], "logp": [-0.5, 5.0]}).
Returns:
JSON string with ranked_molecules, similarity_matrix, similarity_labels,
funnel, and target_profile. Pass the full return value verbatim to
generate_report along with molecule_dir and properties_json.
"""
from rdkit import Chem, DataStructs
from rdkit.Chem import AllChem
await flyte.report.replace.aio(
_wrap_report("
Screening Candidates...
"
"
Evaluating molecules against the target drug profile.
"),
do_flush=True,
)
props = json.loads(properties_json)
molecules = props["molecules"]
# Default target profile
if target_profile.strip():
profile = json.loads(target_profile)
else:
profile = {
"mw": [150, 500],
"logp": [-0.5, 5.0],
"hbd": [0, 5],
"hba": [0, 10],
"tpsa": [20, 140],
}
# --- Screening ---
funnel_total = len(molecules)
pass_mw = 0
pass_logp = 0
pass_lipinski = 0
final_candidates = 0
scored = []
for m in molecules:
score = 0
max_score = 0
criteria = {}
# Check each profile criterion
checks = [
("mw", m["mw"]),
("logp", m["logp"]),
("hbd", m["hbd"]),
("hba", m["hba"]),
("tpsa", m["tpsa"]),
]
for key, val in checks:
if key in profile:
lo, hi = profile[key]
max_score += 1
in_range = lo <= val <= hi
criteria[key] = in_range
if in_range:
score += 1
# Bonus: closer to midpoint = higher score
mid = (lo + hi) / 2
rng = (hi - lo) / 2
dist = abs(val - mid) / rng if rng else 0
score += max(0, 0.5 * (1 - dist))
# QED bonus
score += m["qed"] * 2
max_score += 2
# Lipinski bonus
if m["lipinski_pass"]:
score += 1
max_score += 1
normalized_score = score / max_score if max_score else 0
# Funnel tracking — cascading filter (each stage requires passing the previous)
mw_ok = criteria.get("mw", True)
logp_ok = criteria.get("logp", True)
if mw_ok:
pass_mw += 1
if logp_ok:
pass_logp += 1
if m["lipinski_pass"]:
pass_lipinski += 1
if all(criteria.values()):
final_candidates += 1
scored.append({
**m,
"screening_score": round(normalized_score, 4),
"criteria_met": criteria,
"all_criteria_met": all(criteria.values()),
})
# Sort by score descending
scored.sort(key=lambda m: m["screening_score"], reverse=True)
# --- Tanimoto similarity matrix ---
fps = []
valid_names = []
for m in scored:
mol = Chem.MolFromSmiles(m["smiles"])
if mol:
fp = AllChem.GetMorganFingerprintAsBitVect(mol, 2, nBits=2048)
fps.append(fp)
valid_names.append(m["name"])
similarity_matrix = []
for i in range(len(fps)):
row = []
for j in range(len(fps)):
sim = DataStructs.TanimotoSimilarity(fps[i], fps[j])
row.append(round(sim, 3))
similarity_matrix.append(row)
# ---- Build report ----
html_parts = []
html_parts.append("
Candidate Screening Results
")
# Stat grid
html_parts.append('
')
for val, label in [
(str(funnel_total), "Total Screened"),
(str(pass_lipinski), "Lipinski Passes"),
(str(final_candidates), "All Criteria Met"),
(f"{scored[0]['screening_score']:.3f}" if scored else "N/A", "Top Score"),
]:
html_parts.append(
f'
"
)
for rank, m in enumerate(scored, 1):
lip_badge = ('Pass'
if m["lipinski_pass"]
else 'Fail')
crit_badge = ('Pass'
if m["all_criteria_met"]
else 'Fail')
# Highlight top 3
row_style = ' style="background:#ecfeff;font-weight:600;"' if rank <= 3 else ""
html_parts.append(
f"
{rank}
{m['name']}
"
f"
{m['screening_score']:.3f}
"
f"
{m['mw']:.1f}
{m['logp']:.2f}
"
f"
{m['qed']:.3f}
{lip_badge}
{crit_badge}
"
)
html_parts.append("
")
# Top 5 candidate cards with structures
html_parts.append("
Top 5 Candidates
")
html_parts.append('
')
for m in scored[:5]:
mol = Chem.MolFromSmiles(m["smiles"])
img_uri = _mol_to_data_uri(mol, size=(250, 250)) if mol else ""
badge_class = "badge-success" if m["all_criteria_met"] else "badge-info"
badge_text = "All Criteria Met" if m["all_criteria_met"] else "Partial Match"
html_parts.append(
f'
')
await flyte.report.replace.aio(
_wrap_report("\n".join(html_parts)),
do_flush=True,
)
output = {
"ranked_molecules": scored,
"similarity_matrix": similarity_matrix,
"similarity_labels": valid_names,
"funnel": funnel_stages,
"target_profile": profile,
}
return json.dumps(output)
def _parse_screening_json(screening_json: str) -> dict:
"""Parse screening JSON from screen_candidates, with safe defaults.
The agent must pass the exact tool return value. Partial or hand-built JSON
is tolerated for optional similarity fields only.
"""
screening = json.loads(screening_json)
if "ranked_molecules" not in screening:
raise ValueError(
"screening_json must be the exact JSON string returned by "
"screen_candidates (missing 'ranked_molecules'). Do not construct, "
"truncate, or summarize tool output."
)
screening.setdefault("similarity_matrix", [])
screening.setdefault("similarity_labels", [])
return screening
# ------------------------------------------------------------------
# Task 4: Generate final comprehensive report
# ------------------------------------------------------------------
@tool
@env.task(report=True)
async def generate_report(
molecule_dir: flyte.io.Dir,
properties_json: str,
screening_json: str,
) -> str:
"""Generate a comprehensive drug screening report.
Produces an executive summary, top candidate spotlight cards, property
distributions, chemical diversity analysis, and final recommendation.
Args:
molecule_dir: Directory from load_molecules.
properties_json: JSON from compute_properties.
screening_json: Exact verbatim JSON string returned by screen_candidates
(must include ranked_molecules, similarity_matrix, similarity_labels).
Do not construct or summarize this payload yourself.
Returns:
JSON summary with total_screened, lipinski_passes, all_criteria_met,
top_candidate, top_score, and top_3 ranked molecules.
"""
from rdkit import Chem
await flyte.report.replace.aio(
_wrap_report("
Generating Final Report...
"),
do_flush=True,
)
props = json.loads(properties_json)
screening = _parse_screening_json(screening_json)
ranked = screening["ranked_molecules"]
sim_matrix = screening["similarity_matrix"]
sim_labels = screening["similarity_labels"]
total = props["total"]
lipinski_pass = props["lipinski_pass_count"]
all_criteria = sum(1 for m in ranked if m["all_criteria_met"])
top = ranked[0] if ranked else None
html_parts = []
# --- Executive Summary ---
html_parts.append("
Drug Molecule Screening Report
")
top_name = top["name"] if top else "N/A"
top_score = f'{top["screening_score"]:.3f}' if top else "N/A"
html_parts.append(
f'
'
f'
Executive Summary
'
f'
'
f'{total} molecules were screened against the target drug profile. '
f'{lipinski_pass} passed Lipinski\'s Rule of Five, and '
f'{all_criteria} met all screening criteria. '
f'The top candidate is {top_name} '
f'with a screening score of {top_score}.
'
f'
'
)
# Stat grid
html_parts.append('
')
for val, label in [
(str(total), "Molecules Screened"),
(str(lipinski_pass), "Lipinski Passes"),
(str(all_criteria), "All Criteria Met"),
(top_score, "Top Score"),
(f'{props["avg_mw"]:.0f} Da', "Avg. Molecular Weight"),
(f'{props["avg_logp"]:.2f}', "Avg. LogP"),
]:
html_parts.append(
f'
{val}
'
f'
{label}
'
)
html_parts.append("
")
# --- Top 3 Candidate Spotlights ---
html_parts.append("
Top Candidate Spotlights
")
for rank, m in enumerate(ranked[:3], 1):
mol = Chem.MolFromSmiles(m["smiles"])
img_uri = _mol_to_data_uri(mol, size=(300, 300)) if mol else ""
medal = ["gold", "silver", "#cd7f32"][rank - 1]
medal_emoji = ["1st", "2nd", "3rd"][rank - 1]
lip_badges = ""
for rule, key in [("MW", "mw_ok"), ("LogP", "logp_ok"),
("HBD", "hbd_ok"), ("HBA", "hba_ok")]:
ok = m["lipinski"].get(key, False)
cls = "badge-success" if ok else "badge-danger"
lip_badges += f'{rule} '
html_parts.append(
f'
'
f'
'
f'
{medal_emoji}
'
f''
f'
{m["name"]}
'
f'
'
f'
'
f'
'
f'
SMILES
{m["smiles"]}
'
f'
Screening Score
{m["screening_score"]:.3f}
'
f'
Molecular Weight
{m["mw"]:.1f} Da
'
f'
LogP
{m["logp"]:.2f}
'
f'
H-Bond Donors
{m["hbd"]}
'
f'
H-Bond Acceptors
{m["hba"]}
'
f'
TPSA
{m["tpsa"]:.1f} A²
'
f'
Rotatable Bonds
{m["rotatable_bonds"]}
'
f'
QED
{m["qed"]:.4f}
'
f'
Lipinski Compliance
{lip_badges}
'
f'
'
f'
'
f'
'
)
# --- Property Distribution (box-plot style as bars with min/max/median) ---
html_parts.append("
Property Distributions
")
prop_keys = [("mw", "Molecular Weight (Da)"), ("logp", "LogP"),
("tpsa", "TPSA"), ("qed", "QED Score")]
for key, label in prop_keys:
vals = sorted([m[key] for m in ranked])
n = len(vals)
if n == 0:
continue
v_min = vals[0]
v_max = vals[-1]
median = vals[n // 2] if n % 2 == 1 else (vals[n // 2 - 1] + vals[n // 2]) / 2
q1 = vals[n // 4] if n >= 4 else v_min
q3 = vals[3 * n // 4] if n >= 4 else v_max
# Simple horizontal box-plot as SVG
box_w = 500
box_h = 50
margin_l = 10
v_range = v_max - v_min or 1
def sx(v):
return margin_l + ((v - v_min) / v_range) * (box_w - 2 * margin_l)
box_svg = (
f''
)
html_parts.append(
f'
{label}'
f'
{box_svg}
'
)
# --- Chemical Diversity ---
html_parts.append("
Chemical Diversity Analysis
")
if sim_matrix and len(sim_matrix) > 1:
# Compute average pairwise similarity (off-diagonal)
n_mols = len(sim_matrix)
off_diag = []
for i in range(n_mols):
for j in range(i + 1, n_mols):
off_diag.append(sim_matrix[i][j])
avg_sim = sum(off_diag) / len(off_diag) if off_diag else 0
max_sim = max(off_diag) if off_diag else 0
min_sim = min(off_diag) if off_diag else 0
# Find most similar pair
best_i, best_j = 0, 1
best_val = 0
for i in range(n_mols):
for j in range(i + 1, n_mols):
if sim_matrix[i][j] > best_val:
best_val = sim_matrix[i][j]
best_i, best_j = i, j
html_parts.append('
')
html_parts.append(
f'
{avg_sim:.3f}
'
f'
Avg. Pairwise Similarity
'
)
html_parts.append(
f'
{min_sim:.3f}
'
f'
Min Similarity
'
)
html_parts.append(
f'
{max_sim:.3f}
'
f'
Max Similarity
'
)
html_parts.append("
")
diversity_text = "highly diverse" if avg_sim < 0.3 else "moderately diverse" if avg_sim < 0.5 else "relatively similar"
html_parts.append(
f'
'
f'The library is {diversity_text} (avg. Tanimoto = {avg_sim:.3f}). '
f'The most similar pair is {sim_labels[best_i]} and '
f'{sim_labels[best_j]} (similarity = {best_val:.3f}).
'
)
# --- Recommendation ---
html_parts.append("
Recommendation
")
if top:
html_parts.append(
f'
'
f'
Top Candidate: {top["name"]}
'
f'
Based on the virtual screening analysis, {top["name"]} '
f'achieved the highest composite screening score of {top["screening_score"]:.3f}. '
)
reasons = []
if top["lipinski_pass"]:
reasons.append("full Lipinski Rule of Five compliance")
if top["qed"] > 0.5:
reasons.append(f"high drug-likeness (QED = {top['qed']:.3f})")
if top.get("all_criteria_met"):
reasons.append("all target profile criteria met")
if top["mw"] <= 500:
reasons.append(f"favorable molecular weight ({top['mw']:.1f} Da)")
if reasons:
html_parts.append(
f'This candidate stands out due to: {", ".join(reasons)}.
'
)
else:
html_parts.append("")
# Runner-up mentions
if len(ranked) >= 2:
html_parts.append(
f'
Runner-up candidates: '
)
runners = []
for m in ranked[1:4]:
runners.append(f'{m["name"]} (score: {m["screening_score"]:.3f})')
html_parts.append(", ".join(runners) + ".
")
html_parts.append("
")
# Final note
html_parts.append(
'
'
"This is a virtual screening analysis. All candidates should undergo "
"further computational validation (molecular dynamics, docking) and "
"experimental testing before advancing to clinical trials.
"
)
await flyte.report.replace.aio(
_wrap_report("\n".join(html_parts)),
do_flush=True,
)
# JSON summary
summary = {
"total_screened": total,
"lipinski_passes": lipinski_pass,
"all_criteria_met": all_criteria,
"top_candidate": top["name"] if top else None,
"top_score": top["screening_score"] if top else None,
"top_3": [
{"name": m["name"], "score": m["screening_score"]}
for m in ranked[:3]
],
}
return json.dumps(summary)
# ------------------------------------------------------------------
# Agent
# ------------------------------------------------------------------
# {{docs-fragment agent}}
SCREENING_AGENT_INSTRUCTIONS = """\
You are a medicinal chemistry screening strategist. You orchestrate a virtual \
screening pipeline using durable Flyte tools. You NEVER invent molecular \
properties — only RDKit tools compute them.
Workflow:
1. If target_profile is not provided in the user message, derive a JSON \
target_profile from the therapeutic brief. Valid keys: mw, logp, hbd, hba, tpsa \
(each [min, max]). Ground choices in oral bioavailability / kinase / CNS rules \
as appropriate to the brief.
2. First pass (always): load_molecules → compute_properties → \
screen_candidates → generate_report. Pass tool outputs between steps exactly \
(molecule_dir from load_molecules into compute_properties and generate_report; \
properties_json from compute_properties into screen_candidates and \
generate_report; screening_json must be the complete, unmodified string \
returned by screen_candidates — never rebuild or summarize JSON yourself).
3. Read the JSON summary returned by generate_report. Reflect:
- If all_criteria_met == 0: relax exactly ONE profile bound by ~10–20% \
and re-run screen_candidates then generate_report only, reusing the same \
molecule_dir and properties_json from the first pass.
- If all molecules pass but diversity is a stated goal: note high similarity \
in your summary; do not re-run unless brief asks for stricter filters.
- Maximum ONE rescreen iteration.
4. Finish with plain text: top candidate, rationale tied to computed metrics \
from the tool JSON, funnel interpretation, and suggested next steps (docking, \
ADMET lab tests).
If the user supplies an explicit target_profile JSON, use it as-is.
Do NOT ask the user for SMILES or molecule lists when molecules_json is empty — \
the default library is loaded automatically.
"""
screening_agent = Agent(
name="drug-screening-agent",
instructions=SCREENING_AGENT_INSTRUCTIONS,
model=MODEL,
tools=[
load_molecules,
compute_properties,
screen_candidates,
generate_report,
],
max_turns=12,
)
# {{/docs-fragment agent}}
# ------------------------------------------------------------------
# Pipeline
# ------------------------------------------------------------------
# {{docs-fragment pipeline}}
@env.task(report=True)
async def pipeline(
brief: str = "Screen the default drug library for orally bioavailable small molecules.",
molecules_json: str = "",
target_profile: str = "",
) -> str:
"""Agentic virtual drug molecule screening pipeline.
A medicinal-chemistry agent interprets the screening brief, derives or
applies a target profile, orchestrates the RDKit screening stages, and
optionally re-screens when funnel results are too narrow.
Args:
brief: Natural-language therapeutic goal (e.g. oral kinase inhibitors,
CNS-penetrant small molecules).
molecules_json: JSON mapping molecule names to SMILES strings.
Defaults to a curated library of ~15 well-known drugs.
target_profile: Optional JSON with desired property ranges that
overrides agent-derived criteria
(e.g. {"mw": [150, 500], "logp": [-0.5, 5]}).
Returns:
Agent summary with screening rationale and key results.
"""
prompt_parts = [
f"Screening brief: {brief}",
'Use molecules_json="" for the built-in default library unless provided below.',
"Compose the four stage tools in order: load_molecules → compute_properties "
"→ screen_candidates → generate_report. Pass each tool's full return value "
"verbatim to the next step (especially screening_json). Re-run "
"screen_candidates and generate_report at most once if the funnel is too narrow.",
]
if molecules_json.strip():
prompt_parts.append(f"molecules_json: {molecules_json}")
if target_profile.strip():
prompt_parts.append(f"Use this target_profile exactly: {target_profile}")
result = await screening_agent.run.aio("\n".join(prompt_parts))
return result.summary or result.error or ""
# {{/docs-fragment pipeline}}
# ------------------------------------------------------------------
# Rescreen demo — tight profile + explicit rescreen instructions
# ------------------------------------------------------------------
# Initial profile is deliberately strict (narrow MW + low LogP cap) so
# all_criteria_met is typically 0 on the default library; the brief then
# forces a single rescreen with a widened LogP window.
RESCREEN_DEMO_TARGET_PROFILE = (
'{"mw": [150, 200], "logp": [-0.5, 1.0], "hbd": [0, 1], '
'"hba": [0, 3], "tpsa": [20, 45]}'
)
RESCREEN_DEMO_TARGET_PROFILE_RESCREEN = (
'{"mw": [150, 200], "logp": [-0.5, 3.5], "hbd": [0, 1], '
'"hba": [0, 3], "tpsa": [20, 45]}'
)
RESCREEN_DEMO_BRIEF = f"""\
Two-round agentic screening demo on the default library.
**Round 1 (strict profile):** load_molecules → compute_properties → \
screen_candidates → generate_report using the initial target_profile exactly.
**Round 2 (required — do not skip):** call screen_candidates then generate_report \
again, reusing the same molecule_dir and properties_json from round 1, with this \
relaxed target_profile (wider LogP window only): \
{RESCREEN_DEMO_TARGET_PROFILE_RESCREEN}
Pass every tool return value verbatim to the next step. After both rounds, \
summarize how the funnel and top candidates changed between round 1 and round 2."""
# {{docs-fragment rescreen_demo}}
@env.task(report=True)
async def rescreen_demo() -> str:
"""Example run with a two-round execution graph (rescreen).
Round 1 uses a strict CNS-like profile; round 2 always re-runs
screen_candidates and generate_report with a widened LogP window,
reusing cached molecule_dir and properties_json.
"""
return await pipeline(
brief=RESCREEN_DEMO_BRIEF,
target_profile=RESCREEN_DEMO_TARGET_PROFILE,
)
# {{/docs-fragment rescreen_demo}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(pipeline)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/drug_molecule_screening/drug_molecule_screening.py*
```
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flyte>=2.5.4",
# "litellm",
# "rdkit",
# "numpy",
# "scikit-learn",
# "pillow",
# ]
# ///
```
## Define the screening agent
The agent receives a natural-language brief and composes four stage tools in order. Each tool is a durable Flyte task with its own `report=True` surface in the Flyte UI.
```
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flyte>=2.5.4",
# "litellm",
# "rdkit",
# "numpy",
# "scikit-learn",
# "pillow",
# ]
# main = "pipeline"
# params = ""
# ///
"""Virtual drug molecule screening — compute properties, apply Lipinski filters, rank candidates."""
import base64
import io
import json
import logging
import math
import os
import tempfile
import flyte
import flyte.io
import flyte.report
from flyte.ai.agents import Agent, tool
MODEL = os.getenv("DRUG_SCREENING_MODEL", "claude-haiku-4-5")
# {{docs-fragment env}}
main_img = flyte.Image.from_uv_script(__file__, name="drug-molecule-screening", pre=True).with_apt_packages(
"libxrender1", "libxext6", "libexpat1",
)
env = flyte.TaskEnvironment(
name="drug-molecule-screening",
image=main_img,
resources=flyte.Resources(cpu=2, memory="6Gi"),
secrets=[
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
)
# {{/docs-fragment env}}
logging.basicConfig(level=logging.WARNING, format="%(message)s", force=True)
log = logging.getLogger(__name__)
log.setLevel(logging.INFO)
# ------------------------------------------------------------------
# Default molecule library — real SMILES for well-known drugs
# ------------------------------------------------------------------
DEFAULT_MOLECULES = {
"Aspirin": "CC(=O)OC1=CC=CC=C1C(=O)O",
"Ibuprofen": "CC(C)CC1=CC=C(C=C1)C(C)C(=O)O",
"Caffeine": "CN1C=NC2=C1C(=O)N(C(=O)N2C)C",
"Penicillin G": "CC1(C(N2C(S1)C(C2=O)NC(=O)CC3=CC=CC=C3)C(=O)O)C",
"Metformin": "CN(C)C(=N)NC(=N)N",
"Paracetamol": "CC(=O)NC1=CC=C(C=C1)O",
"Diazepam": "ClC1=CC2=C(C=C1)N(C(=O)CN=C2C3=CC=CC=C3)C",
"Omeprazole": "CC1=CN=C(C(=C1OC)C)CS(=O)C2=NC3=CC=CC=C3N2",
"Atorvastatin": "CC(C)C1=C(C(=C(N1CCC(CC(CC(=O)O)O)O)C2=CC=C(C=C2)F)C3=CC=CC=C3)C(=O)NC4=CC=CC=C4",
"Methotrexate": "CN(CC1=CN=C2N=C(N=C(N)C2=N1)N)C3=CC=C(C=C3)C(=O)NC(CCC(=O)O)C(=O)O",
"Doxorubicin": "CC1C(C(CC(O1)OC2CC(CC3=C2C(=C4C(=C3O)C(=O)C5=C(C4=O)C(=CC=C5)OC)O)(C(=O)CO)O)N)O",
"Tamoxifen": "CCC(=C(C1=CC=CC=C1)C2=CC=C(C=C2)OCCN(C)C)C3=CC=CC=C3",
"Lopinavir": "CC1=C(C(=CC=C1)C)OCC(=O)NC(CC2=CC=CC=C2)C(CC(CC3=CC=CC=C3)NC(=O)C(C(C)C)N4CCCNC4=O)O",
"Remdesivir": "CCC(CC)COC(=O)C(C)NP(=O)(OCC1C(C(C(O1)C2=CC=C3N2N=CN=C3N)O)O)OC4=CC=CC=C4",
"Erlotinib": "COCCOC1=CC2=C(C=C1OCCOC)C(=NC=N2)NC3=CC=CC(=C3)C#C",
}
# ------------------------------------------------------------------
# Report styling — pharma blue/cyan theme
# ------------------------------------------------------------------
REPORT_CSS = """
"""
def _wrap_report(html: str) -> str:
"""Wrap HTML content with report styling."""
return f'{REPORT_CSS}
{html}
'
# ------------------------------------------------------------------
# SVG chart helpers
# ------------------------------------------------------------------
def _mol_to_data_uri(mol, size: tuple[int, int] = (300, 300)) -> str:
"""Convert an RDKit molecule to a PNG base64 data URI."""
from rdkit.Chem import Draw
img = Draw.MolToImage(mol, size=size)
buf = io.BytesIO()
img.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode()
return f"data:image/png;base64,{b64}"
def _make_bar_chart(
labels: list[str],
series: dict[str, list[float]],
title: str = "",
colors: list[str] | None = None,
width: int = 700,
height: int = 340,
y_max_cap: float | None = None,
horizontal: bool = False,
value_fmt: str = ".1f",
) -> str:
"""Generate an SVG grouped bar chart.
Args:
labels: Category labels.
series: Dict mapping series name to list of values.
title: Chart title.
colors: Colors for each series.
width/height: SVG dimensions.
y_max_cap: Cap the y-axis at this value.
horizontal: If True, draw horizontal bars.
value_fmt: Format string for value labels.
Returns:
SVG string.
"""
if not labels:
return ""
default_colors = ["#0891b2", "#0e4f6e", "#06d6a0", "#a5f3fc", "#155e75"]
colors = colors or default_colors
if horizontal:
return _make_horizontal_bar_chart(labels, series, title, colors, width, height, value_fmt)
ml, mr, mt, mb = 60, 20, 40, 60
cw = width - ml - mr
ch = height - mt - mb
all_vals = [v for vals in series.values() for v in vals]
y_max = max(all_vals) if all_vals else 1
y_max_plot = y_max * 1.15 or 1
if y_max_cap is not None:
y_max_plot = min(y_max_plot, y_max_cap) or y_max_cap
n_groups = len(labels)
n_series = len(series)
group_width = cw / n_groups
bar_width = group_width * 0.7 / max(n_series, 1)
gap = group_width * 0.15
def sy(v):
return mt + ch - (v / y_max_plot) * ch
svg = [
f'")
return "\n".join(svg)
def _make_horizontal_bar_chart(
labels: list[str],
series: dict[str, list[float]],
title: str = "",
colors: list[str] | None = None,
width: int = 700,
height: int = 400,
value_fmt: str = ".1f",
) -> str:
"""Generate an SVG horizontal bar chart (sorted)."""
default_colors = ["#0891b2", "#0e4f6e", "#06d6a0"]
colors = colors or default_colors
n = len(labels)
row_height = max(22, min(35, (height - 80) // max(n, 1)))
actual_height = max(height, 80 + n * row_height)
ml, mr, mt, mb = 120, 60, 40, 20
cw = width - ml - mr
ch = actual_height - mt - mb
# Use first series
first_key = list(series.keys())[0]
vals = series[first_key]
x_max = max(vals) * 1.15 if vals else 1
svg = [
f'")
return "\n".join(svg)
def _make_heatmap(
matrix: list[list[float]],
row_labels: list[str],
col_labels: list[str],
title: str = "",
color_scale: str = "cyan",
width: int = 700,
height: int = 500,
value_fmt: str = ".2f",
) -> str:
"""Generate an SVG heatmap.
Args:
matrix: 2D list of values (rows x cols).
row_labels: Labels for rows.
col_labels: Labels for columns.
title: Chart title.
color_scale: Color scheme ("cyan", "red", "green").
width/height: SVG dimensions.
value_fmt: Format string for cell values.
Returns:
SVG string.
"""
if not matrix or not matrix[0]:
return ""
n_rows = len(matrix)
n_cols = len(matrix[0])
ml, mr, mt, mb = 110, 20, 70, 20
cw = width - ml - mr
ch = height - mt - mb
cell_w = cw / n_cols
cell_h = ch / n_rows
# Flatten to find range
flat = [v for row in matrix for v in row]
v_min = min(flat)
v_max = max(flat)
v_range = v_max - v_min or 1
def color_for(v):
t = (v - v_min) / v_range
if color_scale == "cyan":
# White to deep teal
r = int(255 - t * (255 - 14))
g = int(255 - t * (255 - 79))
b = int(255 - t * (255 - 110))
elif color_scale == "red":
r = int(255 - t * 50)
g = int(255 - t * 200)
b = int(255 - t * 200)
else: # green
r = int(255 - t * 200)
g = int(255 - t * 50)
b = int(255 - t * 200)
return f"rgb({r},{g},{b})"
svg = [
f'")
return "\n".join(svg)
def _make_scatter_plot(
points: list[dict],
x_label: str = "MW",
y_label: str = "LogP",
title: str = "",
reference_lines: list[dict] | None = None,
width: int = 700,
height: int = 400,
) -> str:
"""Generate an SVG scatter plot.
Args:
points: List of dicts with "x", "y", "label" keys.
x_label/y_label: Axis labels.
title: Chart title.
reference_lines: List of dicts with "axis" ("x"/"y"), "value", "label".
width/height: SVG dimensions.
Returns:
SVG string.
"""
if not points:
return ""
ml, mr, mt, mb = 60, 30, 40, 50
cw = width - ml - mr
ch = height - mt - mb
x_vals = [p["x"] for p in points]
y_vals = [p["y"] for p in points]
x_min, x_max = min(x_vals) * 0.9, max(x_vals) * 1.1
y_min, y_max = min(y_vals) - 1, max(y_vals) + 1
# Extend ranges to include reference lines
if reference_lines:
for rl in reference_lines:
if rl["axis"] == "x":
x_max = max(x_max, rl["value"] * 1.1)
else:
y_max = max(y_max, rl["value"] * 1.1)
x_range = x_max - x_min or 1
y_range = y_max - y_min or 1
def sx(v):
return ml + (v - x_min) / x_range * cw
def sy(v):
return mt + ch - (v - y_min) / y_range * ch
svg = [
f'")
return "\n".join(svg)
def _make_funnel(
stages: list[dict],
title: str = "",
width: int = 600,
height: int = 400,
) -> str:
"""Generate an SVG funnel visualization.
Args:
stages: List of dicts with "label", "count", "total" keys.
title: Chart title.
width/height: SVG dimensions.
Returns:
SVG string.
"""
if not stages:
return ""
n = len(stages)
mt = 50
mb = 20
available_h = height - mt - mb
stage_h = available_h / n
cx = width / 2
# Color gradient from light cyan to deep teal
colors = []
for i in range(n):
t = i / max(n - 1, 1)
r = int(207 - t * (207 - 14))
g = int(250 - t * (250 - 79))
b = int(254 - t * (254 - 110))
colors.append(f"rgb({r},{g},{b})")
svg = [
f'")
return "\n".join(svg)
# ------------------------------------------------------------------
# Task 1: Load and validate molecules
# ------------------------------------------------------------------
@tool
@env.task(cache="auto")
async def load_molecules(
molecules_json: str = "",
) -> flyte.io.Dir:
"""Parse SMILES strings, validate with RDKit, generate 2D depictions.
Args:
molecules_json: JSON string mapping molecule names to SMILES.
Defaults to a curated library of ~15 well-known drugs.
Returns:
flyte.io.Dir containing molecule data (JSON + PNG depictions).
Pass this directory to compute_properties and generate_report.
"""
from rdkit import Chem
from rdkit.Chem import Draw
if molecules_json.strip():
molecules = json.loads(molecules_json)
else:
molecules = DEFAULT_MOLECULES
out_dir = tempfile.mkdtemp(prefix="mol_library_")
results = []
valid_count = 0
invalid_count = 0
log.info(f"Parsing {len(molecules)} molecules...")
for name, smiles in molecules.items():
mol = Chem.MolFromSmiles(smiles)
if mol is None:
log.warning(f" [INVALID] {name}: {smiles}")
invalid_count += 1
continue
valid_count += 1
# Generate 2D depiction as PNG
img = Draw.MolToImage(mol, size=(300, 300))
img_path = os.path.join(out_dir, f"{name.replace(' ', '_')}.png")
img.save(img_path)
results.append({
"name": name,
"smiles": smiles,
"valid": True,
"image_file": os.path.basename(img_path),
})
# Save molecule manifest
manifest = {
"total": len(molecules),
"valid": valid_count,
"invalid": invalid_count,
"molecules": results,
}
manifest_path = os.path.join(out_dir, "manifest.json")
with open(manifest_path, "w") as f:
json.dump(manifest, f, indent=2)
log.info(f"Loaded {valid_count} valid molecules ({invalid_count} invalid)")
return await flyte.io.Dir.from_local(out_dir)
# ------------------------------------------------------------------
# Task 2: Compute physicochemical properties
# ------------------------------------------------------------------
@tool
@env.task(report=True)
async def compute_properties(
molecule_dir: flyte.io.Dir,
) -> str:
"""Compute drug-likeness properties for all molecules.
Computes MW, LogP, HBD, HBA, TPSA, rotatable bonds, formal charge,
ring count, QED, and Lipinski Rule of Five compliance.
Args:
molecule_dir: Directory from load_molecules.
Returns:
JSON string with all computed properties. Pass to screen_candidates
and generate_report.
"""
from rdkit import Chem
from rdkit.Chem import Descriptors, Lipinski
from rdkit.Chem.QED import qed
# --- Loading report ---
await flyte.report.replace.aio(
_wrap_report("
Computing Molecular Properties...
"
"
Analyzing physicochemical descriptors for all molecules.
"),
do_flush=True,
)
mol_dir = await molecule_dir.download()
with open(os.path.join(mol_dir, "manifest.json")) as f:
manifest = json.load(f)
molecules_data = []
lipinski_pass = 0
for mol_info in manifest["molecules"]:
mol = Chem.MolFromSmiles(mol_info["smiles"])
if mol is None:
continue
mw = Descriptors.MolWt(mol)
logp = Descriptors.MolLogP(mol)
hbd = Lipinski.NumHDonors(mol)
hba = Lipinski.NumHAcceptors(mol)
tpsa = Descriptors.TPSA(mol)
rotatable = Lipinski.NumRotatableBonds(mol)
formal_charge = Chem.GetFormalCharge(mol)
num_rings = Lipinski.RingCount(mol)
qed_score = qed(mol)
# Lipinski Rule of Five
lipinski = {
"mw_ok": mw <= 500,
"logp_ok": logp <= 5,
"hbd_ok": hbd <= 5,
"hba_ok": hba <= 10,
}
lipinski_all = all(lipinski.values())
if lipinski_all:
lipinski_pass += 1
# Read image for data URI
img_path = os.path.join(mol_dir, mol_info["image_file"])
data_uri = ""
if os.path.exists(img_path):
with open(img_path, "rb") as img_f:
b64 = base64.b64encode(img_f.read()).decode()
data_uri = f"data:image/png;base64,{b64}"
molecules_data.append({
"name": mol_info["name"],
"smiles": mol_info["smiles"],
"mw": round(mw, 2),
"logp": round(logp, 2),
"hbd": hbd,
"hba": hba,
"tpsa": round(tpsa, 2),
"rotatable_bonds": rotatable,
"formal_charge": formal_charge,
"num_rings": num_rings,
"qed": round(qed_score, 4),
"lipinski": lipinski,
"lipinski_pass": lipinski_all,
"image_data_uri": data_uri,
})
total = len(molecules_data)
avg_mw = sum(m["mw"] for m in molecules_data) / total if total else 0
avg_logp = sum(m["logp"] for m in molecules_data) / total if total else 0
lipinski_rate = lipinski_pass / total * 100 if total else 0
# ---- Build report ----
html_parts = []
# Header
html_parts.append("
Molecular Properties Analysis
")
# Stat grid
html_parts.append('
')
for val, label in [
(str(total), "Total Molecules"),
(f"{lipinski_rate:.0f}%", "Lipinski Pass Rate"),
(f"{avg_mw:.1f}", "Avg. MW (Da)"),
(f"{avg_logp:.2f}", "Avg. LogP"),
]:
html_parts.append(
f'
{val}
'
f'
{label}
'
)
html_parts.append("
")
# Molecule gallery
html_parts.append("
Molecule Library
")
html_parts.append('
')
for m in molecules_data:
if m["image_data_uri"]:
badge_class = "badge-success" if m["lipinski_pass"] else "badge-danger"
badge_text = "Lipinski Pass" if m["lipinski_pass"] else "Lipinski Fail"
html_parts.append(
f'
'
f''
f'
{m["name"]}
'
f'
MW: {m["mw"]:.1f} | LogP: {m["logp"]:.2f}
'
f'
{badge_text}
'
f'
'
)
html_parts.append("
")
# MW bar chart (horizontal, sorted)
sorted_by_mw = sorted(molecules_data, key=lambda m: m["mw"], reverse=True)
mw_labels = [m["name"] for m in sorted_by_mw]
mw_vals = [m["mw"] for m in sorted_by_mw]
mw_chart = _make_bar_chart(
mw_labels, {"MW (Da)": mw_vals},
title="Molecular Weight Distribution",
horizontal=True,
width=700, height=max(300, len(mw_labels) * 30 + 80),
value_fmt=".1f",
)
html_parts.append("
')
# Property heatmap (molecules x properties)
prop_names = ["MW", "LogP", "HBD", "HBA", "TPSA", "Rot. Bonds"]
# Normalize each property to 0-1 for heatmap
raw_matrix = []
for m in molecules_data:
raw_matrix.append([m["mw"], m["logp"], m["hbd"], m["hba"], m["tpsa"], m["rotatable_bonds"]])
# Normalize per column
n_props = len(prop_names)
col_min = [min(row[c] for row in raw_matrix) for c in range(n_props)]
col_max = [max(row[c] for row in raw_matrix) for c in range(n_props)]
norm_matrix = []
for row in raw_matrix:
norm_row = []
for c in range(n_props):
rng = col_max[c] - col_min[c]
norm_row.append((row[c] - col_min[c]) / rng if rng else 0.5)
norm_matrix.append(norm_row)
heatmap_labels = [m["name"] for m in molecules_data]
heatmap = _make_heatmap(
norm_matrix, heatmap_labels, prop_names,
title="Normalized Property Heatmap",
color_scale="cyan",
width=700,
height=max(400, len(heatmap_labels) * 28 + 100),
)
html_parts.append("
")
for m in molecules_data:
lip = m["lipinski"]
def _badge(ok):
if ok:
return 'Pass'
return 'Fail'
overall_badge = _badge(m["lipinski_pass"])
html_parts.append(
f'
{m["name"]}
'
f'
{_badge(lip["mw_ok"])}
'
f'
{_badge(lip["logp_ok"])}
'
f'
{_badge(lip["hbd_ok"])}
'
f'
{_badge(lip["hba_ok"])}
'
f'
{overall_badge}
'
)
html_parts.append("
")
# QED bar chart
sorted_by_qed = sorted(molecules_data, key=lambda m: m["qed"], reverse=True)
qed_labels = [m["name"] for m in sorted_by_qed]
qed_vals = [m["qed"] for m in sorted_by_qed]
qed_chart = _make_bar_chart(
qed_labels, {"QED Score": qed_vals},
title="Drug-likeness (QED Score)",
horizontal=True,
width=700, height=max(300, len(qed_labels) * 30 + 80),
value_fmt=".3f",
colors=["#06d6a0"],
)
html_parts.append("
Drug-likeness (QED)
")
html_parts.append(f'
{qed_chart}
')
# Flush full report
await flyte.report.replace.aio(
_wrap_report("\n".join(html_parts)),
do_flush=True,
)
# Return properties as JSON (strip image data URIs to reduce size)
output = {
"total": total,
"lipinski_pass_count": lipinski_pass,
"lipinski_pass_rate": round(lipinski_rate, 2),
"avg_mw": round(avg_mw, 2),
"avg_logp": round(avg_logp, 2),
"molecules": [
{k: v for k, v in m.items() if k != "image_data_uri"}
for m in molecules_data
],
}
return json.dumps(output)
# ------------------------------------------------------------------
# Task 3: Screen candidates against target profile
# ------------------------------------------------------------------
@tool
@env.task(report=True)
async def screen_candidates(
properties_json: str,
target_profile: str = "",
) -> str:
"""Screen molecules against a target drug profile and rank candidates.
Scores each molecule on how well it matches the target profile, computes
pairwise Tanimoto similarity, and produces a ranked list.
Args:
properties_json: JSON from compute_properties.
target_profile: JSON string with desired property ranges
(e.g. {"mw": [150, 500], "logp": [-0.5, 5.0]}).
Returns:
JSON string with ranked_molecules, similarity_matrix, similarity_labels,
funnel, and target_profile. Pass the full return value verbatim to
generate_report along with molecule_dir and properties_json.
"""
from rdkit import Chem, DataStructs
from rdkit.Chem import AllChem
await flyte.report.replace.aio(
_wrap_report("
Screening Candidates...
"
"
Evaluating molecules against the target drug profile.
"),
do_flush=True,
)
props = json.loads(properties_json)
molecules = props["molecules"]
# Default target profile
if target_profile.strip():
profile = json.loads(target_profile)
else:
profile = {
"mw": [150, 500],
"logp": [-0.5, 5.0],
"hbd": [0, 5],
"hba": [0, 10],
"tpsa": [20, 140],
}
# --- Screening ---
funnel_total = len(molecules)
pass_mw = 0
pass_logp = 0
pass_lipinski = 0
final_candidates = 0
scored = []
for m in molecules:
score = 0
max_score = 0
criteria = {}
# Check each profile criterion
checks = [
("mw", m["mw"]),
("logp", m["logp"]),
("hbd", m["hbd"]),
("hba", m["hba"]),
("tpsa", m["tpsa"]),
]
for key, val in checks:
if key in profile:
lo, hi = profile[key]
max_score += 1
in_range = lo <= val <= hi
criteria[key] = in_range
if in_range:
score += 1
# Bonus: closer to midpoint = higher score
mid = (lo + hi) / 2
rng = (hi - lo) / 2
dist = abs(val - mid) / rng if rng else 0
score += max(0, 0.5 * (1 - dist))
# QED bonus
score += m["qed"] * 2
max_score += 2
# Lipinski bonus
if m["lipinski_pass"]:
score += 1
max_score += 1
normalized_score = score / max_score if max_score else 0
# Funnel tracking — cascading filter (each stage requires passing the previous)
mw_ok = criteria.get("mw", True)
logp_ok = criteria.get("logp", True)
if mw_ok:
pass_mw += 1
if logp_ok:
pass_logp += 1
if m["lipinski_pass"]:
pass_lipinski += 1
if all(criteria.values()):
final_candidates += 1
scored.append({
**m,
"screening_score": round(normalized_score, 4),
"criteria_met": criteria,
"all_criteria_met": all(criteria.values()),
})
# Sort by score descending
scored.sort(key=lambda m: m["screening_score"], reverse=True)
# --- Tanimoto similarity matrix ---
fps = []
valid_names = []
for m in scored:
mol = Chem.MolFromSmiles(m["smiles"])
if mol:
fp = AllChem.GetMorganFingerprintAsBitVect(mol, 2, nBits=2048)
fps.append(fp)
valid_names.append(m["name"])
similarity_matrix = []
for i in range(len(fps)):
row = []
for j in range(len(fps)):
sim = DataStructs.TanimotoSimilarity(fps[i], fps[j])
row.append(round(sim, 3))
similarity_matrix.append(row)
# ---- Build report ----
html_parts = []
html_parts.append("
Candidate Screening Results
")
# Stat grid
html_parts.append('
')
for val, label in [
(str(funnel_total), "Total Screened"),
(str(pass_lipinski), "Lipinski Passes"),
(str(final_candidates), "All Criteria Met"),
(f"{scored[0]['screening_score']:.3f}" if scored else "N/A", "Top Score"),
]:
html_parts.append(
f'
"
)
for rank, m in enumerate(scored, 1):
lip_badge = ('Pass'
if m["lipinski_pass"]
else 'Fail')
crit_badge = ('Pass'
if m["all_criteria_met"]
else 'Fail')
# Highlight top 3
row_style = ' style="background:#ecfeff;font-weight:600;"' if rank <= 3 else ""
html_parts.append(
f"
{rank}
{m['name']}
"
f"
{m['screening_score']:.3f}
"
f"
{m['mw']:.1f}
{m['logp']:.2f}
"
f"
{m['qed']:.3f}
{lip_badge}
{crit_badge}
"
)
html_parts.append("
")
# Top 5 candidate cards with structures
html_parts.append("
Top 5 Candidates
")
html_parts.append('
')
for m in scored[:5]:
mol = Chem.MolFromSmiles(m["smiles"])
img_uri = _mol_to_data_uri(mol, size=(250, 250)) if mol else ""
badge_class = "badge-success" if m["all_criteria_met"] else "badge-info"
badge_text = "All Criteria Met" if m["all_criteria_met"] else "Partial Match"
html_parts.append(
f'
')
await flyte.report.replace.aio(
_wrap_report("\n".join(html_parts)),
do_flush=True,
)
output = {
"ranked_molecules": scored,
"similarity_matrix": similarity_matrix,
"similarity_labels": valid_names,
"funnel": funnel_stages,
"target_profile": profile,
}
return json.dumps(output)
def _parse_screening_json(screening_json: str) -> dict:
"""Parse screening JSON from screen_candidates, with safe defaults.
The agent must pass the exact tool return value. Partial or hand-built JSON
is tolerated for optional similarity fields only.
"""
screening = json.loads(screening_json)
if "ranked_molecules" not in screening:
raise ValueError(
"screening_json must be the exact JSON string returned by "
"screen_candidates (missing 'ranked_molecules'). Do not construct, "
"truncate, or summarize tool output."
)
screening.setdefault("similarity_matrix", [])
screening.setdefault("similarity_labels", [])
return screening
# ------------------------------------------------------------------
# Task 4: Generate final comprehensive report
# ------------------------------------------------------------------
@tool
@env.task(report=True)
async def generate_report(
molecule_dir: flyte.io.Dir,
properties_json: str,
screening_json: str,
) -> str:
"""Generate a comprehensive drug screening report.
Produces an executive summary, top candidate spotlight cards, property
distributions, chemical diversity analysis, and final recommendation.
Args:
molecule_dir: Directory from load_molecules.
properties_json: JSON from compute_properties.
screening_json: Exact verbatim JSON string returned by screen_candidates
(must include ranked_molecules, similarity_matrix, similarity_labels).
Do not construct or summarize this payload yourself.
Returns:
JSON summary with total_screened, lipinski_passes, all_criteria_met,
top_candidate, top_score, and top_3 ranked molecules.
"""
from rdkit import Chem
await flyte.report.replace.aio(
_wrap_report("
Generating Final Report...
"),
do_flush=True,
)
props = json.loads(properties_json)
screening = _parse_screening_json(screening_json)
ranked = screening["ranked_molecules"]
sim_matrix = screening["similarity_matrix"]
sim_labels = screening["similarity_labels"]
total = props["total"]
lipinski_pass = props["lipinski_pass_count"]
all_criteria = sum(1 for m in ranked if m["all_criteria_met"])
top = ranked[0] if ranked else None
html_parts = []
# --- Executive Summary ---
html_parts.append("
Drug Molecule Screening Report
")
top_name = top["name"] if top else "N/A"
top_score = f'{top["screening_score"]:.3f}' if top else "N/A"
html_parts.append(
f'
'
f'
Executive Summary
'
f'
'
f'{total} molecules were screened against the target drug profile. '
f'{lipinski_pass} passed Lipinski\'s Rule of Five, and '
f'{all_criteria} met all screening criteria. '
f'The top candidate is {top_name} '
f'with a screening score of {top_score}.
'
f'
'
)
# Stat grid
html_parts.append('
')
for val, label in [
(str(total), "Molecules Screened"),
(str(lipinski_pass), "Lipinski Passes"),
(str(all_criteria), "All Criteria Met"),
(top_score, "Top Score"),
(f'{props["avg_mw"]:.0f} Da', "Avg. Molecular Weight"),
(f'{props["avg_logp"]:.2f}', "Avg. LogP"),
]:
html_parts.append(
f'
{val}
'
f'
{label}
'
)
html_parts.append("
")
# --- Top 3 Candidate Spotlights ---
html_parts.append("
Top Candidate Spotlights
")
for rank, m in enumerate(ranked[:3], 1):
mol = Chem.MolFromSmiles(m["smiles"])
img_uri = _mol_to_data_uri(mol, size=(300, 300)) if mol else ""
medal = ["gold", "silver", "#cd7f32"][rank - 1]
medal_emoji = ["1st", "2nd", "3rd"][rank - 1]
lip_badges = ""
for rule, key in [("MW", "mw_ok"), ("LogP", "logp_ok"),
("HBD", "hbd_ok"), ("HBA", "hba_ok")]:
ok = m["lipinski"].get(key, False)
cls = "badge-success" if ok else "badge-danger"
lip_badges += f'{rule} '
html_parts.append(
f'
'
f'
'
f'
{medal_emoji}
'
f''
f'
{m["name"]}
'
f'
'
f'
'
f'
'
f'
SMILES
{m["smiles"]}
'
f'
Screening Score
{m["screening_score"]:.3f}
'
f'
Molecular Weight
{m["mw"]:.1f} Da
'
f'
LogP
{m["logp"]:.2f}
'
f'
H-Bond Donors
{m["hbd"]}
'
f'
H-Bond Acceptors
{m["hba"]}
'
f'
TPSA
{m["tpsa"]:.1f} A²
'
f'
Rotatable Bonds
{m["rotatable_bonds"]}
'
f'
QED
{m["qed"]:.4f}
'
f'
Lipinski Compliance
{lip_badges}
'
f'
'
f'
'
f'
'
)
# --- Property Distribution (box-plot style as bars with min/max/median) ---
html_parts.append("
Property Distributions
")
prop_keys = [("mw", "Molecular Weight (Da)"), ("logp", "LogP"),
("tpsa", "TPSA"), ("qed", "QED Score")]
for key, label in prop_keys:
vals = sorted([m[key] for m in ranked])
n = len(vals)
if n == 0:
continue
v_min = vals[0]
v_max = vals[-1]
median = vals[n // 2] if n % 2 == 1 else (vals[n // 2 - 1] + vals[n // 2]) / 2
q1 = vals[n // 4] if n >= 4 else v_min
q3 = vals[3 * n // 4] if n >= 4 else v_max
# Simple horizontal box-plot as SVG
box_w = 500
box_h = 50
margin_l = 10
v_range = v_max - v_min or 1
def sx(v):
return margin_l + ((v - v_min) / v_range) * (box_w - 2 * margin_l)
box_svg = (
f''
)
html_parts.append(
f'
{label}'
f'
{box_svg}
'
)
# --- Chemical Diversity ---
html_parts.append("
Chemical Diversity Analysis
")
if sim_matrix and len(sim_matrix) > 1:
# Compute average pairwise similarity (off-diagonal)
n_mols = len(sim_matrix)
off_diag = []
for i in range(n_mols):
for j in range(i + 1, n_mols):
off_diag.append(sim_matrix[i][j])
avg_sim = sum(off_diag) / len(off_diag) if off_diag else 0
max_sim = max(off_diag) if off_diag else 0
min_sim = min(off_diag) if off_diag else 0
# Find most similar pair
best_i, best_j = 0, 1
best_val = 0
for i in range(n_mols):
for j in range(i + 1, n_mols):
if sim_matrix[i][j] > best_val:
best_val = sim_matrix[i][j]
best_i, best_j = i, j
html_parts.append('
')
html_parts.append(
f'
{avg_sim:.3f}
'
f'
Avg. Pairwise Similarity
'
)
html_parts.append(
f'
{min_sim:.3f}
'
f'
Min Similarity
'
)
html_parts.append(
f'
{max_sim:.3f}
'
f'
Max Similarity
'
)
html_parts.append("
")
diversity_text = "highly diverse" if avg_sim < 0.3 else "moderately diverse" if avg_sim < 0.5 else "relatively similar"
html_parts.append(
f'
'
f'The library is {diversity_text} (avg. Tanimoto = {avg_sim:.3f}). '
f'The most similar pair is {sim_labels[best_i]} and '
f'{sim_labels[best_j]} (similarity = {best_val:.3f}).
'
)
# --- Recommendation ---
html_parts.append("
Recommendation
")
if top:
html_parts.append(
f'
'
f'
Top Candidate: {top["name"]}
'
f'
Based on the virtual screening analysis, {top["name"]} '
f'achieved the highest composite screening score of {top["screening_score"]:.3f}. '
)
reasons = []
if top["lipinski_pass"]:
reasons.append("full Lipinski Rule of Five compliance")
if top["qed"] > 0.5:
reasons.append(f"high drug-likeness (QED = {top['qed']:.3f})")
if top.get("all_criteria_met"):
reasons.append("all target profile criteria met")
if top["mw"] <= 500:
reasons.append(f"favorable molecular weight ({top['mw']:.1f} Da)")
if reasons:
html_parts.append(
f'This candidate stands out due to: {", ".join(reasons)}.
'
)
else:
html_parts.append("")
# Runner-up mentions
if len(ranked) >= 2:
html_parts.append(
f'
Runner-up candidates: '
)
runners = []
for m in ranked[1:4]:
runners.append(f'{m["name"]} (score: {m["screening_score"]:.3f})')
html_parts.append(", ".join(runners) + ".
")
html_parts.append("
")
# Final note
html_parts.append(
'
'
"This is a virtual screening analysis. All candidates should undergo "
"further computational validation (molecular dynamics, docking) and "
"experimental testing before advancing to clinical trials.
"
)
await flyte.report.replace.aio(
_wrap_report("\n".join(html_parts)),
do_flush=True,
)
# JSON summary
summary = {
"total_screened": total,
"lipinski_passes": lipinski_pass,
"all_criteria_met": all_criteria,
"top_candidate": top["name"] if top else None,
"top_score": top["screening_score"] if top else None,
"top_3": [
{"name": m["name"], "score": m["screening_score"]}
for m in ranked[:3]
],
}
return json.dumps(summary)
# ------------------------------------------------------------------
# Agent
# ------------------------------------------------------------------
# {{docs-fragment agent}}
SCREENING_AGENT_INSTRUCTIONS = """\
You are a medicinal chemistry screening strategist. You orchestrate a virtual \
screening pipeline using durable Flyte tools. You NEVER invent molecular \
properties — only RDKit tools compute them.
Workflow:
1. If target_profile is not provided in the user message, derive a JSON \
target_profile from the therapeutic brief. Valid keys: mw, logp, hbd, hba, tpsa \
(each [min, max]). Ground choices in oral bioavailability / kinase / CNS rules \
as appropriate to the brief.
2. First pass (always): load_molecules → compute_properties → \
screen_candidates → generate_report. Pass tool outputs between steps exactly \
(molecule_dir from load_molecules into compute_properties and generate_report; \
properties_json from compute_properties into screen_candidates and \
generate_report; screening_json must be the complete, unmodified string \
returned by screen_candidates — never rebuild or summarize JSON yourself).
3. Read the JSON summary returned by generate_report. Reflect:
- If all_criteria_met == 0: relax exactly ONE profile bound by ~10–20% \
and re-run screen_candidates then generate_report only, reusing the same \
molecule_dir and properties_json from the first pass.
- If all molecules pass but diversity is a stated goal: note high similarity \
in your summary; do not re-run unless brief asks for stricter filters.
- Maximum ONE rescreen iteration.
4. Finish with plain text: top candidate, rationale tied to computed metrics \
from the tool JSON, funnel interpretation, and suggested next steps (docking, \
ADMET lab tests).
If the user supplies an explicit target_profile JSON, use it as-is.
Do NOT ask the user for SMILES or molecule lists when molecules_json is empty — \
the default library is loaded automatically.
"""
screening_agent = Agent(
name="drug-screening-agent",
instructions=SCREENING_AGENT_INSTRUCTIONS,
model=MODEL,
tools=[
load_molecules,
compute_properties,
screen_candidates,
generate_report,
],
max_turns=12,
)
# {{/docs-fragment agent}}
# ------------------------------------------------------------------
# Pipeline
# ------------------------------------------------------------------
# {{docs-fragment pipeline}}
@env.task(report=True)
async def pipeline(
brief: str = "Screen the default drug library for orally bioavailable small molecules.",
molecules_json: str = "",
target_profile: str = "",
) -> str:
"""Agentic virtual drug molecule screening pipeline.
A medicinal-chemistry agent interprets the screening brief, derives or
applies a target profile, orchestrates the RDKit screening stages, and
optionally re-screens when funnel results are too narrow.
Args:
brief: Natural-language therapeutic goal (e.g. oral kinase inhibitors,
CNS-penetrant small molecules).
molecules_json: JSON mapping molecule names to SMILES strings.
Defaults to a curated library of ~15 well-known drugs.
target_profile: Optional JSON with desired property ranges that
overrides agent-derived criteria
(e.g. {"mw": [150, 500], "logp": [-0.5, 5]}).
Returns:
Agent summary with screening rationale and key results.
"""
prompt_parts = [
f"Screening brief: {brief}",
'Use molecules_json="" for the built-in default library unless provided below.',
"Compose the four stage tools in order: load_molecules → compute_properties "
"→ screen_candidates → generate_report. Pass each tool's full return value "
"verbatim to the next step (especially screening_json). Re-run "
"screen_candidates and generate_report at most once if the funnel is too narrow.",
]
if molecules_json.strip():
prompt_parts.append(f"molecules_json: {molecules_json}")
if target_profile.strip():
prompt_parts.append(f"Use this target_profile exactly: {target_profile}")
result = await screening_agent.run.aio("\n".join(prompt_parts))
return result.summary or result.error or ""
# {{/docs-fragment pipeline}}
# ------------------------------------------------------------------
# Rescreen demo — tight profile + explicit rescreen instructions
# ------------------------------------------------------------------
# Initial profile is deliberately strict (narrow MW + low LogP cap) so
# all_criteria_met is typically 0 on the default library; the brief then
# forces a single rescreen with a widened LogP window.
RESCREEN_DEMO_TARGET_PROFILE = (
'{"mw": [150, 200], "logp": [-0.5, 1.0], "hbd": [0, 1], '
'"hba": [0, 3], "tpsa": [20, 45]}'
)
RESCREEN_DEMO_TARGET_PROFILE_RESCREEN = (
'{"mw": [150, 200], "logp": [-0.5, 3.5], "hbd": [0, 1], '
'"hba": [0, 3], "tpsa": [20, 45]}'
)
RESCREEN_DEMO_BRIEF = f"""\
Two-round agentic screening demo on the default library.
**Round 1 (strict profile):** load_molecules → compute_properties → \
screen_candidates → generate_report using the initial target_profile exactly.
**Round 2 (required — do not skip):** call screen_candidates then generate_report \
again, reusing the same molecule_dir and properties_json from round 1, with this \
relaxed target_profile (wider LogP window only): \
{RESCREEN_DEMO_TARGET_PROFILE_RESCREEN}
Pass every tool return value verbatim to the next step. After both rounds, \
summarize how the funnel and top candidates changed between round 1 and round 2."""
# {{docs-fragment rescreen_demo}}
@env.task(report=True)
async def rescreen_demo() -> str:
"""Example run with a two-round execution graph (rescreen).
Round 1 uses a strict CNS-like profile; round 2 always re-runs
screen_candidates and generate_report with a widened LogP window,
reusing cached molecule_dir and properties_json.
"""
return await pipeline(
brief=RESCREEN_DEMO_BRIEF,
target_profile=RESCREEN_DEMO_TARGET_PROFILE,
)
# {{/docs-fragment rescreen_demo}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(pipeline)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/drug_molecule_screening/drug_molecule_screening.py*
## Run the agentic pipeline
The `pipeline` task delegates to the screening agent:
```
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flyte>=2.5.4",
# "litellm",
# "rdkit",
# "numpy",
# "scikit-learn",
# "pillow",
# ]
# main = "pipeline"
# params = ""
# ///
"""Virtual drug molecule screening — compute properties, apply Lipinski filters, rank candidates."""
import base64
import io
import json
import logging
import math
import os
import tempfile
import flyte
import flyte.io
import flyte.report
from flyte.ai.agents import Agent, tool
MODEL = os.getenv("DRUG_SCREENING_MODEL", "claude-haiku-4-5")
# {{docs-fragment env}}
main_img = flyte.Image.from_uv_script(__file__, name="drug-molecule-screening", pre=True).with_apt_packages(
"libxrender1", "libxext6", "libexpat1",
)
env = flyte.TaskEnvironment(
name="drug-molecule-screening",
image=main_img,
resources=flyte.Resources(cpu=2, memory="6Gi"),
secrets=[
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
)
# {{/docs-fragment env}}
logging.basicConfig(level=logging.WARNING, format="%(message)s", force=True)
log = logging.getLogger(__name__)
log.setLevel(logging.INFO)
# ------------------------------------------------------------------
# Default molecule library — real SMILES for well-known drugs
# ------------------------------------------------------------------
DEFAULT_MOLECULES = {
"Aspirin": "CC(=O)OC1=CC=CC=C1C(=O)O",
"Ibuprofen": "CC(C)CC1=CC=C(C=C1)C(C)C(=O)O",
"Caffeine": "CN1C=NC2=C1C(=O)N(C(=O)N2C)C",
"Penicillin G": "CC1(C(N2C(S1)C(C2=O)NC(=O)CC3=CC=CC=C3)C(=O)O)C",
"Metformin": "CN(C)C(=N)NC(=N)N",
"Paracetamol": "CC(=O)NC1=CC=C(C=C1)O",
"Diazepam": "ClC1=CC2=C(C=C1)N(C(=O)CN=C2C3=CC=CC=C3)C",
"Omeprazole": "CC1=CN=C(C(=C1OC)C)CS(=O)C2=NC3=CC=CC=C3N2",
"Atorvastatin": "CC(C)C1=C(C(=C(N1CCC(CC(CC(=O)O)O)O)C2=CC=C(C=C2)F)C3=CC=CC=C3)C(=O)NC4=CC=CC=C4",
"Methotrexate": "CN(CC1=CN=C2N=C(N=C(N)C2=N1)N)C3=CC=C(C=C3)C(=O)NC(CCC(=O)O)C(=O)O",
"Doxorubicin": "CC1C(C(CC(O1)OC2CC(CC3=C2C(=C4C(=C3O)C(=O)C5=C(C4=O)C(=CC=C5)OC)O)(C(=O)CO)O)N)O",
"Tamoxifen": "CCC(=C(C1=CC=CC=C1)C2=CC=C(C=C2)OCCN(C)C)C3=CC=CC=C3",
"Lopinavir": "CC1=C(C(=CC=C1)C)OCC(=O)NC(CC2=CC=CC=C2)C(CC(CC3=CC=CC=C3)NC(=O)C(C(C)C)N4CCCNC4=O)O",
"Remdesivir": "CCC(CC)COC(=O)C(C)NP(=O)(OCC1C(C(C(O1)C2=CC=C3N2N=CN=C3N)O)O)OC4=CC=CC=C4",
"Erlotinib": "COCCOC1=CC2=C(C=C1OCCOC)C(=NC=N2)NC3=CC=CC(=C3)C#C",
}
# ------------------------------------------------------------------
# Report styling — pharma blue/cyan theme
# ------------------------------------------------------------------
REPORT_CSS = """
"""
def _wrap_report(html: str) -> str:
"""Wrap HTML content with report styling."""
return f'{REPORT_CSS}
{html}
'
# ------------------------------------------------------------------
# SVG chart helpers
# ------------------------------------------------------------------
def _mol_to_data_uri(mol, size: tuple[int, int] = (300, 300)) -> str:
"""Convert an RDKit molecule to a PNG base64 data URI."""
from rdkit.Chem import Draw
img = Draw.MolToImage(mol, size=size)
buf = io.BytesIO()
img.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode()
return f"data:image/png;base64,{b64}"
def _make_bar_chart(
labels: list[str],
series: dict[str, list[float]],
title: str = "",
colors: list[str] | None = None,
width: int = 700,
height: int = 340,
y_max_cap: float | None = None,
horizontal: bool = False,
value_fmt: str = ".1f",
) -> str:
"""Generate an SVG grouped bar chart.
Args:
labels: Category labels.
series: Dict mapping series name to list of values.
title: Chart title.
colors: Colors for each series.
width/height: SVG dimensions.
y_max_cap: Cap the y-axis at this value.
horizontal: If True, draw horizontal bars.
value_fmt: Format string for value labels.
Returns:
SVG string.
"""
if not labels:
return ""
default_colors = ["#0891b2", "#0e4f6e", "#06d6a0", "#a5f3fc", "#155e75"]
colors = colors or default_colors
if horizontal:
return _make_horizontal_bar_chart(labels, series, title, colors, width, height, value_fmt)
ml, mr, mt, mb = 60, 20, 40, 60
cw = width - ml - mr
ch = height - mt - mb
all_vals = [v for vals in series.values() for v in vals]
y_max = max(all_vals) if all_vals else 1
y_max_plot = y_max * 1.15 or 1
if y_max_cap is not None:
y_max_plot = min(y_max_plot, y_max_cap) or y_max_cap
n_groups = len(labels)
n_series = len(series)
group_width = cw / n_groups
bar_width = group_width * 0.7 / max(n_series, 1)
gap = group_width * 0.15
def sy(v):
return mt + ch - (v / y_max_plot) * ch
svg = [
f'")
return "\n".join(svg)
def _make_horizontal_bar_chart(
labels: list[str],
series: dict[str, list[float]],
title: str = "",
colors: list[str] | None = None,
width: int = 700,
height: int = 400,
value_fmt: str = ".1f",
) -> str:
"""Generate an SVG horizontal bar chart (sorted)."""
default_colors = ["#0891b2", "#0e4f6e", "#06d6a0"]
colors = colors or default_colors
n = len(labels)
row_height = max(22, min(35, (height - 80) // max(n, 1)))
actual_height = max(height, 80 + n * row_height)
ml, mr, mt, mb = 120, 60, 40, 20
cw = width - ml - mr
ch = actual_height - mt - mb
# Use first series
first_key = list(series.keys())[0]
vals = series[first_key]
x_max = max(vals) * 1.15 if vals else 1
svg = [
f'")
return "\n".join(svg)
def _make_heatmap(
matrix: list[list[float]],
row_labels: list[str],
col_labels: list[str],
title: str = "",
color_scale: str = "cyan",
width: int = 700,
height: int = 500,
value_fmt: str = ".2f",
) -> str:
"""Generate an SVG heatmap.
Args:
matrix: 2D list of values (rows x cols).
row_labels: Labels for rows.
col_labels: Labels for columns.
title: Chart title.
color_scale: Color scheme ("cyan", "red", "green").
width/height: SVG dimensions.
value_fmt: Format string for cell values.
Returns:
SVG string.
"""
if not matrix or not matrix[0]:
return ""
n_rows = len(matrix)
n_cols = len(matrix[0])
ml, mr, mt, mb = 110, 20, 70, 20
cw = width - ml - mr
ch = height - mt - mb
cell_w = cw / n_cols
cell_h = ch / n_rows
# Flatten to find range
flat = [v for row in matrix for v in row]
v_min = min(flat)
v_max = max(flat)
v_range = v_max - v_min or 1
def color_for(v):
t = (v - v_min) / v_range
if color_scale == "cyan":
# White to deep teal
r = int(255 - t * (255 - 14))
g = int(255 - t * (255 - 79))
b = int(255 - t * (255 - 110))
elif color_scale == "red":
r = int(255 - t * 50)
g = int(255 - t * 200)
b = int(255 - t * 200)
else: # green
r = int(255 - t * 200)
g = int(255 - t * 50)
b = int(255 - t * 200)
return f"rgb({r},{g},{b})"
svg = [
f'")
return "\n".join(svg)
def _make_scatter_plot(
points: list[dict],
x_label: str = "MW",
y_label: str = "LogP",
title: str = "",
reference_lines: list[dict] | None = None,
width: int = 700,
height: int = 400,
) -> str:
"""Generate an SVG scatter plot.
Args:
points: List of dicts with "x", "y", "label" keys.
x_label/y_label: Axis labels.
title: Chart title.
reference_lines: List of dicts with "axis" ("x"/"y"), "value", "label".
width/height: SVG dimensions.
Returns:
SVG string.
"""
if not points:
return ""
ml, mr, mt, mb = 60, 30, 40, 50
cw = width - ml - mr
ch = height - mt - mb
x_vals = [p["x"] for p in points]
y_vals = [p["y"] for p in points]
x_min, x_max = min(x_vals) * 0.9, max(x_vals) * 1.1
y_min, y_max = min(y_vals) - 1, max(y_vals) + 1
# Extend ranges to include reference lines
if reference_lines:
for rl in reference_lines:
if rl["axis"] == "x":
x_max = max(x_max, rl["value"] * 1.1)
else:
y_max = max(y_max, rl["value"] * 1.1)
x_range = x_max - x_min or 1
y_range = y_max - y_min or 1
def sx(v):
return ml + (v - x_min) / x_range * cw
def sy(v):
return mt + ch - (v - y_min) / y_range * ch
svg = [
f'")
return "\n".join(svg)
def _make_funnel(
stages: list[dict],
title: str = "",
width: int = 600,
height: int = 400,
) -> str:
"""Generate an SVG funnel visualization.
Args:
stages: List of dicts with "label", "count", "total" keys.
title: Chart title.
width/height: SVG dimensions.
Returns:
SVG string.
"""
if not stages:
return ""
n = len(stages)
mt = 50
mb = 20
available_h = height - mt - mb
stage_h = available_h / n
cx = width / 2
# Color gradient from light cyan to deep teal
colors = []
for i in range(n):
t = i / max(n - 1, 1)
r = int(207 - t * (207 - 14))
g = int(250 - t * (250 - 79))
b = int(254 - t * (254 - 110))
colors.append(f"rgb({r},{g},{b})")
svg = [
f'")
return "\n".join(svg)
# ------------------------------------------------------------------
# Task 1: Load and validate molecules
# ------------------------------------------------------------------
@tool
@env.task(cache="auto")
async def load_molecules(
molecules_json: str = "",
) -> flyte.io.Dir:
"""Parse SMILES strings, validate with RDKit, generate 2D depictions.
Args:
molecules_json: JSON string mapping molecule names to SMILES.
Defaults to a curated library of ~15 well-known drugs.
Returns:
flyte.io.Dir containing molecule data (JSON + PNG depictions).
Pass this directory to compute_properties and generate_report.
"""
from rdkit import Chem
from rdkit.Chem import Draw
if molecules_json.strip():
molecules = json.loads(molecules_json)
else:
molecules = DEFAULT_MOLECULES
out_dir = tempfile.mkdtemp(prefix="mol_library_")
results = []
valid_count = 0
invalid_count = 0
log.info(f"Parsing {len(molecules)} molecules...")
for name, smiles in molecules.items():
mol = Chem.MolFromSmiles(smiles)
if mol is None:
log.warning(f" [INVALID] {name}: {smiles}")
invalid_count += 1
continue
valid_count += 1
# Generate 2D depiction as PNG
img = Draw.MolToImage(mol, size=(300, 300))
img_path = os.path.join(out_dir, f"{name.replace(' ', '_')}.png")
img.save(img_path)
results.append({
"name": name,
"smiles": smiles,
"valid": True,
"image_file": os.path.basename(img_path),
})
# Save molecule manifest
manifest = {
"total": len(molecules),
"valid": valid_count,
"invalid": invalid_count,
"molecules": results,
}
manifest_path = os.path.join(out_dir, "manifest.json")
with open(manifest_path, "w") as f:
json.dump(manifest, f, indent=2)
log.info(f"Loaded {valid_count} valid molecules ({invalid_count} invalid)")
return await flyte.io.Dir.from_local(out_dir)
# ------------------------------------------------------------------
# Task 2: Compute physicochemical properties
# ------------------------------------------------------------------
@tool
@env.task(report=True)
async def compute_properties(
molecule_dir: flyte.io.Dir,
) -> str:
"""Compute drug-likeness properties for all molecules.
Computes MW, LogP, HBD, HBA, TPSA, rotatable bonds, formal charge,
ring count, QED, and Lipinski Rule of Five compliance.
Args:
molecule_dir: Directory from load_molecules.
Returns:
JSON string with all computed properties. Pass to screen_candidates
and generate_report.
"""
from rdkit import Chem
from rdkit.Chem import Descriptors, Lipinski
from rdkit.Chem.QED import qed
# --- Loading report ---
await flyte.report.replace.aio(
_wrap_report("
Computing Molecular Properties...
"
"
Analyzing physicochemical descriptors for all molecules.
"),
do_flush=True,
)
mol_dir = await molecule_dir.download()
with open(os.path.join(mol_dir, "manifest.json")) as f:
manifest = json.load(f)
molecules_data = []
lipinski_pass = 0
for mol_info in manifest["molecules"]:
mol = Chem.MolFromSmiles(mol_info["smiles"])
if mol is None:
continue
mw = Descriptors.MolWt(mol)
logp = Descriptors.MolLogP(mol)
hbd = Lipinski.NumHDonors(mol)
hba = Lipinski.NumHAcceptors(mol)
tpsa = Descriptors.TPSA(mol)
rotatable = Lipinski.NumRotatableBonds(mol)
formal_charge = Chem.GetFormalCharge(mol)
num_rings = Lipinski.RingCount(mol)
qed_score = qed(mol)
# Lipinski Rule of Five
lipinski = {
"mw_ok": mw <= 500,
"logp_ok": logp <= 5,
"hbd_ok": hbd <= 5,
"hba_ok": hba <= 10,
}
lipinski_all = all(lipinski.values())
if lipinski_all:
lipinski_pass += 1
# Read image for data URI
img_path = os.path.join(mol_dir, mol_info["image_file"])
data_uri = ""
if os.path.exists(img_path):
with open(img_path, "rb") as img_f:
b64 = base64.b64encode(img_f.read()).decode()
data_uri = f"data:image/png;base64,{b64}"
molecules_data.append({
"name": mol_info["name"],
"smiles": mol_info["smiles"],
"mw": round(mw, 2),
"logp": round(logp, 2),
"hbd": hbd,
"hba": hba,
"tpsa": round(tpsa, 2),
"rotatable_bonds": rotatable,
"formal_charge": formal_charge,
"num_rings": num_rings,
"qed": round(qed_score, 4),
"lipinski": lipinski,
"lipinski_pass": lipinski_all,
"image_data_uri": data_uri,
})
total = len(molecules_data)
avg_mw = sum(m["mw"] for m in molecules_data) / total if total else 0
avg_logp = sum(m["logp"] for m in molecules_data) / total if total else 0
lipinski_rate = lipinski_pass / total * 100 if total else 0
# ---- Build report ----
html_parts = []
# Header
html_parts.append("
Molecular Properties Analysis
")
# Stat grid
html_parts.append('
')
for val, label in [
(str(total), "Total Molecules"),
(f"{lipinski_rate:.0f}%", "Lipinski Pass Rate"),
(f"{avg_mw:.1f}", "Avg. MW (Da)"),
(f"{avg_logp:.2f}", "Avg. LogP"),
]:
html_parts.append(
f'
{val}
'
f'
{label}
'
)
html_parts.append("
")
# Molecule gallery
html_parts.append("
Molecule Library
")
html_parts.append('
')
for m in molecules_data:
if m["image_data_uri"]:
badge_class = "badge-success" if m["lipinski_pass"] else "badge-danger"
badge_text = "Lipinski Pass" if m["lipinski_pass"] else "Lipinski Fail"
html_parts.append(
f'
'
f''
f'
{m["name"]}
'
f'
MW: {m["mw"]:.1f} | LogP: {m["logp"]:.2f}
'
f'
{badge_text}
'
f'
'
)
html_parts.append("
")
# MW bar chart (horizontal, sorted)
sorted_by_mw = sorted(molecules_data, key=lambda m: m["mw"], reverse=True)
mw_labels = [m["name"] for m in sorted_by_mw]
mw_vals = [m["mw"] for m in sorted_by_mw]
mw_chart = _make_bar_chart(
mw_labels, {"MW (Da)": mw_vals},
title="Molecular Weight Distribution",
horizontal=True,
width=700, height=max(300, len(mw_labels) * 30 + 80),
value_fmt=".1f",
)
html_parts.append("
')
# Property heatmap (molecules x properties)
prop_names = ["MW", "LogP", "HBD", "HBA", "TPSA", "Rot. Bonds"]
# Normalize each property to 0-1 for heatmap
raw_matrix = []
for m in molecules_data:
raw_matrix.append([m["mw"], m["logp"], m["hbd"], m["hba"], m["tpsa"], m["rotatable_bonds"]])
# Normalize per column
n_props = len(prop_names)
col_min = [min(row[c] for row in raw_matrix) for c in range(n_props)]
col_max = [max(row[c] for row in raw_matrix) for c in range(n_props)]
norm_matrix = []
for row in raw_matrix:
norm_row = []
for c in range(n_props):
rng = col_max[c] - col_min[c]
norm_row.append((row[c] - col_min[c]) / rng if rng else 0.5)
norm_matrix.append(norm_row)
heatmap_labels = [m["name"] for m in molecules_data]
heatmap = _make_heatmap(
norm_matrix, heatmap_labels, prop_names,
title="Normalized Property Heatmap",
color_scale="cyan",
width=700,
height=max(400, len(heatmap_labels) * 28 + 100),
)
html_parts.append("
")
for m in molecules_data:
lip = m["lipinski"]
def _badge(ok):
if ok:
return 'Pass'
return 'Fail'
overall_badge = _badge(m["lipinski_pass"])
html_parts.append(
f'
{m["name"]}
'
f'
{_badge(lip["mw_ok"])}
'
f'
{_badge(lip["logp_ok"])}
'
f'
{_badge(lip["hbd_ok"])}
'
f'
{_badge(lip["hba_ok"])}
'
f'
{overall_badge}
'
)
html_parts.append("
")
# QED bar chart
sorted_by_qed = sorted(molecules_data, key=lambda m: m["qed"], reverse=True)
qed_labels = [m["name"] for m in sorted_by_qed]
qed_vals = [m["qed"] for m in sorted_by_qed]
qed_chart = _make_bar_chart(
qed_labels, {"QED Score": qed_vals},
title="Drug-likeness (QED Score)",
horizontal=True,
width=700, height=max(300, len(qed_labels) * 30 + 80),
value_fmt=".3f",
colors=["#06d6a0"],
)
html_parts.append("
Drug-likeness (QED)
")
html_parts.append(f'
{qed_chart}
')
# Flush full report
await flyte.report.replace.aio(
_wrap_report("\n".join(html_parts)),
do_flush=True,
)
# Return properties as JSON (strip image data URIs to reduce size)
output = {
"total": total,
"lipinski_pass_count": lipinski_pass,
"lipinski_pass_rate": round(lipinski_rate, 2),
"avg_mw": round(avg_mw, 2),
"avg_logp": round(avg_logp, 2),
"molecules": [
{k: v for k, v in m.items() if k != "image_data_uri"}
for m in molecules_data
],
}
return json.dumps(output)
# ------------------------------------------------------------------
# Task 3: Screen candidates against target profile
# ------------------------------------------------------------------
@tool
@env.task(report=True)
async def screen_candidates(
properties_json: str,
target_profile: str = "",
) -> str:
"""Screen molecules against a target drug profile and rank candidates.
Scores each molecule on how well it matches the target profile, computes
pairwise Tanimoto similarity, and produces a ranked list.
Args:
properties_json: JSON from compute_properties.
target_profile: JSON string with desired property ranges
(e.g. {"mw": [150, 500], "logp": [-0.5, 5.0]}).
Returns:
JSON string with ranked_molecules, similarity_matrix, similarity_labels,
funnel, and target_profile. Pass the full return value verbatim to
generate_report along with molecule_dir and properties_json.
"""
from rdkit import Chem, DataStructs
from rdkit.Chem import AllChem
await flyte.report.replace.aio(
_wrap_report("
Screening Candidates...
"
"
Evaluating molecules against the target drug profile.
"),
do_flush=True,
)
props = json.loads(properties_json)
molecules = props["molecules"]
# Default target profile
if target_profile.strip():
profile = json.loads(target_profile)
else:
profile = {
"mw": [150, 500],
"logp": [-0.5, 5.0],
"hbd": [0, 5],
"hba": [0, 10],
"tpsa": [20, 140],
}
# --- Screening ---
funnel_total = len(molecules)
pass_mw = 0
pass_logp = 0
pass_lipinski = 0
final_candidates = 0
scored = []
for m in molecules:
score = 0
max_score = 0
criteria = {}
# Check each profile criterion
checks = [
("mw", m["mw"]),
("logp", m["logp"]),
("hbd", m["hbd"]),
("hba", m["hba"]),
("tpsa", m["tpsa"]),
]
for key, val in checks:
if key in profile:
lo, hi = profile[key]
max_score += 1
in_range = lo <= val <= hi
criteria[key] = in_range
if in_range:
score += 1
# Bonus: closer to midpoint = higher score
mid = (lo + hi) / 2
rng = (hi - lo) / 2
dist = abs(val - mid) / rng if rng else 0
score += max(0, 0.5 * (1 - dist))
# QED bonus
score += m["qed"] * 2
max_score += 2
# Lipinski bonus
if m["lipinski_pass"]:
score += 1
max_score += 1
normalized_score = score / max_score if max_score else 0
# Funnel tracking — cascading filter (each stage requires passing the previous)
mw_ok = criteria.get("mw", True)
logp_ok = criteria.get("logp", True)
if mw_ok:
pass_mw += 1
if logp_ok:
pass_logp += 1
if m["lipinski_pass"]:
pass_lipinski += 1
if all(criteria.values()):
final_candidates += 1
scored.append({
**m,
"screening_score": round(normalized_score, 4),
"criteria_met": criteria,
"all_criteria_met": all(criteria.values()),
})
# Sort by score descending
scored.sort(key=lambda m: m["screening_score"], reverse=True)
# --- Tanimoto similarity matrix ---
fps = []
valid_names = []
for m in scored:
mol = Chem.MolFromSmiles(m["smiles"])
if mol:
fp = AllChem.GetMorganFingerprintAsBitVect(mol, 2, nBits=2048)
fps.append(fp)
valid_names.append(m["name"])
similarity_matrix = []
for i in range(len(fps)):
row = []
for j in range(len(fps)):
sim = DataStructs.TanimotoSimilarity(fps[i], fps[j])
row.append(round(sim, 3))
similarity_matrix.append(row)
# ---- Build report ----
html_parts = []
html_parts.append("
Candidate Screening Results
")
# Stat grid
html_parts.append('
')
for val, label in [
(str(funnel_total), "Total Screened"),
(str(pass_lipinski), "Lipinski Passes"),
(str(final_candidates), "All Criteria Met"),
(f"{scored[0]['screening_score']:.3f}" if scored else "N/A", "Top Score"),
]:
html_parts.append(
f'
"
)
for rank, m in enumerate(scored, 1):
lip_badge = ('Pass'
if m["lipinski_pass"]
else 'Fail')
crit_badge = ('Pass'
if m["all_criteria_met"]
else 'Fail')
# Highlight top 3
row_style = ' style="background:#ecfeff;font-weight:600;"' if rank <= 3 else ""
html_parts.append(
f"
{rank}
{m['name']}
"
f"
{m['screening_score']:.3f}
"
f"
{m['mw']:.1f}
{m['logp']:.2f}
"
f"
{m['qed']:.3f}
{lip_badge}
{crit_badge}
"
)
html_parts.append("
")
# Top 5 candidate cards with structures
html_parts.append("
Top 5 Candidates
")
html_parts.append('
')
for m in scored[:5]:
mol = Chem.MolFromSmiles(m["smiles"])
img_uri = _mol_to_data_uri(mol, size=(250, 250)) if mol else ""
badge_class = "badge-success" if m["all_criteria_met"] else "badge-info"
badge_text = "All Criteria Met" if m["all_criteria_met"] else "Partial Match"
html_parts.append(
f'
')
await flyte.report.replace.aio(
_wrap_report("\n".join(html_parts)),
do_flush=True,
)
output = {
"ranked_molecules": scored,
"similarity_matrix": similarity_matrix,
"similarity_labels": valid_names,
"funnel": funnel_stages,
"target_profile": profile,
}
return json.dumps(output)
def _parse_screening_json(screening_json: str) -> dict:
"""Parse screening JSON from screen_candidates, with safe defaults.
The agent must pass the exact tool return value. Partial or hand-built JSON
is tolerated for optional similarity fields only.
"""
screening = json.loads(screening_json)
if "ranked_molecules" not in screening:
raise ValueError(
"screening_json must be the exact JSON string returned by "
"screen_candidates (missing 'ranked_molecules'). Do not construct, "
"truncate, or summarize tool output."
)
screening.setdefault("similarity_matrix", [])
screening.setdefault("similarity_labels", [])
return screening
# ------------------------------------------------------------------
# Task 4: Generate final comprehensive report
# ------------------------------------------------------------------
@tool
@env.task(report=True)
async def generate_report(
molecule_dir: flyte.io.Dir,
properties_json: str,
screening_json: str,
) -> str:
"""Generate a comprehensive drug screening report.
Produces an executive summary, top candidate spotlight cards, property
distributions, chemical diversity analysis, and final recommendation.
Args:
molecule_dir: Directory from load_molecules.
properties_json: JSON from compute_properties.
screening_json: Exact verbatim JSON string returned by screen_candidates
(must include ranked_molecules, similarity_matrix, similarity_labels).
Do not construct or summarize this payload yourself.
Returns:
JSON summary with total_screened, lipinski_passes, all_criteria_met,
top_candidate, top_score, and top_3 ranked molecules.
"""
from rdkit import Chem
await flyte.report.replace.aio(
_wrap_report("
Generating Final Report...
"),
do_flush=True,
)
props = json.loads(properties_json)
screening = _parse_screening_json(screening_json)
ranked = screening["ranked_molecules"]
sim_matrix = screening["similarity_matrix"]
sim_labels = screening["similarity_labels"]
total = props["total"]
lipinski_pass = props["lipinski_pass_count"]
all_criteria = sum(1 for m in ranked if m["all_criteria_met"])
top = ranked[0] if ranked else None
html_parts = []
# --- Executive Summary ---
html_parts.append("
Drug Molecule Screening Report
")
top_name = top["name"] if top else "N/A"
top_score = f'{top["screening_score"]:.3f}' if top else "N/A"
html_parts.append(
f'
'
f'
Executive Summary
'
f'
'
f'{total} molecules were screened against the target drug profile. '
f'{lipinski_pass} passed Lipinski\'s Rule of Five, and '
f'{all_criteria} met all screening criteria. '
f'The top candidate is {top_name} '
f'with a screening score of {top_score}.
'
f'
'
)
# Stat grid
html_parts.append('
')
for val, label in [
(str(total), "Molecules Screened"),
(str(lipinski_pass), "Lipinski Passes"),
(str(all_criteria), "All Criteria Met"),
(top_score, "Top Score"),
(f'{props["avg_mw"]:.0f} Da', "Avg. Molecular Weight"),
(f'{props["avg_logp"]:.2f}', "Avg. LogP"),
]:
html_parts.append(
f'
{val}
'
f'
{label}
'
)
html_parts.append("
")
# --- Top 3 Candidate Spotlights ---
html_parts.append("
Top Candidate Spotlights
")
for rank, m in enumerate(ranked[:3], 1):
mol = Chem.MolFromSmiles(m["smiles"])
img_uri = _mol_to_data_uri(mol, size=(300, 300)) if mol else ""
medal = ["gold", "silver", "#cd7f32"][rank - 1]
medal_emoji = ["1st", "2nd", "3rd"][rank - 1]
lip_badges = ""
for rule, key in [("MW", "mw_ok"), ("LogP", "logp_ok"),
("HBD", "hbd_ok"), ("HBA", "hba_ok")]:
ok = m["lipinski"].get(key, False)
cls = "badge-success" if ok else "badge-danger"
lip_badges += f'{rule} '
html_parts.append(
f'
'
f'
'
f'
{medal_emoji}
'
f''
f'
{m["name"]}
'
f'
'
f'
'
f'
'
f'
SMILES
{m["smiles"]}
'
f'
Screening Score
{m["screening_score"]:.3f}
'
f'
Molecular Weight
{m["mw"]:.1f} Da
'
f'
LogP
{m["logp"]:.2f}
'
f'
H-Bond Donors
{m["hbd"]}
'
f'
H-Bond Acceptors
{m["hba"]}
'
f'
TPSA
{m["tpsa"]:.1f} A²
'
f'
Rotatable Bonds
{m["rotatable_bonds"]}
'
f'
QED
{m["qed"]:.4f}
'
f'
Lipinski Compliance
{lip_badges}
'
f'
'
f'
'
f'
'
)
# --- Property Distribution (box-plot style as bars with min/max/median) ---
html_parts.append("
Property Distributions
")
prop_keys = [("mw", "Molecular Weight (Da)"), ("logp", "LogP"),
("tpsa", "TPSA"), ("qed", "QED Score")]
for key, label in prop_keys:
vals = sorted([m[key] for m in ranked])
n = len(vals)
if n == 0:
continue
v_min = vals[0]
v_max = vals[-1]
median = vals[n // 2] if n % 2 == 1 else (vals[n // 2 - 1] + vals[n // 2]) / 2
q1 = vals[n // 4] if n >= 4 else v_min
q3 = vals[3 * n // 4] if n >= 4 else v_max
# Simple horizontal box-plot as SVG
box_w = 500
box_h = 50
margin_l = 10
v_range = v_max - v_min or 1
def sx(v):
return margin_l + ((v - v_min) / v_range) * (box_w - 2 * margin_l)
box_svg = (
f''
)
html_parts.append(
f'
{label}'
f'
{box_svg}
'
)
# --- Chemical Diversity ---
html_parts.append("
Chemical Diversity Analysis
")
if sim_matrix and len(sim_matrix) > 1:
# Compute average pairwise similarity (off-diagonal)
n_mols = len(sim_matrix)
off_diag = []
for i in range(n_mols):
for j in range(i + 1, n_mols):
off_diag.append(sim_matrix[i][j])
avg_sim = sum(off_diag) / len(off_diag) if off_diag else 0
max_sim = max(off_diag) if off_diag else 0
min_sim = min(off_diag) if off_diag else 0
# Find most similar pair
best_i, best_j = 0, 1
best_val = 0
for i in range(n_mols):
for j in range(i + 1, n_mols):
if sim_matrix[i][j] > best_val:
best_val = sim_matrix[i][j]
best_i, best_j = i, j
html_parts.append('
')
html_parts.append(
f'
{avg_sim:.3f}
'
f'
Avg. Pairwise Similarity
'
)
html_parts.append(
f'
{min_sim:.3f}
'
f'
Min Similarity
'
)
html_parts.append(
f'
{max_sim:.3f}
'
f'
Max Similarity
'
)
html_parts.append("
")
diversity_text = "highly diverse" if avg_sim < 0.3 else "moderately diverse" if avg_sim < 0.5 else "relatively similar"
html_parts.append(
f'
'
f'The library is {diversity_text} (avg. Tanimoto = {avg_sim:.3f}). '
f'The most similar pair is {sim_labels[best_i]} and '
f'{sim_labels[best_j]} (similarity = {best_val:.3f}).
'
)
# --- Recommendation ---
html_parts.append("
Recommendation
")
if top:
html_parts.append(
f'
'
f'
Top Candidate: {top["name"]}
'
f'
Based on the virtual screening analysis, {top["name"]} '
f'achieved the highest composite screening score of {top["screening_score"]:.3f}. '
)
reasons = []
if top["lipinski_pass"]:
reasons.append("full Lipinski Rule of Five compliance")
if top["qed"] > 0.5:
reasons.append(f"high drug-likeness (QED = {top['qed']:.3f})")
if top.get("all_criteria_met"):
reasons.append("all target profile criteria met")
if top["mw"] <= 500:
reasons.append(f"favorable molecular weight ({top['mw']:.1f} Da)")
if reasons:
html_parts.append(
f'This candidate stands out due to: {", ".join(reasons)}.
'
)
else:
html_parts.append("")
# Runner-up mentions
if len(ranked) >= 2:
html_parts.append(
f'
Runner-up candidates: '
)
runners = []
for m in ranked[1:4]:
runners.append(f'{m["name"]} (score: {m["screening_score"]:.3f})')
html_parts.append(", ".join(runners) + ".
")
html_parts.append("
")
# Final note
html_parts.append(
'
'
"This is a virtual screening analysis. All candidates should undergo "
"further computational validation (molecular dynamics, docking) and "
"experimental testing before advancing to clinical trials.
"
)
await flyte.report.replace.aio(
_wrap_report("\n".join(html_parts)),
do_flush=True,
)
# JSON summary
summary = {
"total_screened": total,
"lipinski_passes": lipinski_pass,
"all_criteria_met": all_criteria,
"top_candidate": top["name"] if top else None,
"top_score": top["screening_score"] if top else None,
"top_3": [
{"name": m["name"], "score": m["screening_score"]}
for m in ranked[:3]
],
}
return json.dumps(summary)
# ------------------------------------------------------------------
# Agent
# ------------------------------------------------------------------
# {{docs-fragment agent}}
SCREENING_AGENT_INSTRUCTIONS = """\
You are a medicinal chemistry screening strategist. You orchestrate a virtual \
screening pipeline using durable Flyte tools. You NEVER invent molecular \
properties — only RDKit tools compute them.
Workflow:
1. If target_profile is not provided in the user message, derive a JSON \
target_profile from the therapeutic brief. Valid keys: mw, logp, hbd, hba, tpsa \
(each [min, max]). Ground choices in oral bioavailability / kinase / CNS rules \
as appropriate to the brief.
2. First pass (always): load_molecules → compute_properties → \
screen_candidates → generate_report. Pass tool outputs between steps exactly \
(molecule_dir from load_molecules into compute_properties and generate_report; \
properties_json from compute_properties into screen_candidates and \
generate_report; screening_json must be the complete, unmodified string \
returned by screen_candidates — never rebuild or summarize JSON yourself).
3. Read the JSON summary returned by generate_report. Reflect:
- If all_criteria_met == 0: relax exactly ONE profile bound by ~10–20% \
and re-run screen_candidates then generate_report only, reusing the same \
molecule_dir and properties_json from the first pass.
- If all molecules pass but diversity is a stated goal: note high similarity \
in your summary; do not re-run unless brief asks for stricter filters.
- Maximum ONE rescreen iteration.
4. Finish with plain text: top candidate, rationale tied to computed metrics \
from the tool JSON, funnel interpretation, and suggested next steps (docking, \
ADMET lab tests).
If the user supplies an explicit target_profile JSON, use it as-is.
Do NOT ask the user for SMILES or molecule lists when molecules_json is empty — \
the default library is loaded automatically.
"""
screening_agent = Agent(
name="drug-screening-agent",
instructions=SCREENING_AGENT_INSTRUCTIONS,
model=MODEL,
tools=[
load_molecules,
compute_properties,
screen_candidates,
generate_report,
],
max_turns=12,
)
# {{/docs-fragment agent}}
# ------------------------------------------------------------------
# Pipeline
# ------------------------------------------------------------------
# {{docs-fragment pipeline}}
@env.task(report=True)
async def pipeline(
brief: str = "Screen the default drug library for orally bioavailable small molecules.",
molecules_json: str = "",
target_profile: str = "",
) -> str:
"""Agentic virtual drug molecule screening pipeline.
A medicinal-chemistry agent interprets the screening brief, derives or
applies a target profile, orchestrates the RDKit screening stages, and
optionally re-screens when funnel results are too narrow.
Args:
brief: Natural-language therapeutic goal (e.g. oral kinase inhibitors,
CNS-penetrant small molecules).
molecules_json: JSON mapping molecule names to SMILES strings.
Defaults to a curated library of ~15 well-known drugs.
target_profile: Optional JSON with desired property ranges that
overrides agent-derived criteria
(e.g. {"mw": [150, 500], "logp": [-0.5, 5]}).
Returns:
Agent summary with screening rationale and key results.
"""
prompt_parts = [
f"Screening brief: {brief}",
'Use molecules_json="" for the built-in default library unless provided below.',
"Compose the four stage tools in order: load_molecules → compute_properties "
"→ screen_candidates → generate_report. Pass each tool's full return value "
"verbatim to the next step (especially screening_json). Re-run "
"screen_candidates and generate_report at most once if the funnel is too narrow.",
]
if molecules_json.strip():
prompt_parts.append(f"molecules_json: {molecules_json}")
if target_profile.strip():
prompt_parts.append(f"Use this target_profile exactly: {target_profile}")
result = await screening_agent.run.aio("\n".join(prompt_parts))
return result.summary or result.error or ""
# {{/docs-fragment pipeline}}
# ------------------------------------------------------------------
# Rescreen demo — tight profile + explicit rescreen instructions
# ------------------------------------------------------------------
# Initial profile is deliberately strict (narrow MW + low LogP cap) so
# all_criteria_met is typically 0 on the default library; the brief then
# forces a single rescreen with a widened LogP window.
RESCREEN_DEMO_TARGET_PROFILE = (
'{"mw": [150, 200], "logp": [-0.5, 1.0], "hbd": [0, 1], '
'"hba": [0, 3], "tpsa": [20, 45]}'
)
RESCREEN_DEMO_TARGET_PROFILE_RESCREEN = (
'{"mw": [150, 200], "logp": [-0.5, 3.5], "hbd": [0, 1], '
'"hba": [0, 3], "tpsa": [20, 45]}'
)
RESCREEN_DEMO_BRIEF = f"""\
Two-round agentic screening demo on the default library.
**Round 1 (strict profile):** load_molecules → compute_properties → \
screen_candidates → generate_report using the initial target_profile exactly.
**Round 2 (required — do not skip):** call screen_candidates then generate_report \
again, reusing the same molecule_dir and properties_json from round 1, with this \
relaxed target_profile (wider LogP window only): \
{RESCREEN_DEMO_TARGET_PROFILE_RESCREEN}
Pass every tool return value verbatim to the next step. After both rounds, \
summarize how the funnel and top candidates changed between round 1 and round 2."""
# {{docs-fragment rescreen_demo}}
@env.task(report=True)
async def rescreen_demo() -> str:
"""Example run with a two-round execution graph (rescreen).
Round 1 uses a strict CNS-like profile; round 2 always re-runs
screen_candidates and generate_report with a widened LogP window,
reusing cached molecule_dir and properties_json.
"""
return await pipeline(
brief=RESCREEN_DEMO_BRIEF,
target_profile=RESCREEN_DEMO_TARGET_PROFILE,
)
# {{/docs-fragment rescreen_demo}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(pipeline)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/drug_molecule_screening/drug_molecule_screening.py*
From the [example directory](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/drug_molecule_screening):
```
cd v2/tutorials/drug_molecule_screening
uv run --script drug_molecule_screening.py
```
Pass a natural-language brief (the agent derives the target profile):
```
flyte run drug_molecule_screening.py pipeline \
--brief "Find oral kinase inhibitor candidates under 400 Da with moderate LogP"
```
Or pass an explicit target profile to skip agent-derived criteria:
```
flyte run drug_molecule_screening.py pipeline \
--target_profile '{"mw": [100, 400], "logp": [-0.5, 4.0]}'
```
### Two-round rescreen demo (complex execution graph)
The `rescreen_demo` task always runs two screening rounds: a strict first pass (`load_molecules` → `compute_properties` → `screen_candidates` → `generate_report`), then a second `screen_candidates` → `generate_report` with a widened LogP window reusing the same `molecule_dir` and `properties_json`. The Flyte UI shows six stage tasks instead of four.
```
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flyte>=2.5.4",
# "litellm",
# "rdkit",
# "numpy",
# "scikit-learn",
# "pillow",
# ]
# main = "pipeline"
# params = ""
# ///
"""Virtual drug molecule screening — compute properties, apply Lipinski filters, rank candidates."""
import base64
import io
import json
import logging
import math
import os
import tempfile
import flyte
import flyte.io
import flyte.report
from flyte.ai.agents import Agent, tool
MODEL = os.getenv("DRUG_SCREENING_MODEL", "claude-haiku-4-5")
# {{docs-fragment env}}
main_img = flyte.Image.from_uv_script(__file__, name="drug-molecule-screening", pre=True).with_apt_packages(
"libxrender1", "libxext6", "libexpat1",
)
env = flyte.TaskEnvironment(
name="drug-molecule-screening",
image=main_img,
resources=flyte.Resources(cpu=2, memory="6Gi"),
secrets=[
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
)
# {{/docs-fragment env}}
logging.basicConfig(level=logging.WARNING, format="%(message)s", force=True)
log = logging.getLogger(__name__)
log.setLevel(logging.INFO)
# ------------------------------------------------------------------
# Default molecule library — real SMILES for well-known drugs
# ------------------------------------------------------------------
DEFAULT_MOLECULES = {
"Aspirin": "CC(=O)OC1=CC=CC=C1C(=O)O",
"Ibuprofen": "CC(C)CC1=CC=C(C=C1)C(C)C(=O)O",
"Caffeine": "CN1C=NC2=C1C(=O)N(C(=O)N2C)C",
"Penicillin G": "CC1(C(N2C(S1)C(C2=O)NC(=O)CC3=CC=CC=C3)C(=O)O)C",
"Metformin": "CN(C)C(=N)NC(=N)N",
"Paracetamol": "CC(=O)NC1=CC=C(C=C1)O",
"Diazepam": "ClC1=CC2=C(C=C1)N(C(=O)CN=C2C3=CC=CC=C3)C",
"Omeprazole": "CC1=CN=C(C(=C1OC)C)CS(=O)C2=NC3=CC=CC=C3N2",
"Atorvastatin": "CC(C)C1=C(C(=C(N1CCC(CC(CC(=O)O)O)O)C2=CC=C(C=C2)F)C3=CC=CC=C3)C(=O)NC4=CC=CC=C4",
"Methotrexate": "CN(CC1=CN=C2N=C(N=C(N)C2=N1)N)C3=CC=C(C=C3)C(=O)NC(CCC(=O)O)C(=O)O",
"Doxorubicin": "CC1C(C(CC(O1)OC2CC(CC3=C2C(=C4C(=C3O)C(=O)C5=C(C4=O)C(=CC=C5)OC)O)(C(=O)CO)O)N)O",
"Tamoxifen": "CCC(=C(C1=CC=CC=C1)C2=CC=C(C=C2)OCCN(C)C)C3=CC=CC=C3",
"Lopinavir": "CC1=C(C(=CC=C1)C)OCC(=O)NC(CC2=CC=CC=C2)C(CC(CC3=CC=CC=C3)NC(=O)C(C(C)C)N4CCCNC4=O)O",
"Remdesivir": "CCC(CC)COC(=O)C(C)NP(=O)(OCC1C(C(C(O1)C2=CC=C3N2N=CN=C3N)O)O)OC4=CC=CC=C4",
"Erlotinib": "COCCOC1=CC2=C(C=C1OCCOC)C(=NC=N2)NC3=CC=CC(=C3)C#C",
}
# ------------------------------------------------------------------
# Report styling — pharma blue/cyan theme
# ------------------------------------------------------------------
REPORT_CSS = """
"""
def _wrap_report(html: str) -> str:
"""Wrap HTML content with report styling."""
return f'{REPORT_CSS}
{html}
'
# ------------------------------------------------------------------
# SVG chart helpers
# ------------------------------------------------------------------
def _mol_to_data_uri(mol, size: tuple[int, int] = (300, 300)) -> str:
"""Convert an RDKit molecule to a PNG base64 data URI."""
from rdkit.Chem import Draw
img = Draw.MolToImage(mol, size=size)
buf = io.BytesIO()
img.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode()
return f"data:image/png;base64,{b64}"
def _make_bar_chart(
labels: list[str],
series: dict[str, list[float]],
title: str = "",
colors: list[str] | None = None,
width: int = 700,
height: int = 340,
y_max_cap: float | None = None,
horizontal: bool = False,
value_fmt: str = ".1f",
) -> str:
"""Generate an SVG grouped bar chart.
Args:
labels: Category labels.
series: Dict mapping series name to list of values.
title: Chart title.
colors: Colors for each series.
width/height: SVG dimensions.
y_max_cap: Cap the y-axis at this value.
horizontal: If True, draw horizontal bars.
value_fmt: Format string for value labels.
Returns:
SVG string.
"""
if not labels:
return ""
default_colors = ["#0891b2", "#0e4f6e", "#06d6a0", "#a5f3fc", "#155e75"]
colors = colors or default_colors
if horizontal:
return _make_horizontal_bar_chart(labels, series, title, colors, width, height, value_fmt)
ml, mr, mt, mb = 60, 20, 40, 60
cw = width - ml - mr
ch = height - mt - mb
all_vals = [v for vals in series.values() for v in vals]
y_max = max(all_vals) if all_vals else 1
y_max_plot = y_max * 1.15 or 1
if y_max_cap is not None:
y_max_plot = min(y_max_plot, y_max_cap) or y_max_cap
n_groups = len(labels)
n_series = len(series)
group_width = cw / n_groups
bar_width = group_width * 0.7 / max(n_series, 1)
gap = group_width * 0.15
def sy(v):
return mt + ch - (v / y_max_plot) * ch
svg = [
f'")
return "\n".join(svg)
def _make_horizontal_bar_chart(
labels: list[str],
series: dict[str, list[float]],
title: str = "",
colors: list[str] | None = None,
width: int = 700,
height: int = 400,
value_fmt: str = ".1f",
) -> str:
"""Generate an SVG horizontal bar chart (sorted)."""
default_colors = ["#0891b2", "#0e4f6e", "#06d6a0"]
colors = colors or default_colors
n = len(labels)
row_height = max(22, min(35, (height - 80) // max(n, 1)))
actual_height = max(height, 80 + n * row_height)
ml, mr, mt, mb = 120, 60, 40, 20
cw = width - ml - mr
ch = actual_height - mt - mb
# Use first series
first_key = list(series.keys())[0]
vals = series[first_key]
x_max = max(vals) * 1.15 if vals else 1
svg = [
f'")
return "\n".join(svg)
def _make_heatmap(
matrix: list[list[float]],
row_labels: list[str],
col_labels: list[str],
title: str = "",
color_scale: str = "cyan",
width: int = 700,
height: int = 500,
value_fmt: str = ".2f",
) -> str:
"""Generate an SVG heatmap.
Args:
matrix: 2D list of values (rows x cols).
row_labels: Labels for rows.
col_labels: Labels for columns.
title: Chart title.
color_scale: Color scheme ("cyan", "red", "green").
width/height: SVG dimensions.
value_fmt: Format string for cell values.
Returns:
SVG string.
"""
if not matrix or not matrix[0]:
return ""
n_rows = len(matrix)
n_cols = len(matrix[0])
ml, mr, mt, mb = 110, 20, 70, 20
cw = width - ml - mr
ch = height - mt - mb
cell_w = cw / n_cols
cell_h = ch / n_rows
# Flatten to find range
flat = [v for row in matrix for v in row]
v_min = min(flat)
v_max = max(flat)
v_range = v_max - v_min or 1
def color_for(v):
t = (v - v_min) / v_range
if color_scale == "cyan":
# White to deep teal
r = int(255 - t * (255 - 14))
g = int(255 - t * (255 - 79))
b = int(255 - t * (255 - 110))
elif color_scale == "red":
r = int(255 - t * 50)
g = int(255 - t * 200)
b = int(255 - t * 200)
else: # green
r = int(255 - t * 200)
g = int(255 - t * 50)
b = int(255 - t * 200)
return f"rgb({r},{g},{b})"
svg = [
f'")
return "\n".join(svg)
def _make_scatter_plot(
points: list[dict],
x_label: str = "MW",
y_label: str = "LogP",
title: str = "",
reference_lines: list[dict] | None = None,
width: int = 700,
height: int = 400,
) -> str:
"""Generate an SVG scatter plot.
Args:
points: List of dicts with "x", "y", "label" keys.
x_label/y_label: Axis labels.
title: Chart title.
reference_lines: List of dicts with "axis" ("x"/"y"), "value", "label".
width/height: SVG dimensions.
Returns:
SVG string.
"""
if not points:
return ""
ml, mr, mt, mb = 60, 30, 40, 50
cw = width - ml - mr
ch = height - mt - mb
x_vals = [p["x"] for p in points]
y_vals = [p["y"] for p in points]
x_min, x_max = min(x_vals) * 0.9, max(x_vals) * 1.1
y_min, y_max = min(y_vals) - 1, max(y_vals) + 1
# Extend ranges to include reference lines
if reference_lines:
for rl in reference_lines:
if rl["axis"] == "x":
x_max = max(x_max, rl["value"] * 1.1)
else:
y_max = max(y_max, rl["value"] * 1.1)
x_range = x_max - x_min or 1
y_range = y_max - y_min or 1
def sx(v):
return ml + (v - x_min) / x_range * cw
def sy(v):
return mt + ch - (v - y_min) / y_range * ch
svg = [
f'")
return "\n".join(svg)
def _make_funnel(
stages: list[dict],
title: str = "",
width: int = 600,
height: int = 400,
) -> str:
"""Generate an SVG funnel visualization.
Args:
stages: List of dicts with "label", "count", "total" keys.
title: Chart title.
width/height: SVG dimensions.
Returns:
SVG string.
"""
if not stages:
return ""
n = len(stages)
mt = 50
mb = 20
available_h = height - mt - mb
stage_h = available_h / n
cx = width / 2
# Color gradient from light cyan to deep teal
colors = []
for i in range(n):
t = i / max(n - 1, 1)
r = int(207 - t * (207 - 14))
g = int(250 - t * (250 - 79))
b = int(254 - t * (254 - 110))
colors.append(f"rgb({r},{g},{b})")
svg = [
f'")
return "\n".join(svg)
# ------------------------------------------------------------------
# Task 1: Load and validate molecules
# ------------------------------------------------------------------
@tool
@env.task(cache="auto")
async def load_molecules(
molecules_json: str = "",
) -> flyte.io.Dir:
"""Parse SMILES strings, validate with RDKit, generate 2D depictions.
Args:
molecules_json: JSON string mapping molecule names to SMILES.
Defaults to a curated library of ~15 well-known drugs.
Returns:
flyte.io.Dir containing molecule data (JSON + PNG depictions).
Pass this directory to compute_properties and generate_report.
"""
from rdkit import Chem
from rdkit.Chem import Draw
if molecules_json.strip():
molecules = json.loads(molecules_json)
else:
molecules = DEFAULT_MOLECULES
out_dir = tempfile.mkdtemp(prefix="mol_library_")
results = []
valid_count = 0
invalid_count = 0
log.info(f"Parsing {len(molecules)} molecules...")
for name, smiles in molecules.items():
mol = Chem.MolFromSmiles(smiles)
if mol is None:
log.warning(f" [INVALID] {name}: {smiles}")
invalid_count += 1
continue
valid_count += 1
# Generate 2D depiction as PNG
img = Draw.MolToImage(mol, size=(300, 300))
img_path = os.path.join(out_dir, f"{name.replace(' ', '_')}.png")
img.save(img_path)
results.append({
"name": name,
"smiles": smiles,
"valid": True,
"image_file": os.path.basename(img_path),
})
# Save molecule manifest
manifest = {
"total": len(molecules),
"valid": valid_count,
"invalid": invalid_count,
"molecules": results,
}
manifest_path = os.path.join(out_dir, "manifest.json")
with open(manifest_path, "w") as f:
json.dump(manifest, f, indent=2)
log.info(f"Loaded {valid_count} valid molecules ({invalid_count} invalid)")
return await flyte.io.Dir.from_local(out_dir)
# ------------------------------------------------------------------
# Task 2: Compute physicochemical properties
# ------------------------------------------------------------------
@tool
@env.task(report=True)
async def compute_properties(
molecule_dir: flyte.io.Dir,
) -> str:
"""Compute drug-likeness properties for all molecules.
Computes MW, LogP, HBD, HBA, TPSA, rotatable bonds, formal charge,
ring count, QED, and Lipinski Rule of Five compliance.
Args:
molecule_dir: Directory from load_molecules.
Returns:
JSON string with all computed properties. Pass to screen_candidates
and generate_report.
"""
from rdkit import Chem
from rdkit.Chem import Descriptors, Lipinski
from rdkit.Chem.QED import qed
# --- Loading report ---
await flyte.report.replace.aio(
_wrap_report("
Computing Molecular Properties...
"
"
Analyzing physicochemical descriptors for all molecules.
"),
do_flush=True,
)
mol_dir = await molecule_dir.download()
with open(os.path.join(mol_dir, "manifest.json")) as f:
manifest = json.load(f)
molecules_data = []
lipinski_pass = 0
for mol_info in manifest["molecules"]:
mol = Chem.MolFromSmiles(mol_info["smiles"])
if mol is None:
continue
mw = Descriptors.MolWt(mol)
logp = Descriptors.MolLogP(mol)
hbd = Lipinski.NumHDonors(mol)
hba = Lipinski.NumHAcceptors(mol)
tpsa = Descriptors.TPSA(mol)
rotatable = Lipinski.NumRotatableBonds(mol)
formal_charge = Chem.GetFormalCharge(mol)
num_rings = Lipinski.RingCount(mol)
qed_score = qed(mol)
# Lipinski Rule of Five
lipinski = {
"mw_ok": mw <= 500,
"logp_ok": logp <= 5,
"hbd_ok": hbd <= 5,
"hba_ok": hba <= 10,
}
lipinski_all = all(lipinski.values())
if lipinski_all:
lipinski_pass += 1
# Read image for data URI
img_path = os.path.join(mol_dir, mol_info["image_file"])
data_uri = ""
if os.path.exists(img_path):
with open(img_path, "rb") as img_f:
b64 = base64.b64encode(img_f.read()).decode()
data_uri = f"data:image/png;base64,{b64}"
molecules_data.append({
"name": mol_info["name"],
"smiles": mol_info["smiles"],
"mw": round(mw, 2),
"logp": round(logp, 2),
"hbd": hbd,
"hba": hba,
"tpsa": round(tpsa, 2),
"rotatable_bonds": rotatable,
"formal_charge": formal_charge,
"num_rings": num_rings,
"qed": round(qed_score, 4),
"lipinski": lipinski,
"lipinski_pass": lipinski_all,
"image_data_uri": data_uri,
})
total = len(molecules_data)
avg_mw = sum(m["mw"] for m in molecules_data) / total if total else 0
avg_logp = sum(m["logp"] for m in molecules_data) / total if total else 0
lipinski_rate = lipinski_pass / total * 100 if total else 0
# ---- Build report ----
html_parts = []
# Header
html_parts.append("
Molecular Properties Analysis
")
# Stat grid
html_parts.append('
')
for val, label in [
(str(total), "Total Molecules"),
(f"{lipinski_rate:.0f}%", "Lipinski Pass Rate"),
(f"{avg_mw:.1f}", "Avg. MW (Da)"),
(f"{avg_logp:.2f}", "Avg. LogP"),
]:
html_parts.append(
f'
{val}
'
f'
{label}
'
)
html_parts.append("
")
# Molecule gallery
html_parts.append("
Molecule Library
")
html_parts.append('
')
for m in molecules_data:
if m["image_data_uri"]:
badge_class = "badge-success" if m["lipinski_pass"] else "badge-danger"
badge_text = "Lipinski Pass" if m["lipinski_pass"] else "Lipinski Fail"
html_parts.append(
f'
'
f''
f'
{m["name"]}
'
f'
MW: {m["mw"]:.1f} | LogP: {m["logp"]:.2f}
'
f'
{badge_text}
'
f'
'
)
html_parts.append("
")
# MW bar chart (horizontal, sorted)
sorted_by_mw = sorted(molecules_data, key=lambda m: m["mw"], reverse=True)
mw_labels = [m["name"] for m in sorted_by_mw]
mw_vals = [m["mw"] for m in sorted_by_mw]
mw_chart = _make_bar_chart(
mw_labels, {"MW (Da)": mw_vals},
title="Molecular Weight Distribution",
horizontal=True,
width=700, height=max(300, len(mw_labels) * 30 + 80),
value_fmt=".1f",
)
html_parts.append("
')
# Property heatmap (molecules x properties)
prop_names = ["MW", "LogP", "HBD", "HBA", "TPSA", "Rot. Bonds"]
# Normalize each property to 0-1 for heatmap
raw_matrix = []
for m in molecules_data:
raw_matrix.append([m["mw"], m["logp"], m["hbd"], m["hba"], m["tpsa"], m["rotatable_bonds"]])
# Normalize per column
n_props = len(prop_names)
col_min = [min(row[c] for row in raw_matrix) for c in range(n_props)]
col_max = [max(row[c] for row in raw_matrix) for c in range(n_props)]
norm_matrix = []
for row in raw_matrix:
norm_row = []
for c in range(n_props):
rng = col_max[c] - col_min[c]
norm_row.append((row[c] - col_min[c]) / rng if rng else 0.5)
norm_matrix.append(norm_row)
heatmap_labels = [m["name"] for m in molecules_data]
heatmap = _make_heatmap(
norm_matrix, heatmap_labels, prop_names,
title="Normalized Property Heatmap",
color_scale="cyan",
width=700,
height=max(400, len(heatmap_labels) * 28 + 100),
)
html_parts.append("
")
for m in molecules_data:
lip = m["lipinski"]
def _badge(ok):
if ok:
return 'Pass'
return 'Fail'
overall_badge = _badge(m["lipinski_pass"])
html_parts.append(
f'
{m["name"]}
'
f'
{_badge(lip["mw_ok"])}
'
f'
{_badge(lip["logp_ok"])}
'
f'
{_badge(lip["hbd_ok"])}
'
f'
{_badge(lip["hba_ok"])}
'
f'
{overall_badge}
'
)
html_parts.append("
")
# QED bar chart
sorted_by_qed = sorted(molecules_data, key=lambda m: m["qed"], reverse=True)
qed_labels = [m["name"] for m in sorted_by_qed]
qed_vals = [m["qed"] for m in sorted_by_qed]
qed_chart = _make_bar_chart(
qed_labels, {"QED Score": qed_vals},
title="Drug-likeness (QED Score)",
horizontal=True,
width=700, height=max(300, len(qed_labels) * 30 + 80),
value_fmt=".3f",
colors=["#06d6a0"],
)
html_parts.append("
Drug-likeness (QED)
")
html_parts.append(f'
{qed_chart}
')
# Flush full report
await flyte.report.replace.aio(
_wrap_report("\n".join(html_parts)),
do_flush=True,
)
# Return properties as JSON (strip image data URIs to reduce size)
output = {
"total": total,
"lipinski_pass_count": lipinski_pass,
"lipinski_pass_rate": round(lipinski_rate, 2),
"avg_mw": round(avg_mw, 2),
"avg_logp": round(avg_logp, 2),
"molecules": [
{k: v for k, v in m.items() if k != "image_data_uri"}
for m in molecules_data
],
}
return json.dumps(output)
# ------------------------------------------------------------------
# Task 3: Screen candidates against target profile
# ------------------------------------------------------------------
@tool
@env.task(report=True)
async def screen_candidates(
properties_json: str,
target_profile: str = "",
) -> str:
"""Screen molecules against a target drug profile and rank candidates.
Scores each molecule on how well it matches the target profile, computes
pairwise Tanimoto similarity, and produces a ranked list.
Args:
properties_json: JSON from compute_properties.
target_profile: JSON string with desired property ranges
(e.g. {"mw": [150, 500], "logp": [-0.5, 5.0]}).
Returns:
JSON string with ranked_molecules, similarity_matrix, similarity_labels,
funnel, and target_profile. Pass the full return value verbatim to
generate_report along with molecule_dir and properties_json.
"""
from rdkit import Chem, DataStructs
from rdkit.Chem import AllChem
await flyte.report.replace.aio(
_wrap_report("
Screening Candidates...
"
"
Evaluating molecules against the target drug profile.
"),
do_flush=True,
)
props = json.loads(properties_json)
molecules = props["molecules"]
# Default target profile
if target_profile.strip():
profile = json.loads(target_profile)
else:
profile = {
"mw": [150, 500],
"logp": [-0.5, 5.0],
"hbd": [0, 5],
"hba": [0, 10],
"tpsa": [20, 140],
}
# --- Screening ---
funnel_total = len(molecules)
pass_mw = 0
pass_logp = 0
pass_lipinski = 0
final_candidates = 0
scored = []
for m in molecules:
score = 0
max_score = 0
criteria = {}
# Check each profile criterion
checks = [
("mw", m["mw"]),
("logp", m["logp"]),
("hbd", m["hbd"]),
("hba", m["hba"]),
("tpsa", m["tpsa"]),
]
for key, val in checks:
if key in profile:
lo, hi = profile[key]
max_score += 1
in_range = lo <= val <= hi
criteria[key] = in_range
if in_range:
score += 1
# Bonus: closer to midpoint = higher score
mid = (lo + hi) / 2
rng = (hi - lo) / 2
dist = abs(val - mid) / rng if rng else 0
score += max(0, 0.5 * (1 - dist))
# QED bonus
score += m["qed"] * 2
max_score += 2
# Lipinski bonus
if m["lipinski_pass"]:
score += 1
max_score += 1
normalized_score = score / max_score if max_score else 0
# Funnel tracking — cascading filter (each stage requires passing the previous)
mw_ok = criteria.get("mw", True)
logp_ok = criteria.get("logp", True)
if mw_ok:
pass_mw += 1
if logp_ok:
pass_logp += 1
if m["lipinski_pass"]:
pass_lipinski += 1
if all(criteria.values()):
final_candidates += 1
scored.append({
**m,
"screening_score": round(normalized_score, 4),
"criteria_met": criteria,
"all_criteria_met": all(criteria.values()),
})
# Sort by score descending
scored.sort(key=lambda m: m["screening_score"], reverse=True)
# --- Tanimoto similarity matrix ---
fps = []
valid_names = []
for m in scored:
mol = Chem.MolFromSmiles(m["smiles"])
if mol:
fp = AllChem.GetMorganFingerprintAsBitVect(mol, 2, nBits=2048)
fps.append(fp)
valid_names.append(m["name"])
similarity_matrix = []
for i in range(len(fps)):
row = []
for j in range(len(fps)):
sim = DataStructs.TanimotoSimilarity(fps[i], fps[j])
row.append(round(sim, 3))
similarity_matrix.append(row)
# ---- Build report ----
html_parts = []
html_parts.append("
Candidate Screening Results
")
# Stat grid
html_parts.append('
')
for val, label in [
(str(funnel_total), "Total Screened"),
(str(pass_lipinski), "Lipinski Passes"),
(str(final_candidates), "All Criteria Met"),
(f"{scored[0]['screening_score']:.3f}" if scored else "N/A", "Top Score"),
]:
html_parts.append(
f'
"
)
for rank, m in enumerate(scored, 1):
lip_badge = ('Pass'
if m["lipinski_pass"]
else 'Fail')
crit_badge = ('Pass'
if m["all_criteria_met"]
else 'Fail')
# Highlight top 3
row_style = ' style="background:#ecfeff;font-weight:600;"' if rank <= 3 else ""
html_parts.append(
f"
{rank}
{m['name']}
"
f"
{m['screening_score']:.3f}
"
f"
{m['mw']:.1f}
{m['logp']:.2f}
"
f"
{m['qed']:.3f}
{lip_badge}
{crit_badge}
"
)
html_parts.append("
")
# Top 5 candidate cards with structures
html_parts.append("
Top 5 Candidates
")
html_parts.append('
')
for m in scored[:5]:
mol = Chem.MolFromSmiles(m["smiles"])
img_uri = _mol_to_data_uri(mol, size=(250, 250)) if mol else ""
badge_class = "badge-success" if m["all_criteria_met"] else "badge-info"
badge_text = "All Criteria Met" if m["all_criteria_met"] else "Partial Match"
html_parts.append(
f'
')
await flyte.report.replace.aio(
_wrap_report("\n".join(html_parts)),
do_flush=True,
)
output = {
"ranked_molecules": scored,
"similarity_matrix": similarity_matrix,
"similarity_labels": valid_names,
"funnel": funnel_stages,
"target_profile": profile,
}
return json.dumps(output)
def _parse_screening_json(screening_json: str) -> dict:
"""Parse screening JSON from screen_candidates, with safe defaults.
The agent must pass the exact tool return value. Partial or hand-built JSON
is tolerated for optional similarity fields only.
"""
screening = json.loads(screening_json)
if "ranked_molecules" not in screening:
raise ValueError(
"screening_json must be the exact JSON string returned by "
"screen_candidates (missing 'ranked_molecules'). Do not construct, "
"truncate, or summarize tool output."
)
screening.setdefault("similarity_matrix", [])
screening.setdefault("similarity_labels", [])
return screening
# ------------------------------------------------------------------
# Task 4: Generate final comprehensive report
# ------------------------------------------------------------------
@tool
@env.task(report=True)
async def generate_report(
molecule_dir: flyte.io.Dir,
properties_json: str,
screening_json: str,
) -> str:
"""Generate a comprehensive drug screening report.
Produces an executive summary, top candidate spotlight cards, property
distributions, chemical diversity analysis, and final recommendation.
Args:
molecule_dir: Directory from load_molecules.
properties_json: JSON from compute_properties.
screening_json: Exact verbatim JSON string returned by screen_candidates
(must include ranked_molecules, similarity_matrix, similarity_labels).
Do not construct or summarize this payload yourself.
Returns:
JSON summary with total_screened, lipinski_passes, all_criteria_met,
top_candidate, top_score, and top_3 ranked molecules.
"""
from rdkit import Chem
await flyte.report.replace.aio(
_wrap_report("
Generating Final Report...
"),
do_flush=True,
)
props = json.loads(properties_json)
screening = _parse_screening_json(screening_json)
ranked = screening["ranked_molecules"]
sim_matrix = screening["similarity_matrix"]
sim_labels = screening["similarity_labels"]
total = props["total"]
lipinski_pass = props["lipinski_pass_count"]
all_criteria = sum(1 for m in ranked if m["all_criteria_met"])
top = ranked[0] if ranked else None
html_parts = []
# --- Executive Summary ---
html_parts.append("
Drug Molecule Screening Report
")
top_name = top["name"] if top else "N/A"
top_score = f'{top["screening_score"]:.3f}' if top else "N/A"
html_parts.append(
f'
'
f'
Executive Summary
'
f'
'
f'{total} molecules were screened against the target drug profile. '
f'{lipinski_pass} passed Lipinski\'s Rule of Five, and '
f'{all_criteria} met all screening criteria. '
f'The top candidate is {top_name} '
f'with a screening score of {top_score}.
'
f'
'
)
# Stat grid
html_parts.append('
')
for val, label in [
(str(total), "Molecules Screened"),
(str(lipinski_pass), "Lipinski Passes"),
(str(all_criteria), "All Criteria Met"),
(top_score, "Top Score"),
(f'{props["avg_mw"]:.0f} Da', "Avg. Molecular Weight"),
(f'{props["avg_logp"]:.2f}', "Avg. LogP"),
]:
html_parts.append(
f'
{val}
'
f'
{label}
'
)
html_parts.append("
")
# --- Top 3 Candidate Spotlights ---
html_parts.append("
Top Candidate Spotlights
")
for rank, m in enumerate(ranked[:3], 1):
mol = Chem.MolFromSmiles(m["smiles"])
img_uri = _mol_to_data_uri(mol, size=(300, 300)) if mol else ""
medal = ["gold", "silver", "#cd7f32"][rank - 1]
medal_emoji = ["1st", "2nd", "3rd"][rank - 1]
lip_badges = ""
for rule, key in [("MW", "mw_ok"), ("LogP", "logp_ok"),
("HBD", "hbd_ok"), ("HBA", "hba_ok")]:
ok = m["lipinski"].get(key, False)
cls = "badge-success" if ok else "badge-danger"
lip_badges += f'{rule} '
html_parts.append(
f'
'
f'
'
f'
{medal_emoji}
'
f''
f'
{m["name"]}
'
f'
'
f'
'
f'
'
f'
SMILES
{m["smiles"]}
'
f'
Screening Score
{m["screening_score"]:.3f}
'
f'
Molecular Weight
{m["mw"]:.1f} Da
'
f'
LogP
{m["logp"]:.2f}
'
f'
H-Bond Donors
{m["hbd"]}
'
f'
H-Bond Acceptors
{m["hba"]}
'
f'
TPSA
{m["tpsa"]:.1f} A²
'
f'
Rotatable Bonds
{m["rotatable_bonds"]}
'
f'
QED
{m["qed"]:.4f}
'
f'
Lipinski Compliance
{lip_badges}
'
f'
'
f'
'
f'
'
)
# --- Property Distribution (box-plot style as bars with min/max/median) ---
html_parts.append("
Property Distributions
")
prop_keys = [("mw", "Molecular Weight (Da)"), ("logp", "LogP"),
("tpsa", "TPSA"), ("qed", "QED Score")]
for key, label in prop_keys:
vals = sorted([m[key] for m in ranked])
n = len(vals)
if n == 0:
continue
v_min = vals[0]
v_max = vals[-1]
median = vals[n // 2] if n % 2 == 1 else (vals[n // 2 - 1] + vals[n // 2]) / 2
q1 = vals[n // 4] if n >= 4 else v_min
q3 = vals[3 * n // 4] if n >= 4 else v_max
# Simple horizontal box-plot as SVG
box_w = 500
box_h = 50
margin_l = 10
v_range = v_max - v_min or 1
def sx(v):
return margin_l + ((v - v_min) / v_range) * (box_w - 2 * margin_l)
box_svg = (
f''
)
html_parts.append(
f'
{label}'
f'
{box_svg}
'
)
# --- Chemical Diversity ---
html_parts.append("
Chemical Diversity Analysis
")
if sim_matrix and len(sim_matrix) > 1:
# Compute average pairwise similarity (off-diagonal)
n_mols = len(sim_matrix)
off_diag = []
for i in range(n_mols):
for j in range(i + 1, n_mols):
off_diag.append(sim_matrix[i][j])
avg_sim = sum(off_diag) / len(off_diag) if off_diag else 0
max_sim = max(off_diag) if off_diag else 0
min_sim = min(off_diag) if off_diag else 0
# Find most similar pair
best_i, best_j = 0, 1
best_val = 0
for i in range(n_mols):
for j in range(i + 1, n_mols):
if sim_matrix[i][j] > best_val:
best_val = sim_matrix[i][j]
best_i, best_j = i, j
html_parts.append('
')
html_parts.append(
f'
{avg_sim:.3f}
'
f'
Avg. Pairwise Similarity
'
)
html_parts.append(
f'
{min_sim:.3f}
'
f'
Min Similarity
'
)
html_parts.append(
f'
{max_sim:.3f}
'
f'
Max Similarity
'
)
html_parts.append("
")
diversity_text = "highly diverse" if avg_sim < 0.3 else "moderately diverse" if avg_sim < 0.5 else "relatively similar"
html_parts.append(
f'
'
f'The library is {diversity_text} (avg. Tanimoto = {avg_sim:.3f}). '
f'The most similar pair is {sim_labels[best_i]} and '
f'{sim_labels[best_j]} (similarity = {best_val:.3f}).
'
)
# --- Recommendation ---
html_parts.append("
Recommendation
")
if top:
html_parts.append(
f'
'
f'
Top Candidate: {top["name"]}
'
f'
Based on the virtual screening analysis, {top["name"]} '
f'achieved the highest composite screening score of {top["screening_score"]:.3f}. '
)
reasons = []
if top["lipinski_pass"]:
reasons.append("full Lipinski Rule of Five compliance")
if top["qed"] > 0.5:
reasons.append(f"high drug-likeness (QED = {top['qed']:.3f})")
if top.get("all_criteria_met"):
reasons.append("all target profile criteria met")
if top["mw"] <= 500:
reasons.append(f"favorable molecular weight ({top['mw']:.1f} Da)")
if reasons:
html_parts.append(
f'This candidate stands out due to: {", ".join(reasons)}.
'
)
else:
html_parts.append("")
# Runner-up mentions
if len(ranked) >= 2:
html_parts.append(
f'
Runner-up candidates: '
)
runners = []
for m in ranked[1:4]:
runners.append(f'{m["name"]} (score: {m["screening_score"]:.3f})')
html_parts.append(", ".join(runners) + ".
")
html_parts.append("
")
# Final note
html_parts.append(
'
'
"This is a virtual screening analysis. All candidates should undergo "
"further computational validation (molecular dynamics, docking) and "
"experimental testing before advancing to clinical trials.
"
)
await flyte.report.replace.aio(
_wrap_report("\n".join(html_parts)),
do_flush=True,
)
# JSON summary
summary = {
"total_screened": total,
"lipinski_passes": lipinski_pass,
"all_criteria_met": all_criteria,
"top_candidate": top["name"] if top else None,
"top_score": top["screening_score"] if top else None,
"top_3": [
{"name": m["name"], "score": m["screening_score"]}
for m in ranked[:3]
],
}
return json.dumps(summary)
# ------------------------------------------------------------------
# Agent
# ------------------------------------------------------------------
# {{docs-fragment agent}}
SCREENING_AGENT_INSTRUCTIONS = """\
You are a medicinal chemistry screening strategist. You orchestrate a virtual \
screening pipeline using durable Flyte tools. You NEVER invent molecular \
properties — only RDKit tools compute them.
Workflow:
1. If target_profile is not provided in the user message, derive a JSON \
target_profile from the therapeutic brief. Valid keys: mw, logp, hbd, hba, tpsa \
(each [min, max]). Ground choices in oral bioavailability / kinase / CNS rules \
as appropriate to the brief.
2. First pass (always): load_molecules → compute_properties → \
screen_candidates → generate_report. Pass tool outputs between steps exactly \
(molecule_dir from load_molecules into compute_properties and generate_report; \
properties_json from compute_properties into screen_candidates and \
generate_report; screening_json must be the complete, unmodified string \
returned by screen_candidates — never rebuild or summarize JSON yourself).
3. Read the JSON summary returned by generate_report. Reflect:
- If all_criteria_met == 0: relax exactly ONE profile bound by ~10–20% \
and re-run screen_candidates then generate_report only, reusing the same \
molecule_dir and properties_json from the first pass.
- If all molecules pass but diversity is a stated goal: note high similarity \
in your summary; do not re-run unless brief asks for stricter filters.
- Maximum ONE rescreen iteration.
4. Finish with plain text: top candidate, rationale tied to computed metrics \
from the tool JSON, funnel interpretation, and suggested next steps (docking, \
ADMET lab tests).
If the user supplies an explicit target_profile JSON, use it as-is.
Do NOT ask the user for SMILES or molecule lists when molecules_json is empty — \
the default library is loaded automatically.
"""
screening_agent = Agent(
name="drug-screening-agent",
instructions=SCREENING_AGENT_INSTRUCTIONS,
model=MODEL,
tools=[
load_molecules,
compute_properties,
screen_candidates,
generate_report,
],
max_turns=12,
)
# {{/docs-fragment agent}}
# ------------------------------------------------------------------
# Pipeline
# ------------------------------------------------------------------
# {{docs-fragment pipeline}}
@env.task(report=True)
async def pipeline(
brief: str = "Screen the default drug library for orally bioavailable small molecules.",
molecules_json: str = "",
target_profile: str = "",
) -> str:
"""Agentic virtual drug molecule screening pipeline.
A medicinal-chemistry agent interprets the screening brief, derives or
applies a target profile, orchestrates the RDKit screening stages, and
optionally re-screens when funnel results are too narrow.
Args:
brief: Natural-language therapeutic goal (e.g. oral kinase inhibitors,
CNS-penetrant small molecules).
molecules_json: JSON mapping molecule names to SMILES strings.
Defaults to a curated library of ~15 well-known drugs.
target_profile: Optional JSON with desired property ranges that
overrides agent-derived criteria
(e.g. {"mw": [150, 500], "logp": [-0.5, 5]}).
Returns:
Agent summary with screening rationale and key results.
"""
prompt_parts = [
f"Screening brief: {brief}",
'Use molecules_json="" for the built-in default library unless provided below.',
"Compose the four stage tools in order: load_molecules → compute_properties "
"→ screen_candidates → generate_report. Pass each tool's full return value "
"verbatim to the next step (especially screening_json). Re-run "
"screen_candidates and generate_report at most once if the funnel is too narrow.",
]
if molecules_json.strip():
prompt_parts.append(f"molecules_json: {molecules_json}")
if target_profile.strip():
prompt_parts.append(f"Use this target_profile exactly: {target_profile}")
result = await screening_agent.run.aio("\n".join(prompt_parts))
return result.summary or result.error or ""
# {{/docs-fragment pipeline}}
# ------------------------------------------------------------------
# Rescreen demo — tight profile + explicit rescreen instructions
# ------------------------------------------------------------------
# Initial profile is deliberately strict (narrow MW + low LogP cap) so
# all_criteria_met is typically 0 on the default library; the brief then
# forces a single rescreen with a widened LogP window.
RESCREEN_DEMO_TARGET_PROFILE = (
'{"mw": [150, 200], "logp": [-0.5, 1.0], "hbd": [0, 1], '
'"hba": [0, 3], "tpsa": [20, 45]}'
)
RESCREEN_DEMO_TARGET_PROFILE_RESCREEN = (
'{"mw": [150, 200], "logp": [-0.5, 3.5], "hbd": [0, 1], '
'"hba": [0, 3], "tpsa": [20, 45]}'
)
RESCREEN_DEMO_BRIEF = f"""\
Two-round agentic screening demo on the default library.
**Round 1 (strict profile):** load_molecules → compute_properties → \
screen_candidates → generate_report using the initial target_profile exactly.
**Round 2 (required — do not skip):** call screen_candidates then generate_report \
again, reusing the same molecule_dir and properties_json from round 1, with this \
relaxed target_profile (wider LogP window only): \
{RESCREEN_DEMO_TARGET_PROFILE_RESCREEN}
Pass every tool return value verbatim to the next step. After both rounds, \
summarize how the funnel and top candidates changed between round 1 and round 2."""
# {{docs-fragment rescreen_demo}}
@env.task(report=True)
async def rescreen_demo() -> str:
"""Example run with a two-round execution graph (rescreen).
Round 1 uses a strict CNS-like profile; round 2 always re-runs
screen_candidates and generate_report with a widened LogP window,
reusing cached molecule_dir and properties_json.
"""
return await pipeline(
brief=RESCREEN_DEMO_BRIEF,
target_profile=RESCREEN_DEMO_TARGET_PROFILE,
)
# {{/docs-fragment rescreen_demo}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(pipeline)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/drug_molecule_screening/drug_molecule_screening.py*
```
flyte run drug_molecule_screening.py rescreen_demo
```
Or pass the same inputs to `pipeline` directly:
```
flyte run drug_molecule_screening.py pipeline \
--brief "Screen the default library. If all_criteria_met is 0 after generate_report, re-run screen_candidates and generate_report with target_profile {\"mw\": [150, 200], \"logp\": [-0.5, 3.5], \"hbd\": [0, 1], \"hba\": [0, 3], \"tpsa\": [20, 45]}." \
--target_profile '{"mw": [150, 200], "logp": [-0.5, 1.0], "hbd": [0, 1], "hba": [0, 3], "tpsa": [20, 45]}'
```
Open the run URL and follow the report panel for funnel charts, property distributions, top-candidate spotlights, and the agent's final screening summary. A successful rescreen demo shows two rounds of `screen_candidates` and `generate_report` in the action tree.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/geospatial ===
# Geospatial
Tutorials for satellite imagery, remote sensing, and earth and atmospheric modeling workloads.
### **Geospatial > GPU-accelerated climate modeling**
Run ensemble atmospheric simulations on H200 GPUs with multi-source data ingestion and real-time extreme event detection.
### **Geospatial > Satellite image classification**
Build a production-grade EfficientNet pipeline for land-use classification with caching, experiment tracking, and reporting.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/geospatial/climate-modeling ===
# GPU-accelerated climate modeling
Climate modeling is hard for two reasons: data and compute. Satellite imagery arrives continuously from multiple sources. Reanalysis datasets have to be pulled from remote APIs. Weather station data shows up in different formats and schemas. And once all of that is finally in one place, running atmospheric physics simulations demands serious GPU compute.
In practice, many climate workflows are held together with scripts, cron jobs, and a lot of manual babysitting. Data ingestion breaks without warning. GPU jobs run overnight with little visibility into what's happening. When something interesting shows up in a simulation, like a developing hurricane, no one notices until the job finishes hours later.
In this tutorial, we build a production-grade climate modeling pipeline using Flyte. We ingest data from three different sources in parallel, combine it with Dask, run ensemble atmospheric simulations on H200 GPUs, detect extreme weather events as they emerge, and visualize everything in a live dashboard. The entire pipeline is orchestrated, cached, and fault-tolerant, so it can run reliably at scale.
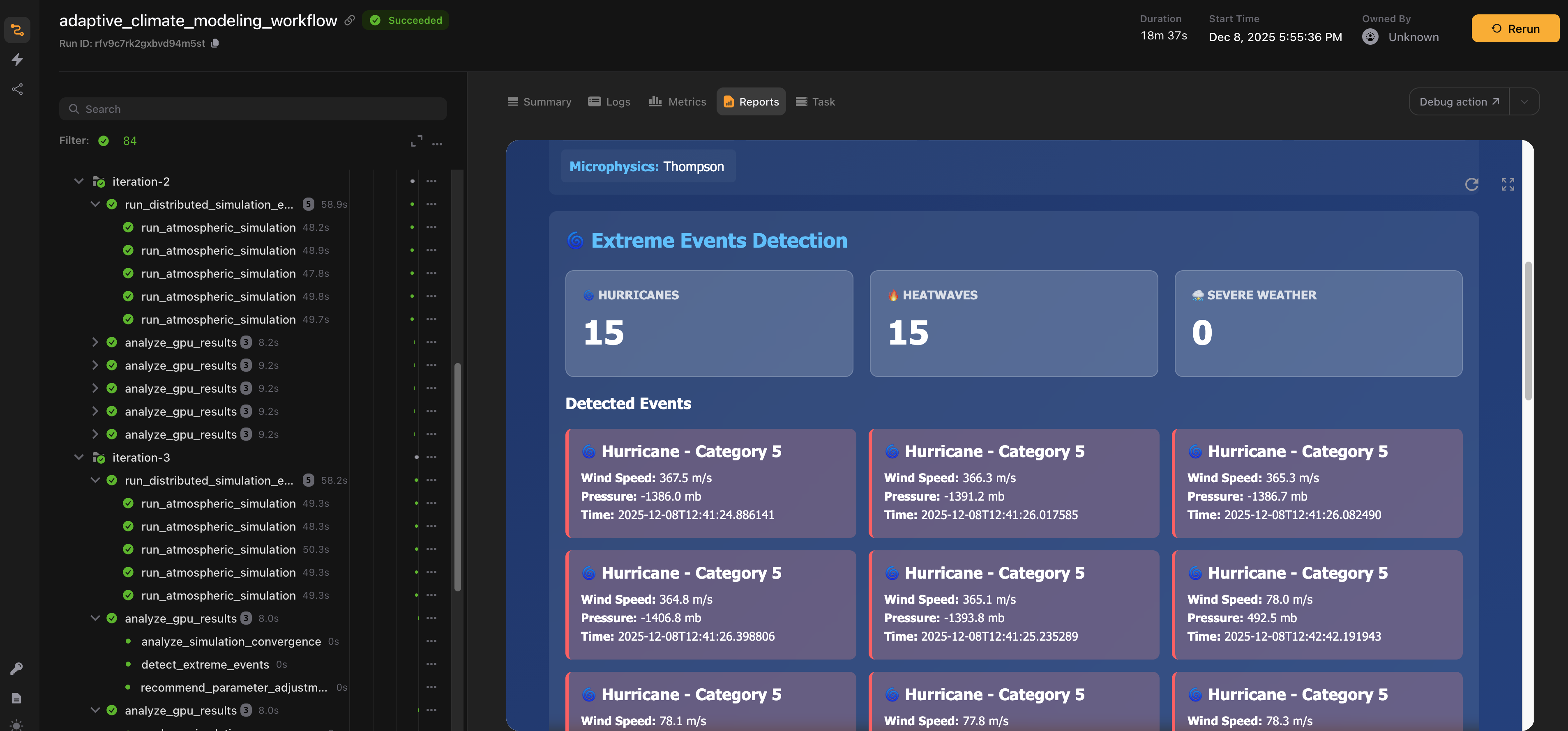
> [!NOTE]
> Full code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/climate_modeling/simulation.py).
## Overview
We're building an ensemble weather forecasting system. Ensemble forecasting runs the same simulation multiple times with slightly different initial conditions. This quantifies forecast uncertainty. Instead of saying "the temperature will be 25°C", we can say "the temperature will be 24-26°C with 90% confidence".
The pipeline has five stages:
1. **Data ingestion**: Pull satellite imagery from NOAA GOES, reanalysis data from ERA5, and surface observations from weather stations in parallel.
2. **Preprocessing**: Fuse the datasets, interpolate to a common grid, and run quality control using Dask for distributed computation.
3. **GPU simulation**: Run ensemble atmospheric physics on H200 GPUs. Each ensemble member evolves independently. PyTorch handles the tensor operations; `torch.compile` optimizes the kernels.
4. **Event detection**: Monitor for hurricanes (high wind + low pressure) and heatwaves during simulation. When extreme events are detected, the pipeline can adaptively refine the grid resolution.
5. **Real-time reporting**: Stream metrics to a live Flyte Reports dashboard showing convergence and detected events.
This workflow is a good example of where Flyte shines!
- **Parallel data ingestion**: Three different data sources, three different APIs, all running concurrently. Flyte's async task execution handles this naturally.
- **Resource heterogeneity**: Data ingestion needs CPU and network. Preprocessing needs a Dask cluster. Simulation needs GPUs. Flyte provisions exactly what each stage needs.
- **Caching**: ERA5 data fetches can take minutes. Run the pipeline twice with the same date range, and Flyte skips the fetch entirely.
- **Adaptive workflows**: When a hurricane is detected, we can dynamically refine the simulation. Flyte makes this kind of conditional logic straightforward.
## Implementation
### Dependencies and container image
```
import asyncio
import gc
import io
import json
import os
import tempfile
from dataclasses import dataclass
from datetime import datetime, timedelta
from typing import Literal
import flyte
import numpy as np
import pandas as pd
import xarray as xr
from flyte.io import File
from flyteplugins.dask import Dask, Scheduler, WorkerGroup
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
The key imports include `xarray` for multi-dimensional climate data, `flyteplugins.dask` for distributed preprocessing, and `flyte` for orchestration.
```
climate_image = (
flyte.Image.from_debian_base(name="climate_modeling_h200")
.with_apt_packages(
"libnetcdf-dev", # NetCDF for climate data
"libhdf5-dev", # HDF5 for large datasets
"libeccodes-dev", # GRIB format support (ECMWF's native format)
"libudunits2-dev", # Unit conversions
)
.with_pip_packages(
"numpy==2.3.5",
"pandas==2.3.3",
"xarray==2025.11.0",
"torch==2.9.1",
"netCDF4==1.7.3",
"s3fs==2025.10.0",
"aiohttp==3.13.2",
"ecmwf-datastores-client==0.4.1",
"h5netcdf==1.7.3",
"cfgrib==0.9.15.1",
"pyarrow==22.0.0",
"scipy==1.15.1",
"flyteplugins-dask>=2.0.0b33",
"nvidia-ml-py3==7.352.0",
)
.with_env_vars({"PYTORCH_CUDA_ALLOC_CONF": "max_split_size_mb:512"})
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
Climate data comes in specialized formats such as NetCDF, HDF5, and GRIB. The container image includes libraries to work with all of them, along with PyTorch for GPU computation and the ECMWF client for accessing ERA5 data.
### Simulation parameters and data structures
```
@dataclass
class SimulationParams:
grid_resolution_km: float = 10.0
time_step_minutes: int = 10
simulation_hours: int = 240
physics_model: Literal["WRF", "MPAS", "CAM"] = "WRF"
boundary_layer_scheme: str = "YSU"
microphysics_scheme: str = "Thompson"
radiation_scheme: str = "RRTMG"
# Ensemble forecasting parameters
ensemble_size: int = 800
perturbation_magnitude: float = 0.5
# Convergence criteria for adaptive refinement
convergence_threshold: float = 0.1 # 10% of initial ensemble spread
max_iterations: int = 3
@dataclass
class ClimateMetrics:
timestamp: str
iteration: int
convergence_rate: float
energy_conservation_error: float
max_wind_speed_mps: float
min_pressure_mb: float
detected_phenomena: list[str]
compute_time_seconds: float
ensemble_spread: float
@dataclass
class SimulationSummary:
total_iterations: int
final_resolution_km: float
avg_convergence_rate: float
total_compute_time_seconds: float
hurricanes_detected: int
heatwaves_detected: int
converged: bool
region: str
output_files: list[File]
date_range: list[str, str]
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
`SimulationParams` defines the core behavior of the simulation, including grid resolution, physics schemes, and ensemble size. The default configuration runs 800 ensemble members, which is sufficient to produce statistically meaningful uncertainty estimates.
> [!NOTE]
> Decreasing the grid spacing via `grid_resolution_km` (for example, from 10 km to 5 km) increases grid resolution and significantly increases memory usage because it introduces more data points and intermediate state. Even with 141 GB of H200 GPU memory, high-resolution or adaptively refined simulations may exceed available VRAM, especially when running large ensembles.
>
> To mitigate this, consider reducing the ensemble size, limiting the refined region, running fewer physics variables, or scaling the simulation across more GPUs so memory is distributed more evenly.
`ClimateMetrics` collects diagnostics at each iteration, such as convergence rate, energy conservation, and detected phenomena. These metrics are streamed to the real-time dashboard so you can monitor how the simulation evolves as it runs.
### Task environments
Different stages need different resources. Flyte's `TaskEnvironment` declares exactly what each task requires:
```
gpu_env = flyte.TaskEnvironment(
name="climate_modeling_gpu",
resources=flyte.Resources(
cpu=5,
memory="130Gi",
gpu="H200:1",
),
image=climate_image,
cache="auto",
)
dask_env = flyte.TaskEnvironment(
name="climate_modeling_dask",
plugin_config=Dask(
scheduler=Scheduler(resources=flyte.Resources(cpu=2, memory="6Gi")),
workers=WorkerGroup(
number_of_workers=2,
resources=flyte.Resources(cpu=2, memory="12Gi"),
),
),
image=climate_image,
resources=flyte.Resources(cpu=2, memory="12Gi"), # Head node
cache="auto",
)
cpu_env = flyte.TaskEnvironment(
name="climate_modeling_cpu",
resources=flyte.Resources(cpu=8, memory="64Gi"),
image=climate_image,
cache="auto",
secrets=[
flyte.Secret(key="cds_api_key", as_env_var="ECMWF_DATASTORES_KEY"),
flyte.Secret(key="cds_api_url", as_env_var="ECMWF_DATASTORES_URL"),
],
depends_on=[gpu_env, dask_env],
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
Here’s what each environment is responsible for:
- **`gpu_env`**: Runs the atmospheric simulations on H200 GPUs. The 130 GB of GPU memory is used to hold the ensemble members in VRAM during execution.
- **`dask_env`**: Provides a distributed Dask cluster for preprocessing. A scheduler and multiple workers handle data fusion and transformation in parallel.
- **`cpu_env`**: Handles data ingestion and orchestration. This environment also includes the secrets required to access the ERA5 API.
The `depends_on` setting on `cpu_env` ensures that Flyte builds the GPU and Dask images first. Once those environments are ready, the orchestration task can launch the specialized simulation and preprocessing tasks.
### Data ingestion: multiple sources in parallel
Climate models need data from multiple sources. Each source has different formats, APIs, and failure modes. We handle them as separate Flyte tasks that run concurrently.
**Satellite imagery from NOAA GOES**
```
@cpu_env.task
async def ingest_satellite_data(region: str, date_range: list[str, str]) -> File:
"""Ingest GOES satellite imagery from NOAA's public S3 buckets."""
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
This task fetches cloud imagery and precipitable water products from NOAA's public S3 buckets. GOES-16 covers the Atlantic; GOES-17 covers the Pacific. The task selects the appropriate satellite based on region, fetches multiple days in parallel using `asyncio.gather`, and combines everything into a single xarray Dataset.
**ERA5 reanalysis from Copernicus**
```
@cpu_env.task
async def ingest_reanalysis_data(region: str, date_range: list[str, str]) -> File:
"""Fetch ERA5 reanalysis from Copernicus Climate Data Store."""
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
ERA5 provides 3D atmospheric fields such as temperature, wind, humidity at multiple pressure levels from surface to stratosphere. The ECMWF datastores client handles authentication via Flyte secrets. Each day fetches in parallel, then gets concatenated.
**Surface observations from weather stations:**
```
@cpu_env.task
async def ingest_station_data(
region: str, date_range: list[str, str], max_stations: int = 100
) -> File:
"""Fetch ground observations from NOAA's Integrated Surface Database."""
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
Ground truth comes from NOAA's Integrated Surface Database. The task filters stations by geographic bounds, fetches hourly observations, and returns a Parquet file for efficient downstream processing.
All three tasks return Flyte `File` objects that hold references to data in blob storage. No data moves until a downstream task actually needs it.
### Preprocessing with Dask
The three data sources need to be combined into a unified atmospheric state. This means:
- Interpolating to a common grid
- Handling missing values
- Merging variables from different sources
- Quality control
This is a perfect fit for Dask to handle lazy evaluation over chunked arrays:
```python
@dask_env.task
async def preprocess_atmospheric_data(
satellite_data: File,
reanalysis_data: File,
station_data: File,
target_resolution_km: float,
) -> File:
```
This task connects to the Dask cluster provisioned by Flyte, loads the datasets with appropriate chunking, merges satellite and reanalysis grids, fills in missing values, and persists the result. Flyte caches the output, so preprocessing only runs when the inputs change.
### GPU-accelerated atmospheric simulation
Now the core: running atmospheric physics on the GPU. Each ensemble member is an independent forecast with slightly perturbed initial conditions.
```
@gpu_env.task
async def run_atmospheric_simulation(
input_data: File,
params: SimulationParams,
partition_id: int = 0,
ensemble_start: int | None = None,
ensemble_end: int | None = None,
) -> tuple[File, ClimateMetrics]:
"""Run GPU-accelerated atmospheric simulation with ensemble forecasting."""
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
The task accepts a subset of ensemble members (`ensemble_start` to `ensemble_end`). This enables distributing 800 members across multiple GPUs.
The physics step is the computational kernel. It runs advection (wind transport), pressure gradients, Coriolis forces, turbulent diffusion, and moisture condensation:
```
@torch.compile(mode="reduce-overhead")
def physics_step(state_tensor, dt_val, dx_val):
"""Compiled atmospheric physics - 3-4x faster with torch.compile."""
# Advection: transport by wind
temp_grad_x = torch.roll(state_tensor[:, 0], -1, dims=2) - torch.roll(
state_tensor[:, 0], 1, dims=2
)
temp_grad_y = torch.roll(state_tensor[:, 0], -1, dims=3) - torch.roll(
state_tensor[:, 0], 1, dims=3
)
advection = -(
state_tensor[:, 3] * temp_grad_x + state_tensor[:, 4] * temp_grad_y
) / (2 * dx_val)
state_tensor[:, 0] = state_tensor[:, 0] + advection * dt_val
# Pressure gradient with Coriolis
pressure_grad_x = (
torch.roll(state_tensor[:, 1], -1, dims=2)
- torch.roll(state_tensor[:, 1], 1, dims=2)
) / (2 * dx_val)
pressure_grad_y = (
torch.roll(state_tensor[:, 1], -1, dims=3)
- torch.roll(state_tensor[:, 1], 1, dims=3)
) / (2 * dx_val)
coriolis_param = 1e-4 # ~45°N latitude
coriolis_u = coriolis_param * state_tensor[:, 4]
coriolis_v = -coriolis_param * state_tensor[:, 3]
state_tensor[:, 3] = (
state_tensor[:, 3] - pressure_grad_x * dt_val * 0.01 + coriolis_u * dt_val
)
state_tensor[:, 4] = (
state_tensor[:, 4] - pressure_grad_y * dt_val * 0.01 + coriolis_v * dt_val
)
# Turbulent diffusion
diffusion_coeff = 10.0
laplacian_temp = (
torch.roll(state_tensor[:, 0], 1, dims=2)
+ torch.roll(state_tensor[:, 0], -1, dims=2)
+ torch.roll(state_tensor[:, 0], 1, dims=3)
+ torch.roll(state_tensor[:, 0], -1, dims=3)
- 4 * state_tensor[:, 0]
) / (dx_val * dx_val)
state_tensor[:, 0] = (
state_tensor[:, 0] + diffusion_coeff * laplacian_temp * dt_val
)
# Moisture condensation
sat_vapor_pressure = 611.2 * torch.exp(
17.67 * state_tensor[:, 0] / (state_tensor[:, 0] + 243.5)
)
condensation = torch.clamp(
state_tensor[:, 2] - sat_vapor_pressure * 0.001, min=0
)
state_tensor[:, 2] = state_tensor[:, 2] - condensation * 0.1
state_tensor[:, 0] = state_tensor[:, 0] + condensation * 2.5e6 / 1005 * dt_val
return state_tensor
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
`@torch.compile(mode="reduce-overhead")` compiles this function into optimized CUDA kernels. Combined with mixed precision (`torch.cuda.amp.autocast`), this runs 3-4x faster than eager PyTorch.
Every 10 timesteps, the simulation checks for extreme events:
- **Hurricanes**: Wind speed > 33 m/s with low pressure
- **Heatwaves**: Temperature anomalies exceeding thresholds
Detected phenomena get logged to the metrics, which flow to the live dashboard.
### Distributing across multiple GPUs
800 ensemble members is a lot for one GPU, so we distribute them:
```
@cpu_env.task
async def run_distributed_simulation_ensemble(
preprocessed_data: File, params: SimulationParams, n_gpus: int
) -> tuple[list[File], list[ClimateMetrics]]:
total_members = params.ensemble_size
members_per_gpu = total_members // n_gpus
# Distribute ensemble members across GPUs
tasks = []
for gpu_id in range(n_gpus):
# Calculate ensemble range for this GPU
ensemble_start = gpu_id * members_per_gpu
# Last GPU gets any remainder members
if gpu_id == n_gpus - 1:
ensemble_end = total_members
else:
ensemble_end = ensemble_start + members_per_gpu
# Launch GPU task with ensemble subset
gpu_task = run_atmospheric_simulation(
preprocessed_data,
params,
gpu_id,
ensemble_start=ensemble_start,
ensemble_end=ensemble_end,
)
tasks.append(gpu_task)
# Execute all GPUs in parallel
results = await asyncio.gather(*tasks)
output_files = [r[0] for r in results]
metrics = [r[1] for r in results]
return output_files, metrics
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
The task splits the ensemble members evenly across the available GPUs, launches the simulation runs in parallel using `asyncio.gather`, and then aggregates the results. With five GPUs, each GPU runs 160 ensemble members. Flyte takes care of scheduling, so GPU tasks start automatically as soon as resources become available.
### The main workflow
Everything comes together in the orchestration task:
```
@cpu_env.task(report=True)
async def adaptive_climate_modeling_workflow(
region: str = "atlantic",
date_range: list[str, str] = ["2024-09-01", "2024-09-10"],
current_params: SimulationParams = SimulationParams(),
enable_multi_gpu: bool = True,
n_gpus: int = 5,
) -> SimulationSummary:
"""Orchestrates multi-source ingestion, GPU simulation, and adaptive refinement."""
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
`report=True` enables Flyte Reports for live monitoring.
```
# Parallel data ingestion from three sources
with flyte.group("data-ingestion"):
satellite_task = ingest_satellite_data(region, date_range)
reanalysis_task = ingest_reanalysis_data(region, date_range)
station_task = ingest_station_data(region, date_range)
satellite_data, reanalysis_data, station_data = await asyncio.gather(
satellite_task,
reanalysis_task,
station_task,
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
`flyte.group("data-ingestion")` visually groups the ingestion tasks in the Flyte UI. Inside the group, three tasks launch concurrently. `asyncio.gather` waits for all three to complete before preprocessing begins.
The workflow then enters an iterative loop:
1. Run GPU simulation (single or multi-GPU)
2. Check convergence by comparing forecasts across iterations
3. Detect extreme events
4. If a hurricane is detected and we haven't refined yet, double the grid resolution
5. Stream metrics to the live dashboard
6. Repeat until converged or max iterations reached
Adaptive mesh refinement is the key feature here. When the simulation detects a hurricane forming, it automatically increases resolution to capture the fine-scale dynamics. This is expensive, so we limit it to one refinement per run.
### Running the pipeline
```
if __name__ == "__main__":
flyte.init_from_config()
run_multi_gpu = flyte.run(adaptive_climate_modeling_workflow)
print(f"Run URL: {run_multi_gpu.url}")
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/climate_modeling/simulation.py*
Before running, set up ERA5 API credentials:
```bash
flyte create secret cds_api_key
flyte create secret cds_api_url https://cds.climate.copernicus.eu/api
```
Then launch:
```bash
flyte create config --endpoint --project --domain --builder remote
uv run simulation.py
```
The default configuration uses the Atlantic region for September 2024, which is hurricane season.
## Key concepts
### Ensemble forecasting
Weather prediction is inherently uncertain. Small errors in the initial conditions grow over time due to chaotic dynamics, which means a single forecast can only ever be one possible outcome.
Ensemble forecasting addresses this uncertainty by:
- Perturbing the initial conditions within known observational error bounds
- Running many independent forecasts
- Computing the ensemble mean as the most likely outcome and the ensemble spread as a measure of uncertainty
### Adaptive mesh refinement
When a hurricane begins to form, coarse spatial grids are not sufficient to resolve critical features like eyewall dynamics. Adaptive mesh refinement allows the simulation to focus compute where it matters most by:
- Increasing grid resolution, for example from 10 km to 5 km
- Reducing the timestep to maintain numerical stability
- Refining only the regions of interest instead of the entire domain
This approach is computationally expensive, but it is essential for producing accurate intensity forecasts.
### Real-time event detection
Rather than analyzing results after a simulation completes, this pipeline detects significant events as the simulation runs.
The system monitors for conditions such as:
- **Hurricanes**: Wind speeds exceeding 33 m/s (Category 1 threshold) combined with central pressure below 980 mb
- **Heatwaves**: Sustained temperature anomalies over a defined period
Detecting these events in real time enables adaptive responses, such as refining the simulation or triggering alerts, and supports earlier warnings for extreme weather.
## Where to go next
This example is intentionally scoped to keep the ideas clear, but there are several natural ways to extend it for more realistic workloads.
To model different ocean basins, change the `region` parameter to values like `"pacific"` or `"indian"`. The ingestion tasks automatically adjust to pull the appropriate satellite coverage for each region.
To run longer forecasts, increase `simulation_hours` in `SimulationParams`. The default of 240 hours, or 10 days, is typical for medium-range forecasting, but you can run longer simulations if you have the compute budget.
Finally, the physics step here is deliberately simplified. Production systems usually incorporate additional components such as radiation schemes, boundary layer parameterizations, and land surface models. These can be added incrementally as separate steps without changing the overall structure of the pipeline.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/geospatial/satellite_image_classification ===
# Satellite image classification

## Background
Remote sensing has transformed how we monitor our planet. From tracking deforestation to detecting urban sprawl, satellite imagery provides a bird's-eye view of land use change at global scale.
But training a model that can reliably classify that imagery — across 10 distinct land-use categories, at production quality — requires more than just a good model. It requires a pipeline that handles data, compute, caching, experiment tracking, and reporting as first-class concerns.
This tutorial walks through a complete satellite image classification pipeline built on Union.ai, using EfficientNet-B0, a two-phase training strategy, and Weights & Biases for experiment tracking.
> [!NOTE]
> Full code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/satellite_image_classification).
## Dataset
[EuroSAT](https://github.com/phelber/EuroSAT) is a benchmark dataset of 27,000 labeled satellite images drawn from the Sentinel-2 satellite. Each image is 64×64 pixels across 10 land-use classes: Annual Crop, Forest, Herbaceous Vegetation, Highway, Industrial, Pasture, Permanent Crop, Residential, River, and Sea/Lake.
It's a well-structured dataset - balanced, clearly labeled - which makes it ideal for demonstrating a production-grade training pipeline without the overhead of massive data infrastructure.
## Model
We use EfficientNet-B0 from `timm` (the PyTorch Image Models library), pretrained on ImageNet. EfficientNet was designed to scale depth, width, and resolution jointly using a compound coefficient, giving strong accuracy with a relatively small parameter count (~5.3M). The ImageNet pretraining means the backbone already understands edges, textures, and shapes - features that transfer well to satellite imagery.
## Two-phase training
Fine-tuning a pretrained model naively by using all weights immediately often leads to catastrophic forgetting: the model destroys its learned representations before the new task-specific head has had a chance to stabilize.
Instead, we use a two-phase approach:
**Phase 1: Feature Extraction (frozen backbone).** The EfficientNet backbone is frozen. Only the classification head is trained, at a relatively high learning rate (2e-3). This gives the head 7 epochs to learn to map ImageNet features to EuroSAT categories, without disturbing the pretrained weights.
**Phase 2: Fine-tuning (unfrozen backbone).** The backbone is unfrozen and added to the optimizer with a 10× lower learning rate than the head (`phase2_lr` × 0.1). A fresh cosine annealing schedule is initialized over the remaining steps, so the learning rate doesn't arrive near-zero from Phase 1's schedule before Phase 2 even begins. This lets the backbone adapt to satellite-specific features while preserving the general representations it learned on ImageNet.
The transition happens automatically inside a `PhaseChangeCallback`:
```
class PhaseChangeCallback(L.Callback):
def __init__(self, phase1_epochs: int, phase2_lr: float):
super().__init__()
self.phase1_epochs = phase1_epochs
self.phase2_lr = phase2_lr
self.phase_changed = False
def on_train_epoch_end(self, trainer, pl_module):
if not self.phase_changed and (trainer.current_epoch + 1) == self.phase1_epochs:
print("\n" + "=" * 80)
print("TRANSITIONING TO PHASE 2: UNFREEZING BACKBONE AND ADJUSTING LR")
print("=" * 80 + "\n")
pl_module.model.unfreeze_backbone()
for param_group in trainer.optimizers[0].param_groups:
param_group["lr"] = self.phase2_lr
# Add backbone params to optimizer with 10x lower LR.
# Backbone was excluded at init because it was frozen.
backbone_lr = self.phase2_lr * 0.1
backbone_decay, backbone_no_decay = [], []
for param in pl_module.model.backbone.parameters():
if param.ndim >= 2:
backbone_decay.append(param)
else:
backbone_no_decay.append(param)
optimizer = trainer.optimizers[0]
optimizer.add_param_group({"params": backbone_decay, "lr": backbone_lr, "weight_decay": pl_module.weight_decay})
optimizer.add_param_group({"params": backbone_no_decay, "lr": backbone_lr, "weight_decay": 0.0})
# Fresh cosine schedule over remaining Phase 2 steps to avoid
# the Phase 1 schedule arriving near-zero before Phase 2 begins.
steps_remaining = trainer.estimated_stepping_batches - trainer.global_step
new_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
trainer.optimizers[0],
T_max=max(1, steps_remaining),
eta_min=1e-6,
)
for lr_scheduler_config in trainer.lr_scheduler_configs:
lr_scheduler_config.scheduler = new_scheduler
print(f"Phase 2 started: lr={self.phase2_lr}")
print(f"Total parameters: {get_model_size(pl_module.model):,}")
print(f"Trainable parameters: {get_trainable_params(pl_module.model):,}")
self.phase_changed = True
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/satellite_image_classification/training.py*
This two-phase strategy consistently reaches >95% validation accuracy on EuroSAT within 17 total epochs.
## Pipeline
Training a model is only part of the story. The real challenge is building a system that is reproducible, cost-efficient, and easy to iterate on. That's where Union's `TaskEnvironment` model shines: each stage of the pipeline runs in the right compute environment, and results are cached so you never pay for work you've already done.
The pipeline has four components, each with its own environment defined in `config.py`.
### Task 1: Data download (`dataset_env`)
```
@dataset_env.task
async def load_dataset() -> Dir:
"""
Download raw EuroSAT JPEG files and cache as flyte.io.Dir.
Runs once — result is reused on subsequent pipeline runs (cache="auto").
"""
return await download_eurosat()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/satellite_image_classification/run.py*
This task downloads the raw EuroSAT JPEG files via torchvision and packages them as a `flyte.io.Dir`. It runs on a lightweight CPU container (2 cores, 2 GB RAM) - no GPU needed. With `cache="auto"`, the result is stored and reused on every subsequent run. You pay for the download exactly once.
No preprocessing happens here. Raw images are passed directly to training so that all transforms - resize, normalization, and augmentation - happen per-batch with the full training context, giving the model properly prepared 224×224 input from the original pixels.
### Task 2: GPU training (`training_env`)
```
@wandb_init
@training_env.task
async def train_model(dataset_dir: Dir, config: TrainingConfig) -> Dir:
"""
Download the raw dataset Dir, run two-phase training,
and return training metrics as a Dir for the report task.
"""
from pathlib import Path
local_dir = Path("/tmp/eurosat_local")
local_dir.mkdir(parents=True, exist_ok=True)
await dataset_dir.download(local_path=str(local_dir))
result = train_satellite_classifier(config=config, dataset_path=str(local_dir))
output_dir = Path("/tmp/training_results")
output_dir.mkdir(parents=True, exist_ok=True)
(output_dir / "metrics.json").write_text(json.dumps(result["metrics"]))
return await Dir.from_local(str(output_dir))
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/satellite_image_classification/run.py*
This task runs on a T4 GPU with 32 GB RAM. It receives the dataset `Dir` from Task 1, downloads it locally, then runs the two-phase training loop using PyTorch Lightning.
Two things worth noting:
- With `cache="auto"`, training results are cached based on the input data and config. If you rerun the pipeline with the same dataset and hyperparameters, Union skips training entirely and returns the cached metrics. This makes hyperparameter search much cheaper: only configurations you haven't tried before actually execute.
- `@wandb_init` — the `flyteplugins-wandb` integration initializes a W&B run automatically and makes it available via `get_wandb_run()`. This means every training run automatically logs metrics, learning rate curves, and t-SNE visualizations of the learned feature space to your W&B project.
```
wandb_logger = WandbLogger(experiment=get_wandb_run(), log_model=False)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/satellite_image_classification/training.py*
### Task 3: Report generation (`report_env`)
This task reads the `metrics.json` produced by training and renders interactive Plotly charts - validation accuracy and train/val loss curves - directly in the Union UI. The `report=True` flag tells Union to render the task output as a rich report panel. A dashed vertical line marks the Phase 1 → Phase 2 transition, making it easy to see how much the backbone fine-tuning contributes.
```
@report_env.task(report=True)
async def create_report(results_dir: Dir) -> None:
"""
Download training metrics and render loss/accuracy curves
in the Union UI report panel.
"""
import plotly.graph_objects as go
from pathlib import Path
local_dir = Path("/tmp/training_report")
local_dir.mkdir(parents=True, exist_ok=True)
await results_dir.download(local_path=str(local_dir))
matches = list(local_dir.glob("**/metrics.json"))
if not matches:
raise RuntimeError(f"metrics.json not found under {local_dir}")
local_path = matches[0].parent
history = json.loads((local_path / "metrics.json").read_text())
epochs = [e["epoch"] for e in history]
val_acc = [e["val_acc"] for e in history]
val_loss = [e["val_loss"] for e in history]
train_loss = [e["train_loss"] for e in history]
# phase_boundary: first epoch where phase 2 begins (frozen → fine-tune transition)
phase_boundary = next((e["epoch"] for e in history if e["phase"] == 2), None)
def add_phase_line(fig):
if phase_boundary is not None:
fig.add_vline(
x=phase_boundary,
line_dash="dash",
line_color="gray",
annotation_text="Phase 2 start",
)
acc_fig = go.Figure()
acc_fig.add_trace(go.Scatter(x=epochs, y=val_acc, mode="lines+markers", name="Val Accuracy"))
acc_fig.update_layout(title="Validation Accuracy", xaxis_title="Epoch", yaxis_title="Accuracy")
add_phase_line(acc_fig)
loss_fig = go.Figure()
loss_fig.add_trace(go.Scatter(x=epochs, y=train_loss, mode="lines+markers", name="Train Loss"))
loss_fig.add_trace(go.Scatter(x=epochs, y=val_loss, mode="lines+markers", name="Val Loss"))
loss_fig.update_layout(title="Loss", xaxis_title="Epoch", yaxis_title="Loss")
add_phase_line(loss_fig)
combined_html = (
acc_fig.to_html(include_plotlyjs=True, full_html=False)
+ loss_fig.to_html(include_plotlyjs=False, full_html=False)
)
flyte.report.log(combined_html, do_flush=True)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/satellite_image_classification/run.py*
### Task 4: Orchestration (`pipeline_env`)
The pipeline task is a lightweight orchestrator. It has no heavy dependencies of its own, just enough to call the three tasks above in sequence. The `async`/`await` pattern means each task handoff is non-blocking: Union manages scheduling, retries, and data movement between tasks transparently.
```
@pipeline_env.task
async def satellite_classification_pipeline(config: TrainingConfig) -> None:
"""Orchestrate dataset loading, GPU training, and report generation."""
dataset_dir = await load_dataset()
results_dir = await train_model(
dataset_dir=dataset_dir,
config=config,
)
await create_report(results_dir=results_dir)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/satellite_image_classification/run.py*
## Running the pipeline
Submit the pipeline with a single command from the project directory:
```bash
uv run run.py
```
This calls:
```
run = flyte.with_runcontext(
custom_context=wandb_config(
project=training_config.wandb_project,
entity=training_config.wandb_entity,
),
).run(satellite_classification_pipeline, config=training_config)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/satellite_image_classification/run.py*
The W&B project and entity are wired in at submission time. Union handles spinning up the right containers, routing data between tasks, and surfacing results in the UI.
## What you get
After the pipeline completes:
- Union UI: a report panel with interactive accuracy and loss curves, phase transition marker, and full task logs for each stage.
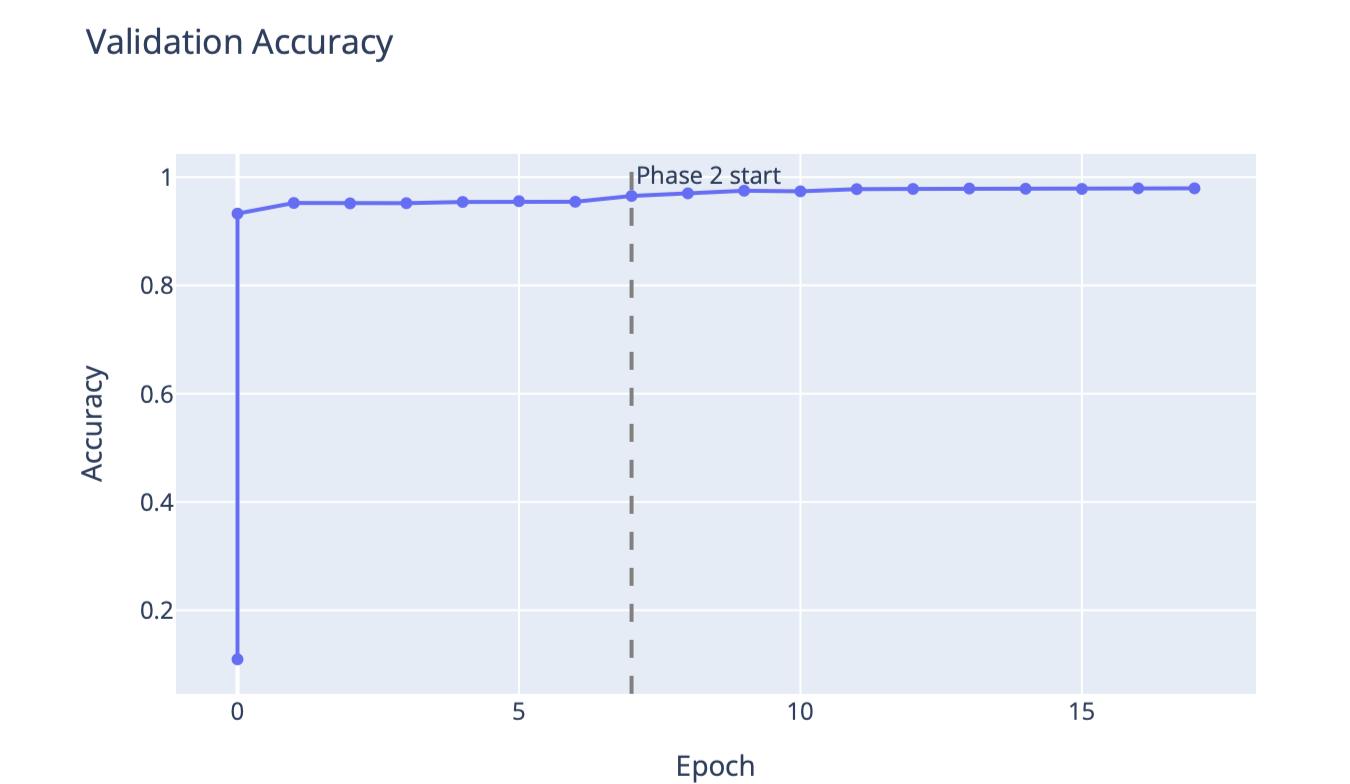
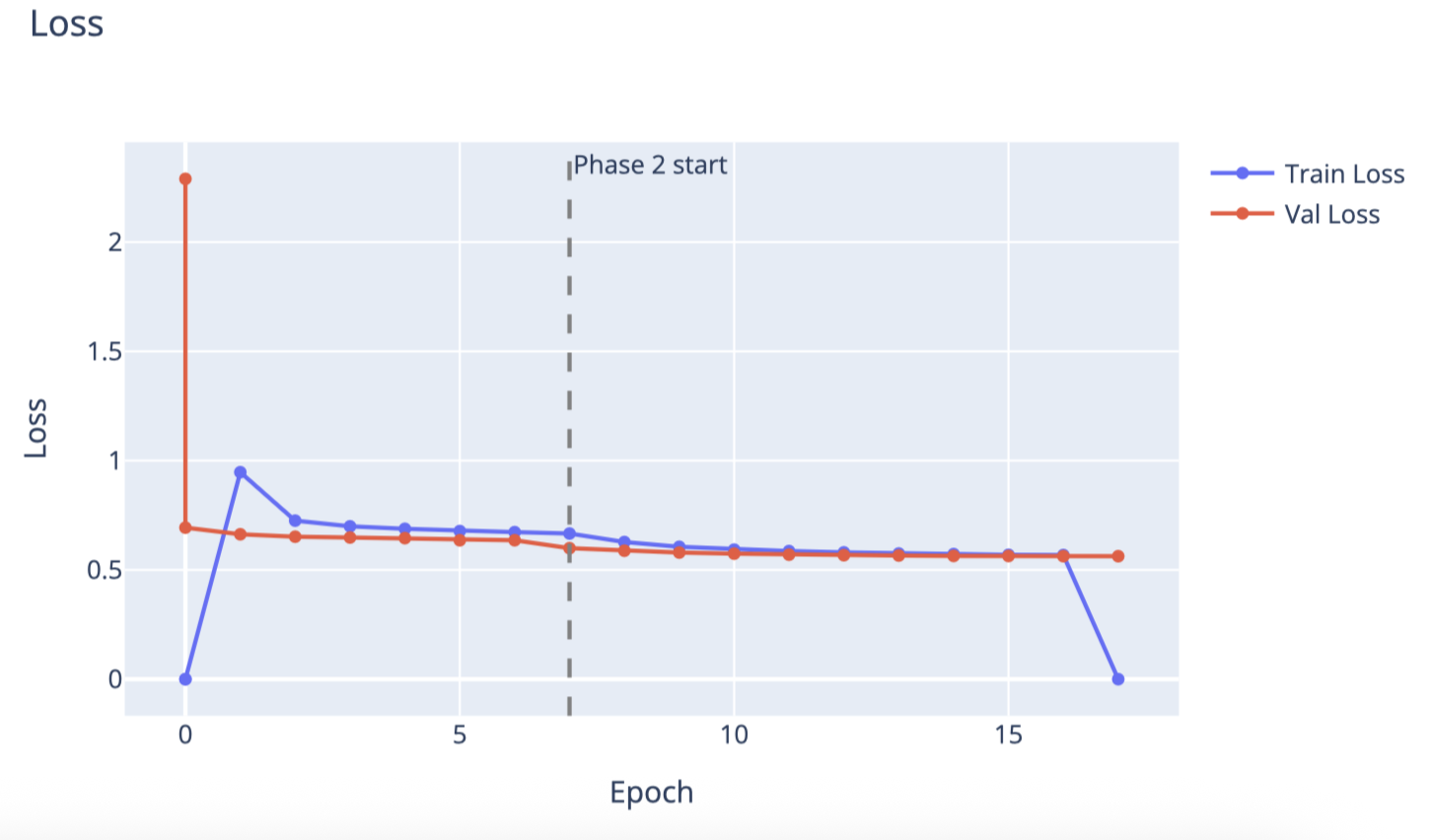
- Weights & Biases: a complete experiment run with validation metrics like loss and accuracy, train loss, and t-SNE visualizations of the model's learned embeddings at configurable epoch intervals. Every few epochs, a t-SNE plot of the validation set embeddings is logged, showing how the model's feature representations evolve over training. Classes that start as an overlapping cloud gradually pull apart into tight, well-separated clusters as the backbone learns satellite-specific features.
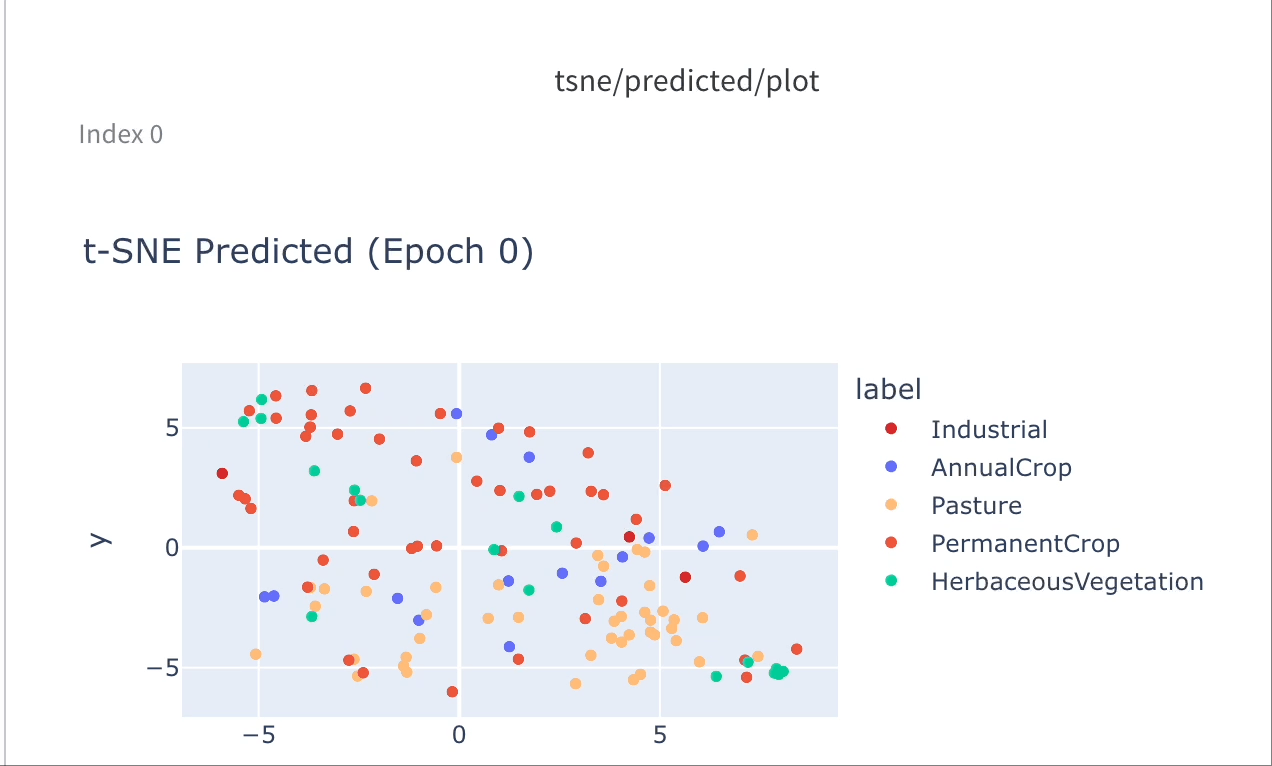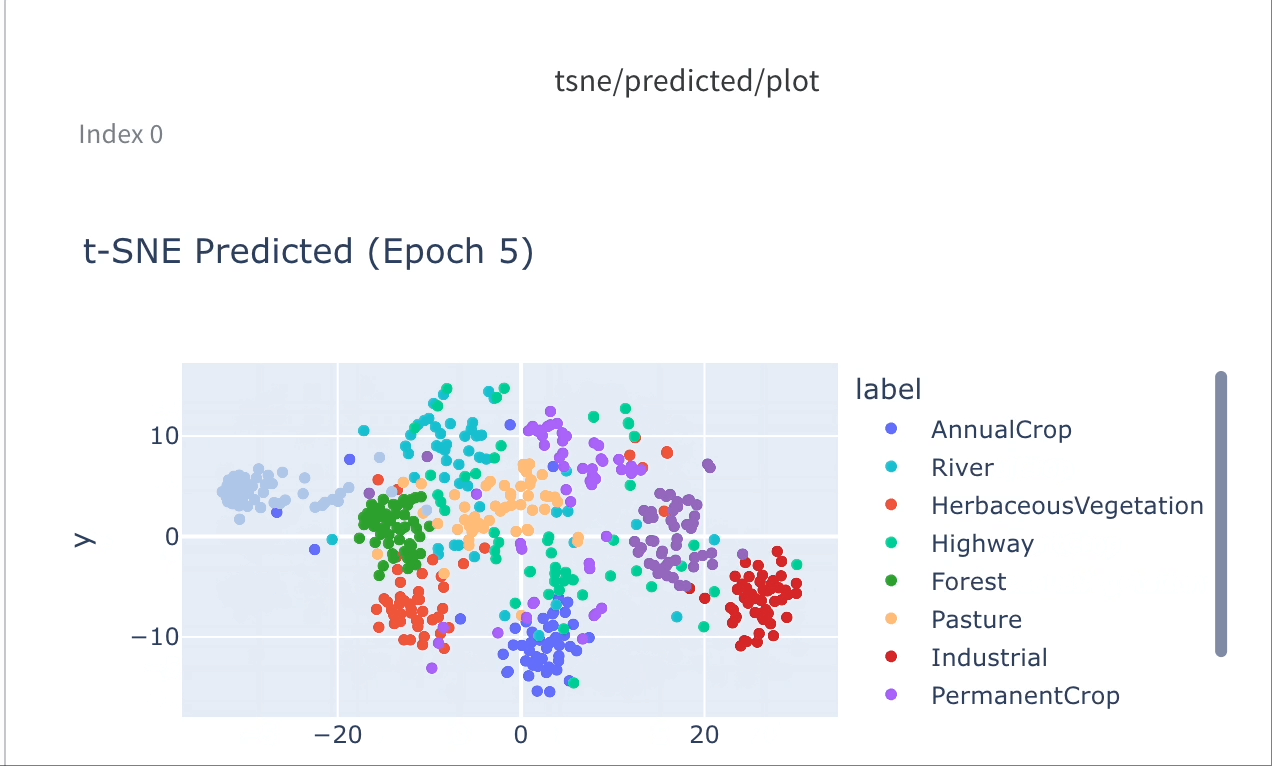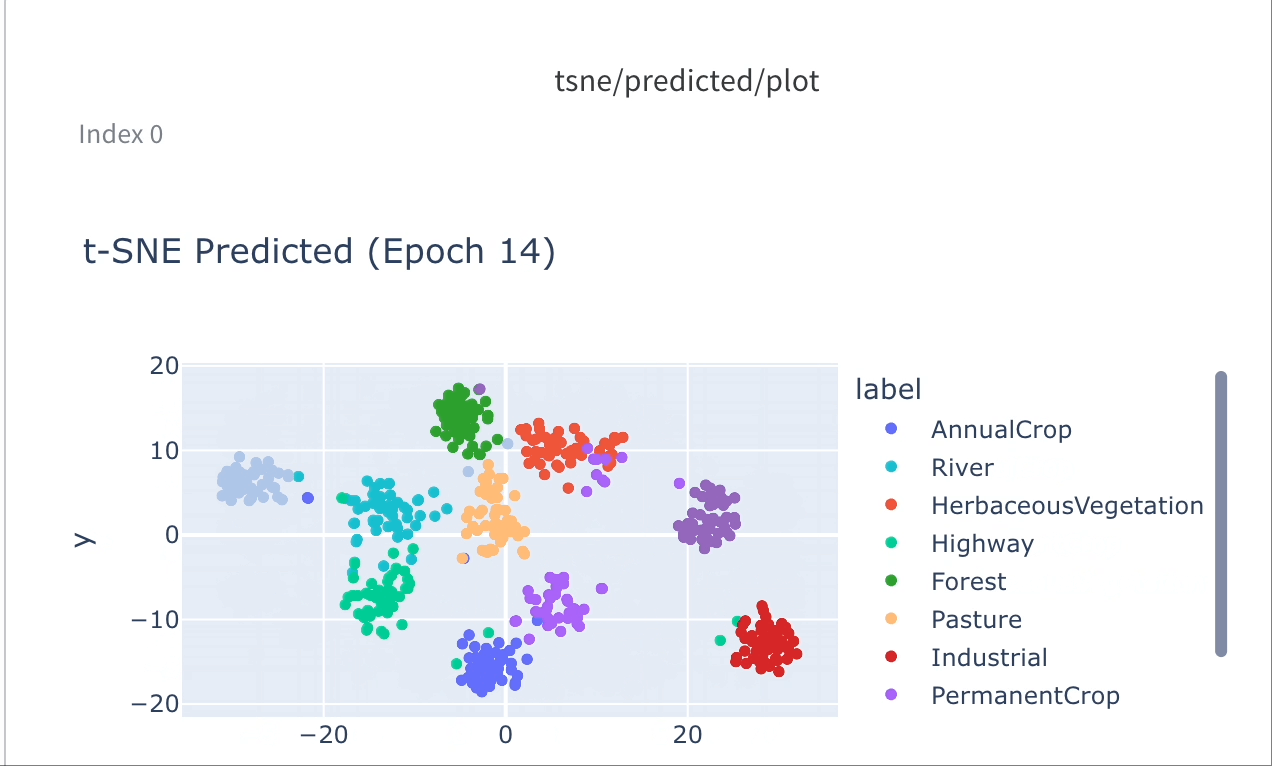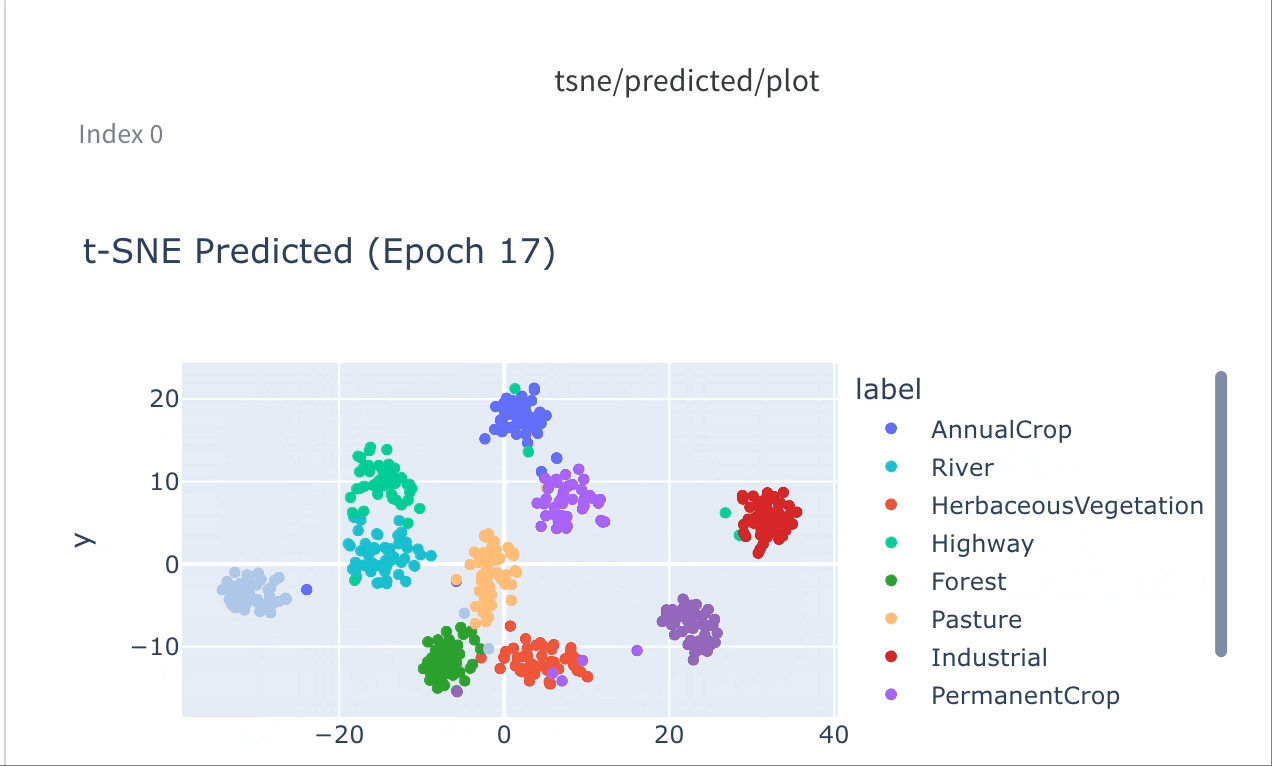
- Model checkpoints: Lightning's `ModelCheckpoint` saves the top 3 best-performing checkpoints by validation accuracy, named `best-{epoch}-{val_acc}.ckpt`. These are standard PyTorch Lightning checkpoints that can be loaded directly for inference.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/financial-services ===
# Financial services & fintech
Tutorials for financial research, trading, and other fintech workloads.
### **Financial services & fintech > Financial research agent**
Prep equity briefings for the earnings cycle with grounded You.com Research synthesis and fresh news from the Search API.
### **Financial services & fintech > Fraud detection with Feast**
Train an XGBoost fraud classifier and materialize transaction features in Feast for online scoring.
### **Financial services & fintech > Multi-agent trading simulation**
A multi-agent trading simulation, modeling how agents within a firm might interact, strategize, and make trades collaboratively.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/financial-services/trading-agents ===
# Multi-agent trading simulation
> [!NOTE]
> Code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/trading_agents); based on work by [TauricResearch](https://github.com/TauricResearch/TradingAgents).
This example walks you through building a multi-agent trading simulation, modeling how agents within a firm might interact, strategize, and make trades collaboratively.
_Trading agents execution visualization_
## TL;DR
- You'll build a trading firm made up of agents that analyze, argue, and act, modeled with Python functions.
- You'll use the Flyte SDK to orchestrate this world — giving you visibility, retries, caching, and durability.
- You'll learn how to plug in tools, structure conversations, and track decisions across agents.
- You'll see how agents debate, use context, generate reports, and retain memory via vector DBs.
## What is an agent, anyway?
Agentic workflows are a rising pattern for complex problem-solving with LLMs. Think of agents as:
- An LLM (like GPT-4 or Mistral)
- A loop that keeps them thinking until a goal is met
- A set of optional tools they can call (APIs, search, calculators, etc.)
- Enough tokens to reason about the problem at hand
That's it.
You define tools, bind them to an agent, and let it run, reasoning step-by-step, optionally using those tools, until it finishes.
## What's different here?
We're not building yet another agent framework. You're free to use LangChain, custom code, or whatever setup you like.
What we're giving you is the missing piece: a way to run these workflows **reliably, observably, and at scale, with zero rewrites.**
With Flyte, you get:
- Prompt + tool traceability and full state retention
- Built-in retries, caching, and failure recovery
- A native way to plug in your agents; no magic syntax required
## How it works: step-by-step walkthrough
This simulation is powered by a Flyte task that orchestrates multiple intelligent agents working together to analyze a company's stock and make informed trading decisions.
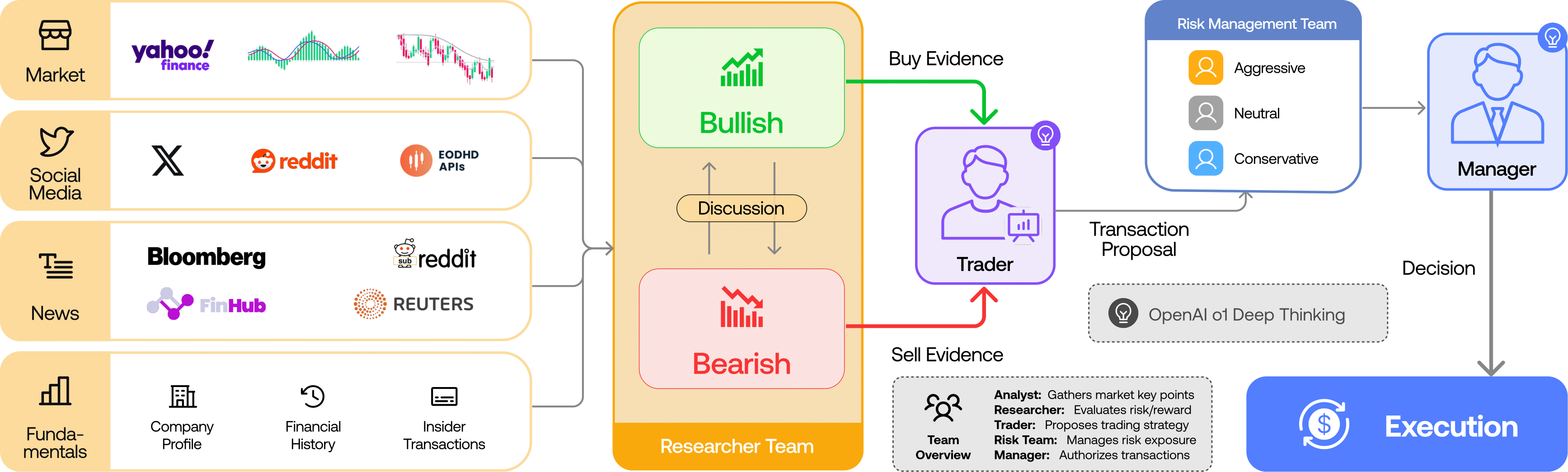
_Trading agents schema_
### Entry point
Everything begins with a top-level Flyte task called `main`, which serves as the entry point to the workflow.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "akshare==1.16.98",
# "backtrader==1.9.78.123",
# "boto3==1.39.9",
# "chainlit==2.5.5",
# "eodhd==1.0.32",
# "feedparser==6.0.11",
# "finnhub-python==2.4.23",
# "langchain-experimental==0.3.4",
# "langchain-openai==0.3.23",
# "pandas==2.3.0",
# "parsel==1.10.0",
# "praw==7.8.1",
# "pytz==2025.2",
# "questionary==2.1.0",
# "redis==6.2.0",
# "requests==2.32.4",
# "stockstats==0.6.5",
# "tqdm==4.67.1",
# "tushare==1.4.21",
# "typing-extensions==4.14.0",
# "yfinance==0.2.63",
# ]
# main = "main"
# params = ""
# ///
import asyncio
from copy import deepcopy
import agents
import agents.analysts
from agents.managers import create_research_manager, create_risk_manager
from agents.researchers import create_bear_researcher, create_bull_researcher
from agents.risk_debators import (
create_neutral_debator,
create_risky_debator,
create_safe_debator,
)
from agents.trader import create_trader
from agents.utils.utils import AgentState
from flyte_env import DEEP_THINKING_LLM, QUICK_THINKING_LLM, env, flyte
from langchain_openai import ChatOpenAI
from reflection import (
reflect_bear_researcher,
reflect_bull_researcher,
reflect_research_manager,
reflect_risk_manager,
reflect_trader,
)
@env.task
async def process_signal(full_signal: str, QUICK_THINKING_LLM: str) -> str:
"""Process a full trading signal to extract the core decision."""
messages = [
{
"role": "system",
"content": """You are an efficient assistant designed to analyze paragraphs or
financial reports provided by a group of analysts.
Your task is to extract the investment decision: SELL, BUY, or HOLD.
Provide only the extracted decision (SELL, BUY, or HOLD) as your output,
without adding any additional text or information.""",
},
{"role": "human", "content": full_signal},
]
return ChatOpenAI(model=QUICK_THINKING_LLM).invoke(messages).content
async def run_analyst(analyst_name, state, online_tools):
# Create a copy of the state for isolation
run_fn = getattr(agents.analysts, f"create_{analyst_name}_analyst")
# Run the analyst's chain
result_state = await run_fn(QUICK_THINKING_LLM, state, online_tools)
# Determine the report key
report_key = (
"sentiment_report"
if analyst_name == "social_media"
else f"{analyst_name}_report"
)
report_value = getattr(result_state, report_key)
return result_state.messages[1:], report_key, report_value
# {{docs-fragment main}}
@env.task
async def main(
selected_analysts: list[str] = [
"market",
"fundamentals",
"news",
"social_media",
],
max_debate_rounds: int = 1,
max_risk_discuss_rounds: int = 1,
online_tools: bool = True,
company_name: str = "NVDA",
trade_date: str = "2024-05-12",
) -> tuple[str, AgentState]:
if not selected_analysts:
raise ValueError(
"No analysts selected. Please select at least one analyst from market, fundamentals, news, or social_media."
)
state = AgentState(
messages=[{"role": "human", "content": company_name}],
company_of_interest=company_name,
trade_date=str(trade_date),
)
# Run all analysts concurrently
results = await asyncio.gather(
*[
run_analyst(analyst, deepcopy(state), online_tools)
for analyst in selected_analysts
]
)
# Flatten and append all resulting messages into the shared state
for messages, report_attr, report in results:
state.messages.extend(messages)
setattr(state, report_attr, report)
# Bull/Bear debate loop
state = await create_bull_researcher(QUICK_THINKING_LLM, state) # Start with bull
while state.investment_debate_state.count < 2 * max_debate_rounds:
current = state.investment_debate_state.current_response
if current.startswith("Bull"):
state = await create_bear_researcher(QUICK_THINKING_LLM, state)
else:
state = await create_bull_researcher(QUICK_THINKING_LLM, state)
state = await create_research_manager(DEEP_THINKING_LLM, state)
state = await create_trader(QUICK_THINKING_LLM, state)
# Risk debate loop
state = await create_risky_debator(QUICK_THINKING_LLM, state) # Start with risky
while state.risk_debate_state.count < 3 * max_risk_discuss_rounds:
speaker = state.risk_debate_state.latest_speaker
if speaker == "Risky":
state = await create_safe_debator(QUICK_THINKING_LLM, state)
elif speaker == "Safe":
state = await create_neutral_debator(QUICK_THINKING_LLM, state)
else:
state = await create_risky_debator(QUICK_THINKING_LLM, state)
state = await create_risk_manager(DEEP_THINKING_LLM, state)
decision = await process_signal(state.final_trade_decision, QUICK_THINKING_LLM)
return decision, state
# {{/docs-fragment main}}
# {{docs-fragment reflect_on_decisions}}
@env.task
async def reflect_and_store(state: AgentState, returns: str) -> str:
await asyncio.gather(
reflect_bear_researcher(state, returns),
reflect_bull_researcher(state, returns),
reflect_trader(state, returns),
reflect_risk_manager(state, returns),
reflect_research_manager(state, returns),
)
return "Reflection completed."
# Run the reflection task after the main function
@env.task(cache="disable")
async def reflect_on_decisions(
returns: str,
selected_analysts: list[str] = [
"market",
"fundamentals",
"news",
"social_media",
],
max_debate_rounds: int = 1,
max_risk_discuss_rounds: int = 1,
online_tools: bool = True,
company_name: str = "NVDA",
trade_date: str = "2024-05-12",
) -> str:
_, state = await main(
selected_analysts,
max_debate_rounds,
max_risk_discuss_rounds,
online_tools,
company_name,
trade_date,
)
return await reflect_and_store(state, returns)
# {{/docs-fragment reflect_on_decisions}}
# {{docs-fragment execute_main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(main)
print(run.url)
run.wait()
# run = flyte.run(reflect_on_decisions, "+3.2% gain over 5 days")
# print(run.url)
# {{/docs-fragment execute_main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/trading_agents/main.py*
This task accepts several inputs:
- the list of analysts to run,
- the number of debate and risk discussion rounds,
- a flag to enable online tools,
- the company you're evaluating,
- and the target trading date.
The most interesting parameter here is the list of analysts to run. It determines which analyst agents will be invoked and shapes the overall structure of the simulation. Based on this input, the task dynamically launches agent tasks, running them in parallel.
The `main` task is written as a regular asynchronous Python function wrapped with Flyte's task decorator. No domain-specific language or orchestration glue is needed — just idiomatic Python, optionally using async for better performance. The task environment is configured once and shared across all tasks for consistency.
```
# {{docs-fragment env}}
import flyte
QUICK_THINKING_LLM = "gpt-4o-mini"
DEEP_THINKING_LLM = "o4-mini"
env = flyte.TaskEnvironment(
name="trading-agents",
secrets=[
flyte.Secret(key="finnhub_api_key", as_env_var="FINNHUB_API_KEY"),
flyte.Secret(key="openai_api_key", as_env_var="OPENAI_API_KEY"),
],
image=flyte.Image.from_uv_script("main.py", name="trading-agents", pre=True),
resources=flyte.Resources(cpu="1"),
cache="auto",
)
# {{/docs-fragment env}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/trading_agents/flyte_env.py*
### Analyst agents
Each analyst agent comes equipped with a set of tools and a carefully designed prompt tailored to its specific domain. These tools are modular Flyte tasks — for example, downloading financial reports or computing technical indicators — and benefit from Flyte's built-in caching to avoid redundant computation.
```
from datetime import datetime
import pandas as pd
import tools.interface as interface
import yfinance as yf
from flyte_env import env
from flyte.io import File
@env.task
async def get_reddit_news(
curr_date: str, # Date you want to get news for in yyyy-mm-dd format
) -> str:
"""
Retrieve global news from Reddit within a specified time frame.
Args:
curr_date (str): Date you want to get news for in yyyy-mm-dd format
Returns:
str: A formatted dataframe containing the latest global news
from Reddit in the specified time frame.
"""
global_news_result = interface.get_reddit_global_news(curr_date, 7, 5)
return global_news_result
@env.task
async def get_finnhub_news(
ticker: str, # Search query of a company, e.g. 'AAPL, TSM, etc.
start_date: str, # Start date in yyyy-mm-dd format
end_date: str, # End date in yyyy-mm-dd format
) -> str:
"""
Retrieve the latest news about a given stock from Finnhub within a date range
Args:
ticker (str): Ticker of a company. e.g. AAPL, TSM
start_date (str): Start date in yyyy-mm-dd format
end_date (str): End date in yyyy-mm-dd format
Returns:
str: A formatted dataframe containing news about the company
within the date range from start_date to end_date
"""
end_date_str = end_date
end_date = datetime.strptime(end_date, "%Y-%m-%d")
start_date = datetime.strptime(start_date, "%Y-%m-%d")
look_back_days = (end_date - start_date).days
finnhub_news_result = interface.get_finnhub_news(
ticker, end_date_str, look_back_days
)
return finnhub_news_result
@env.task
async def get_reddit_stock_info(
ticker: str, # Ticker of a company. e.g. AAPL, TSM
curr_date: str, # Current date you want to get news for
) -> str:
"""
Retrieve the latest news about a given stock from Reddit, given the current date.
Args:
ticker (str): Ticker of a company. e.g. AAPL, TSM
curr_date (str): current date in yyyy-mm-dd format to get news for
Returns:
str: A formatted dataframe containing the latest news about the company on the given date
"""
stock_news_results = interface.get_reddit_company_news(ticker, curr_date, 7, 5)
return stock_news_results
@env.task
async def get_YFin_data(
symbol: str, # ticker symbol of the company
start_date: str, # Start date in yyyy-mm-dd format
end_date: str, # End date in yyyy-mm-dd format
) -> str:
"""
Retrieve the stock price data for a given ticker symbol from Yahoo Finance.
Args:
symbol (str): Ticker symbol of the company, e.g. AAPL, TSM
start_date (str): Start date in yyyy-mm-dd format
end_date (str): End date in yyyy-mm-dd format
Returns:
str: A formatted dataframe containing the stock price data
for the specified ticker symbol in the specified date range.
"""
result_data = interface.get_YFin_data(symbol, start_date, end_date)
return result_data
@env.task
async def get_YFin_data_online(
symbol: str, # ticker symbol of the company
start_date: str, # Start date in yyyy-mm-dd format
end_date: str, # End date in yyyy-mm-dd format
) -> str:
"""
Retrieve the stock price data for a given ticker symbol from Yahoo Finance.
Args:
symbol (str): Ticker symbol of the company, e.g. AAPL, TSM
start_date (str): Start date in yyyy-mm-dd format
end_date (str): End date in yyyy-mm-dd format
Returns:
str: A formatted dataframe containing the stock price data
for the specified ticker symbol in the specified date range.
"""
result_data = interface.get_YFin_data_online(symbol, start_date, end_date)
return result_data
@env.task
async def cache_market_data(symbol: str, start_date: str, end_date: str) -> File:
data_file = f"{symbol}-YFin-data-{start_date}-{end_date}.csv"
data = yf.download(
symbol,
start=start_date,
end=end_date,
multi_level_index=False,
progress=False,
auto_adjust=True,
)
data = data.reset_index()
data.to_csv(data_file, index=False)
return await File.from_local(data_file)
@env.task
async def get_stockstats_indicators_report(
symbol: str, # ticker symbol of the company
indicator: str, # technical indicator to get the analysis and report of
curr_date: str, # The current trading date you are trading on, YYYY-mm-dd
look_back_days: int = 30, # how many days to look back
) -> str:
"""
Retrieve stock stats indicators for a given ticker symbol and indicator.
Args:
symbol (str): Ticker symbol of the company, e.g. AAPL, TSM
indicator (str): Technical indicator to get the analysis and report of
curr_date (str): The current trading date you are trading on, YYYY-mm-dd
look_back_days (int): How many days to look back, default is 30
Returns:
str: A formatted dataframe containing the stock stats indicators
for the specified ticker symbol and indicator.
"""
today_date = pd.Timestamp.today()
end_date = today_date
start_date = today_date - pd.DateOffset(years=15)
start_date = start_date.strftime("%Y-%m-%d")
end_date = end_date.strftime("%Y-%m-%d")
data_file = await cache_market_data(symbol, start_date, end_date)
local_data_file = await data_file.download()
result_stockstats = interface.get_stock_stats_indicators_window(
symbol, indicator, curr_date, look_back_days, False, local_data_file
)
return result_stockstats
# {{docs-fragment get_stockstats_indicators_report_online}}
@env.task
async def get_stockstats_indicators_report_online(
symbol: str, # ticker symbol of the company
indicator: str, # technical indicator to get the analysis and report of
curr_date: str, # The current trading date you are trading on, YYYY-mm-dd"
look_back_days: int = 30, # "how many days to look back"
) -> str:
"""
Retrieve stock stats indicators for a given ticker symbol and indicator.
Args:
symbol (str): Ticker symbol of the company, e.g. AAPL, TSM
indicator (str): Technical indicator to get the analysis and report of
curr_date (str): The current trading date you are trading on, YYYY-mm-dd
look_back_days (int): How many days to look back, default is 30
Returns:
str: A formatted dataframe containing the stock stats indicators
for the specified ticker symbol and indicator.
"""
today_date = pd.Timestamp.today()
end_date = today_date
start_date = today_date - pd.DateOffset(years=15)
start_date = start_date.strftime("%Y-%m-%d")
end_date = end_date.strftime("%Y-%m-%d")
data_file = await cache_market_data(symbol, start_date, end_date)
local_data_file = await data_file.download()
result_stockstats = interface.get_stock_stats_indicators_window(
symbol, indicator, curr_date, look_back_days, True, local_data_file
)
return result_stockstats
# {{/docs-fragment get_stockstats_indicators_report_online}}
@env.task
async def get_finnhub_company_insider_sentiment(
ticker: str, # ticker symbol for the company
curr_date: str, # current date of you are trading at, yyyy-mm-dd
) -> str:
"""
Retrieve insider sentiment information about a company (retrieved
from public SEC information) for the past 30 days
Args:
ticker (str): ticker symbol of the company
curr_date (str): current date you are trading at, yyyy-mm-dd
Returns:
str: a report of the sentiment in the past 30 days starting at curr_date
"""
data_sentiment = interface.get_finnhub_company_insider_sentiment(
ticker, curr_date, 30
)
return data_sentiment
@env.task
async def get_finnhub_company_insider_transactions(
ticker: str, # ticker symbol
curr_date: str, # current date you are trading at, yyyy-mm-dd
) -> str:
"""
Retrieve insider transaction information about a company
(retrieved from public SEC information) for the past 30 days
Args:
ticker (str): ticker symbol of the company
curr_date (str): current date you are trading at, yyyy-mm-dd
Returns:
str: a report of the company's insider transactions/trading information in the past 30 days
"""
data_trans = interface.get_finnhub_company_insider_transactions(
ticker, curr_date, 30
)
return data_trans
@env.task
async def get_simfin_balance_sheet(
ticker: str, # ticker symbol
freq: str, # reporting frequency of the company's financial history: annual/quarterly
curr_date: str, # current date you are trading at, yyyy-mm-dd
):
"""
Retrieve the most recent balance sheet of a company
Args:
ticker (str): ticker symbol of the company
freq (str): reporting frequency of the company's financial history: annual / quarterly
curr_date (str): current date you are trading at, yyyy-mm-dd
Returns:
str: a report of the company's most recent balance sheet
"""
data_balance_sheet = interface.get_simfin_balance_sheet(ticker, freq, curr_date)
return data_balance_sheet
@env.task
async def get_simfin_cashflow(
ticker: str, # ticker symbol
freq: str, # reporting frequency of the company's financial history: annual/quarterly
curr_date: str, # current date you are trading at, yyyy-mm-dd
) -> str:
"""
Retrieve the most recent cash flow statement of a company
Args:
ticker (str): ticker symbol of the company
freq (str): reporting frequency of the company's financial history: annual / quarterly
curr_date (str): current date you are trading at, yyyy-mm-dd
Returns:
str: a report of the company's most recent cash flow statement
"""
data_cashflow = interface.get_simfin_cashflow(ticker, freq, curr_date)
return data_cashflow
@env.task
async def get_simfin_income_stmt(
ticker: str, # ticker symbol
freq: str, # reporting frequency of the company's financial history: annual/quarterly
curr_date: str, # current date you are trading at, yyyy-mm-dd
) -> str:
"""
Retrieve the most recent income statement of a company
Args:
ticker (str): ticker symbol of the company
freq (str): reporting frequency of the company's financial history: annual / quarterly
curr_date (str): current date you are trading at, yyyy-mm-dd
Returns:
str: a report of the company's most recent income statement
"""
data_income_stmt = interface.get_simfin_income_statements(ticker, freq, curr_date)
return data_income_stmt
@env.task
async def get_google_news(
query: str, # Query to search with
curr_date: str, # Curr date in yyyy-mm-dd format
) -> str:
"""
Retrieve the latest news from Google News based on a query and date range.
Args:
query (str): Query to search with
curr_date (str): Current date in yyyy-mm-dd format
look_back_days (int): How many days to look back
Returns:
str: A formatted string containing the latest news from Google News
based on the query and date range.
"""
google_news_results = interface.get_google_news(query, curr_date, 7)
return google_news_results
@env.task
async def get_stock_news_openai(
ticker: str, # the company's ticker
curr_date: str, # Current date in yyyy-mm-dd format
) -> str:
"""
Retrieve the latest news about a given stock by using OpenAI's news API.
Args:
ticker (str): Ticker of a company. e.g. AAPL, TSM
curr_date (str): Current date in yyyy-mm-dd format
Returns:
str: A formatted string containing the latest news about the company on the given date.
"""
openai_news_results = interface.get_stock_news_openai(ticker, curr_date)
return openai_news_results
@env.task
async def get_global_news_openai(
curr_date: str, # Current date in yyyy-mm-dd format
) -> str:
"""
Retrieve the latest macroeconomics news on a given date using OpenAI's macroeconomics news API.
Args:
curr_date (str): Current date in yyyy-mm-dd format
Returns:
str: A formatted string containing the latest macroeconomic news on the given date.
"""
openai_news_results = interface.get_global_news_openai(curr_date)
return openai_news_results
@env.task
async def get_fundamentals_openai(
ticker: str, # the company's ticker
curr_date: str, # Current date in yyyy-mm-dd format
) -> str:
"""
Retrieve the latest fundamental information about a given stock
on a given date by using OpenAI's news API.
Args:
ticker (str): Ticker of a company. e.g. AAPL, TSM
curr_date (str): Current date in yyyy-mm-dd format
Returns:
str: A formatted string containing the latest fundamental information
about the company on the given date.
"""
openai_fundamentals_results = interface.get_fundamentals_openai(ticker, curr_date)
return openai_fundamentals_results
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/trading_agents/tools/toolkit.py*
When initialized, an analyst enters a structured reasoning loop (via LangChain), where it can call tools, observe outputs, and refine its internal state before generating a final report. These reports are later consumed by downstream agents.
Here's an example of a news analyst that interprets global events and macroeconomic signals. We specify the tools accessible to the analyst, and the LLM selects which ones to use based on context.
```
import asyncio
from agents.utils.utils import AgentState
from flyte_env import env
from langchain_core.messages import ToolMessage, convert_to_openai_messages
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from tools import toolkit
import flyte
MAX_ITERATIONS = 5
# {{docs-fragment agent_helper}}
async def run_chain_with_tools(
type: str, state: AgentState, llm: str, system_message: str, tool_names: list[str]
) -> AgentState:
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful AI assistant, collaborating with other assistants."
" Use the provided tools to progress towards answering the question."
" If you are unable to fully answer, that's OK; another assistant with different tools"
" will help where you left off. Execute what you can to make progress."
" If you or any other assistant has the FINAL TRANSACTION PROPOSAL: **BUY/HOLD/SELL** or deliverable,"
" prefix your response with FINAL TRANSACTION PROPOSAL: **BUY/HOLD/SELL** so the team knows to stop."
" You have access to the following tools: {tool_names}.\n{system_message}"
" For your reference, the current date is {current_date}. The company we want to look at is {ticker}.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
prompt = prompt.partial(system_message=system_message)
prompt = prompt.partial(tool_names=", ".join(tool_names))
prompt = prompt.partial(current_date=state.trade_date)
prompt = prompt.partial(ticker=state.company_of_interest)
chain = prompt | ChatOpenAI(model=llm).bind_tools(
[getattr(toolkit, tool_name).func for tool_name in tool_names]
)
iteration = 0
while iteration < MAX_ITERATIONS:
result = await chain.ainvoke(state.messages)
state.messages.append(convert_to_openai_messages(result))
if not result.tool_calls:
# Final response — no tools required
setattr(state, f"{type}_report", result.content or "")
break
# Run all tool calls in parallel
async def run_single_tool(tool_call):
tool_name = tool_call["name"]
tool_args = tool_call["args"]
tool = getattr(toolkit, tool_name, None)
if not tool:
return None
content = await tool(**tool_args)
return ToolMessage(
tool_call_id=tool_call["id"], name=tool_name, content=content
)
with flyte.group(f"tool_calls_iteration_{iteration}"):
tool_messages = await asyncio.gather(
*[run_single_tool(tc) for tc in result.tool_calls]
)
# Add valid tool results to state
tool_messages = [msg for msg in tool_messages if msg]
state.messages.extend(convert_to_openai_messages(tool_messages))
iteration += 1
else:
# Reached iteration cap — optionally raise or log
print(f"Max iterations ({MAX_ITERATIONS}) reached for {type}")
return state
# {{/docs-fragment agent_helper}}
@env.task
async def create_fundamentals_analyst(
llm: str, state: AgentState, online_tools: bool
) -> AgentState:
if online_tools:
tools = [toolkit.get_fundamentals_openai]
else:
tools = [
toolkit.get_finnhub_company_insider_sentiment,
toolkit.get_finnhub_company_insider_transactions,
toolkit.get_simfin_balance_sheet,
toolkit.get_simfin_cashflow,
toolkit.get_simfin_income_stmt,
]
system_message = (
"You are a researcher tasked with analyzing fundamental information over the past week about a company. "
"Please write a comprehensive report of the company's fundamental information such as financial documents, "
"company profile, basic company financials, company financial history, insider sentiment, and insider "
"transactions to gain a full view of the company's "
"fundamental information to inform traders. Make sure to include as much detail as possible. "
"Do not simply state the trends are mixed, "
"provide detailed and finegrained analysis and insights that may help traders make decisions. "
"Make sure to append a Markdown table at the end of the report to organize key points in the report, "
"organized and easy to read."
)
tool_names = [tool.func.__name__ for tool in tools]
return await run_chain_with_tools(
"fundamentals", state, llm, system_message, tool_names
)
@env.task
async def create_market_analyst(
llm: str, state: AgentState, online_tools: bool
) -> AgentState:
if online_tools:
tools = [
toolkit.get_YFin_data_online,
toolkit.get_stockstats_indicators_report_online,
]
else:
tools = [
toolkit.get_YFin_data,
toolkit.get_stockstats_indicators_report,
]
system_message = (
"""You are a trading assistant tasked with analyzing financial markets.
Your role is to select the **most relevant indicators** for a given market condition
or trading strategy from the following list.
The goal is to choose up to **8 indicators** that provide complementary insights without redundancy.
Categories and each category's indicators are:
Moving Averages:
- close_50_sma: 50 SMA: A medium-term trend indicator.
Usage: Identify trend direction and serve as dynamic support/resistance.
Tips: It lags price; combine with faster indicators for timely signals.
- close_200_sma: 200 SMA: A long-term trend benchmark.
Usage: Confirm overall market trend and identify golden/death cross setups.
Tips: It reacts slowly; best for strategic trend confirmation rather than frequent trading entries.
- close_10_ema: 10 EMA: A responsive short-term average.
Usage: Capture quick shifts in momentum and potential entry points.
Tips: Prone to noise in choppy markets; use alongside longer averages for filtering false signals.
MACD Related:
- macd: MACD: Computes momentum via differences of EMAs.
Usage: Look for crossovers and divergence as signals of trend changes.
Tips: Confirm with other indicators in low-volatility or sideways markets.
- macds: MACD Signal: An EMA smoothing of the MACD line.
Usage: Use crossovers with the MACD line to trigger trades.
Tips: Should be part of a broader strategy to avoid false positives.
- macdh: MACD Histogram: Shows the gap between the MACD line and its signal.
Usage: Visualize momentum strength and spot divergence early.
Tips: Can be volatile; complement with additional filters in fast-moving markets.
Momentum Indicators:
- rsi: RSI: Measures momentum to flag overbought/oversold conditions.
Usage: Apply 70/30 thresholds and watch for divergence to signal reversals.
Tips: In strong trends, RSI may remain extreme; always cross-check with trend analysis.
Volatility Indicators:
- boll: Bollinger Middle: A 20 SMA serving as the basis for Bollinger Bands.
Usage: Acts as a dynamic benchmark for price movement.
Tips: Combine with the upper and lower bands to effectively spot breakouts or reversals.
- boll_ub: Bollinger Upper Band: Typically 2 standard deviations above the middle line.
Usage: Signals potential overbought conditions and breakout zones.
Tips: Confirm signals with other tools; prices may ride the band in strong trends.
- boll_lb: Bollinger Lower Band: Typically 2 standard deviations below the middle line.
Usage: Indicates potential oversold conditions.
Tips: Use additional analysis to avoid false reversal signals.
- atr: ATR: Averages true range to measure volatility.
Usage: Set stop-loss levels and adjust position sizes based on current market volatility.
Tips: It's a reactive measure, so use it as part of a broader risk management strategy.
Volume-Based Indicators:
- vwma: VWMA: A moving average weighted by volume.
Usage: Confirm trends by integrating price action with volume data.
Tips: Watch for skewed results from volume spikes; use in combination with other volume analyses.
- Select indicators that provide diverse and complementary information.
Avoid redundancy (e.g., do not select both rsi and stochrsi).
Also briefly explain why they are suitable for the given market context.
When you tool call, please use the exact name of the indicators provided above as they are defined parameters,
otherwise your call will fail.
Please make sure to call get_YFin_data first to retrieve the CSV that is needed to generate indicators.
Write a very detailed and nuanced report of the trends you observe.
Do not simply state the trends are mixed, provide detailed and finegrained analysis
and insights that may help traders make decisions."""
""" Make sure to append a Markdown table at the end of the report to
organize key points in the report, organized and easy to read."""
)
tool_names = [tool.func.__name__ for tool in tools]
return await run_chain_with_tools("market", state, llm, system_message, tool_names)
# {{docs-fragment news_analyst}}
@env.task
async def create_news_analyst(
llm: str, state: AgentState, online_tools: bool
) -> AgentState:
if online_tools:
tools = [
toolkit.get_global_news_openai,
toolkit.get_google_news,
]
else:
tools = [
toolkit.get_finnhub_news,
toolkit.get_reddit_news,
toolkit.get_google_news,
]
system_message = (
"You are a news researcher tasked with analyzing recent news and trends over the past week. "
"Please write a comprehensive report of the current state of the world that is relevant for "
"trading and macroeconomics. "
"Look at news from EODHD, and finnhub to be comprehensive. Do not simply state the trends are mixed, "
"provide detailed and finegrained analysis and insights that may help traders make decisions."
""" Make sure to append a Markdown table at the end of the report to organize key points in the report,
organized and easy to read."""
)
tool_names = [tool.func.__name__ for tool in tools]
return await run_chain_with_tools("news", state, llm, system_message, tool_names)
# {{/docs-fragment news_analyst}}
@env.task
async def create_social_media_analyst(
llm: str, state: AgentState, online_tools: bool
) -> AgentState:
if online_tools:
tools = [toolkit.get_stock_news_openai]
else:
tools = [toolkit.get_reddit_stock_info]
system_message = (
"You are a social media and company specific news researcher/analyst tasked with analyzing social media posts, "
"recent company news, and public sentiment for a specific company over the past week. "
"You will be given a company's name your objective is to write a comprehensive long report "
"detailing your analysis, insights, and implications for traders and investors on this company's current state "
"after looking at social media and what people are saying about that company, "
"analyzing sentiment data of what people feel each day about the company, and looking at recent company news. "
"Try to look at all sources possible from social media to sentiment to news. Do not simply state the trends "
"are mixed, provide detailed and finegrained analysis and insights that may help traders make decisions."
""" Make sure to append a Makrdown table at the end of the report to organize key points in the report,
organized and easy to read."""
)
tool_names = [tool.func.__name__ for tool in tools]
return await run_chain_with_tools(
"sentiment", state, llm, system_message, tool_names
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/trading_agents/agents/analysts.py*
Each analyst agent uses a helper function to bind tools, iterate through reasoning steps (up to a configurable maximum), and produce an answer. Setting a max iteration count is crucial to prevent runaway loops. As agents reason, their message history is preserved in their internal state and passed along to the next agent in the chain.
```
import asyncio
from agents.utils.utils import AgentState
from flyte_env import env
from langchain_core.messages import ToolMessage, convert_to_openai_messages
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from tools import toolkit
import flyte
MAX_ITERATIONS = 5
# {{docs-fragment agent_helper}}
async def run_chain_with_tools(
type: str, state: AgentState, llm: str, system_message: str, tool_names: list[str]
) -> AgentState:
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful AI assistant, collaborating with other assistants."
" Use the provided tools to progress towards answering the question."
" If you are unable to fully answer, that's OK; another assistant with different tools"
" will help where you left off. Execute what you can to make progress."
" If you or any other assistant has the FINAL TRANSACTION PROPOSAL: **BUY/HOLD/SELL** or deliverable,"
" prefix your response with FINAL TRANSACTION PROPOSAL: **BUY/HOLD/SELL** so the team knows to stop."
" You have access to the following tools: {tool_names}.\n{system_message}"
" For your reference, the current date is {current_date}. The company we want to look at is {ticker}.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
prompt = prompt.partial(system_message=system_message)
prompt = prompt.partial(tool_names=", ".join(tool_names))
prompt = prompt.partial(current_date=state.trade_date)
prompt = prompt.partial(ticker=state.company_of_interest)
chain = prompt | ChatOpenAI(model=llm).bind_tools(
[getattr(toolkit, tool_name).func for tool_name in tool_names]
)
iteration = 0
while iteration < MAX_ITERATIONS:
result = await chain.ainvoke(state.messages)
state.messages.append(convert_to_openai_messages(result))
if not result.tool_calls:
# Final response — no tools required
setattr(state, f"{type}_report", result.content or "")
break
# Run all tool calls in parallel
async def run_single_tool(tool_call):
tool_name = tool_call["name"]
tool_args = tool_call["args"]
tool = getattr(toolkit, tool_name, None)
if not tool:
return None
content = await tool(**tool_args)
return ToolMessage(
tool_call_id=tool_call["id"], name=tool_name, content=content
)
with flyte.group(f"tool_calls_iteration_{iteration}"):
tool_messages = await asyncio.gather(
*[run_single_tool(tc) for tc in result.tool_calls]
)
# Add valid tool results to state
tool_messages = [msg for msg in tool_messages if msg]
state.messages.extend(convert_to_openai_messages(tool_messages))
iteration += 1
else:
# Reached iteration cap — optionally raise or log
print(f"Max iterations ({MAX_ITERATIONS}) reached for {type}")
return state
# {{/docs-fragment agent_helper}}
@env.task
async def create_fundamentals_analyst(
llm: str, state: AgentState, online_tools: bool
) -> AgentState:
if online_tools:
tools = [toolkit.get_fundamentals_openai]
else:
tools = [
toolkit.get_finnhub_company_insider_sentiment,
toolkit.get_finnhub_company_insider_transactions,
toolkit.get_simfin_balance_sheet,
toolkit.get_simfin_cashflow,
toolkit.get_simfin_income_stmt,
]
system_message = (
"You are a researcher tasked with analyzing fundamental information over the past week about a company. "
"Please write a comprehensive report of the company's fundamental information such as financial documents, "
"company profile, basic company financials, company financial history, insider sentiment, and insider "
"transactions to gain a full view of the company's "
"fundamental information to inform traders. Make sure to include as much detail as possible. "
"Do not simply state the trends are mixed, "
"provide detailed and finegrained analysis and insights that may help traders make decisions. "
"Make sure to append a Markdown table at the end of the report to organize key points in the report, "
"organized and easy to read."
)
tool_names = [tool.func.__name__ for tool in tools]
return await run_chain_with_tools(
"fundamentals", state, llm, system_message, tool_names
)
@env.task
async def create_market_analyst(
llm: str, state: AgentState, online_tools: bool
) -> AgentState:
if online_tools:
tools = [
toolkit.get_YFin_data_online,
toolkit.get_stockstats_indicators_report_online,
]
else:
tools = [
toolkit.get_YFin_data,
toolkit.get_stockstats_indicators_report,
]
system_message = (
"""You are a trading assistant tasked with analyzing financial markets.
Your role is to select the **most relevant indicators** for a given market condition
or trading strategy from the following list.
The goal is to choose up to **8 indicators** that provide complementary insights without redundancy.
Categories and each category's indicators are:
Moving Averages:
- close_50_sma: 50 SMA: A medium-term trend indicator.
Usage: Identify trend direction and serve as dynamic support/resistance.
Tips: It lags price; combine with faster indicators for timely signals.
- close_200_sma: 200 SMA: A long-term trend benchmark.
Usage: Confirm overall market trend and identify golden/death cross setups.
Tips: It reacts slowly; best for strategic trend confirmation rather than frequent trading entries.
- close_10_ema: 10 EMA: A responsive short-term average.
Usage: Capture quick shifts in momentum and potential entry points.
Tips: Prone to noise in choppy markets; use alongside longer averages for filtering false signals.
MACD Related:
- macd: MACD: Computes momentum via differences of EMAs.
Usage: Look for crossovers and divergence as signals of trend changes.
Tips: Confirm with other indicators in low-volatility or sideways markets.
- macds: MACD Signal: An EMA smoothing of the MACD line.
Usage: Use crossovers with the MACD line to trigger trades.
Tips: Should be part of a broader strategy to avoid false positives.
- macdh: MACD Histogram: Shows the gap between the MACD line and its signal.
Usage: Visualize momentum strength and spot divergence early.
Tips: Can be volatile; complement with additional filters in fast-moving markets.
Momentum Indicators:
- rsi: RSI: Measures momentum to flag overbought/oversold conditions.
Usage: Apply 70/30 thresholds and watch for divergence to signal reversals.
Tips: In strong trends, RSI may remain extreme; always cross-check with trend analysis.
Volatility Indicators:
- boll: Bollinger Middle: A 20 SMA serving as the basis for Bollinger Bands.
Usage: Acts as a dynamic benchmark for price movement.
Tips: Combine with the upper and lower bands to effectively spot breakouts or reversals.
- boll_ub: Bollinger Upper Band: Typically 2 standard deviations above the middle line.
Usage: Signals potential overbought conditions and breakout zones.
Tips: Confirm signals with other tools; prices may ride the band in strong trends.
- boll_lb: Bollinger Lower Band: Typically 2 standard deviations below the middle line.
Usage: Indicates potential oversold conditions.
Tips: Use additional analysis to avoid false reversal signals.
- atr: ATR: Averages true range to measure volatility.
Usage: Set stop-loss levels and adjust position sizes based on current market volatility.
Tips: It's a reactive measure, so use it as part of a broader risk management strategy.
Volume-Based Indicators:
- vwma: VWMA: A moving average weighted by volume.
Usage: Confirm trends by integrating price action with volume data.
Tips: Watch for skewed results from volume spikes; use in combination with other volume analyses.
- Select indicators that provide diverse and complementary information.
Avoid redundancy (e.g., do not select both rsi and stochrsi).
Also briefly explain why they are suitable for the given market context.
When you tool call, please use the exact name of the indicators provided above as they are defined parameters,
otherwise your call will fail.
Please make sure to call get_YFin_data first to retrieve the CSV that is needed to generate indicators.
Write a very detailed and nuanced report of the trends you observe.
Do not simply state the trends are mixed, provide detailed and finegrained analysis
and insights that may help traders make decisions."""
""" Make sure to append a Markdown table at the end of the report to
organize key points in the report, organized and easy to read."""
)
tool_names = [tool.func.__name__ for tool in tools]
return await run_chain_with_tools("market", state, llm, system_message, tool_names)
# {{docs-fragment news_analyst}}
@env.task
async def create_news_analyst(
llm: str, state: AgentState, online_tools: bool
) -> AgentState:
if online_tools:
tools = [
toolkit.get_global_news_openai,
toolkit.get_google_news,
]
else:
tools = [
toolkit.get_finnhub_news,
toolkit.get_reddit_news,
toolkit.get_google_news,
]
system_message = (
"You are a news researcher tasked with analyzing recent news and trends over the past week. "
"Please write a comprehensive report of the current state of the world that is relevant for "
"trading and macroeconomics. "
"Look at news from EODHD, and finnhub to be comprehensive. Do not simply state the trends are mixed, "
"provide detailed and finegrained analysis and insights that may help traders make decisions."
""" Make sure to append a Markdown table at the end of the report to organize key points in the report,
organized and easy to read."""
)
tool_names = [tool.func.__name__ for tool in tools]
return await run_chain_with_tools("news", state, llm, system_message, tool_names)
# {{/docs-fragment news_analyst}}
@env.task
async def create_social_media_analyst(
llm: str, state: AgentState, online_tools: bool
) -> AgentState:
if online_tools:
tools = [toolkit.get_stock_news_openai]
else:
tools = [toolkit.get_reddit_stock_info]
system_message = (
"You are a social media and company specific news researcher/analyst tasked with analyzing social media posts, "
"recent company news, and public sentiment for a specific company over the past week. "
"You will be given a company's name your objective is to write a comprehensive long report "
"detailing your analysis, insights, and implications for traders and investors on this company's current state "
"after looking at social media and what people are saying about that company, "
"analyzing sentiment data of what people feel each day about the company, and looking at recent company news. "
"Try to look at all sources possible from social media to sentiment to news. Do not simply state the trends "
"are mixed, provide detailed and finegrained analysis and insights that may help traders make decisions."
""" Make sure to append a Makrdown table at the end of the report to organize key points in the report,
organized and easy to read."""
)
tool_names = [tool.func.__name__ for tool in tools]
return await run_chain_with_tools(
"sentiment", state, llm, system_message, tool_names
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/trading_agents/agents/analysts.py*
Once all analyst reports are complete, their outputs are collected and passed to the next stage of the workflow.
### Research agents
The research phase consists of two agents: a bullish researcher and a bearish one. They evaluate the company from opposing viewpoints, drawing on the analysts' reports. Unlike analysts, they don't use tools. Their role is to interpret, critique, and develop positions based on the evidence.
```
from agents.utils.utils import AgentState, InvestmentDebateState, memory_init
from flyte_env import env
from langchain_openai import ChatOpenAI
# {{docs-fragment bear_researcher}}
@env.task
async def create_bear_researcher(llm: str, state: AgentState) -> AgentState:
investment_debate_state = state.investment_debate_state
history = investment_debate_state.history
bear_history = investment_debate_state.bear_history
current_response = investment_debate_state.current_response
market_research_report = state.market_report
sentiment_report = state.sentiment_report
news_report = state.news_report
fundamentals_report = state.fundamentals_report
memory = await memory_init(name="bear-researcher")
curr_situation = f"{market_research_report}\n\n{sentiment_report}\n\n{news_report}\n\n{fundamentals_report}"
past_memories = memory.get_memories(curr_situation, n_matches=2)
past_memory_str = ""
for rec in past_memories:
past_memory_str += rec["recommendation"] + "\n\n"
prompt = f"""You are a Bear Analyst making the case against investing in the stock.
Your goal is to present a well-reasoned argument emphasizing risks, challenges, and negative indicators.
Leverage the provided research and data to highlight potential downsides and counter bullish arguments effectively.
Key points to focus on:
- Risks and Challenges: Highlight factors like market saturation, financial instability,
or macroeconomic threats that could hinder the stock's performance.
- Competitive Weaknesses: Emphasize vulnerabilities such as weaker market positioning, declining innovation,
or threats from competitors.
- Negative Indicators: Use evidence from financial data, market trends, or recent adverse news to support your position.
- Bull Counterpoints: Critically analyze the bull argument with specific data and sound reasoning,
exposing weaknesses or over-optimistic assumptions.
- Engagement: Present your argument in a conversational style, directly engaging with the bull analyst's points
and debating effectively rather than simply listing facts.
Resources available:
Market research report: {market_research_report}
Social media sentiment report: {sentiment_report}
Latest world affairs news: {news_report}
Company fundamentals report: {fundamentals_report}
Conversation history of the debate: {history}
Last bull argument: {current_response}
Reflections from similar situations and lessons learned: {past_memory_str}
Use this information to deliver a compelling bear argument, refute the bull's claims, and engage in a dynamic debate
that demonstrates the risks and weaknesses of investing in the stock.
You must also address reflections and learn from lessons and mistakes you made in the past.
"""
response = ChatOpenAI(model=llm).invoke(prompt)
argument = f"Bear Analyst: {response.content}"
new_investment_debate_state = InvestmentDebateState(
history=history + "\n" + argument,
bear_history=bear_history + "\n" + argument,
bull_history=investment_debate_state.bull_history,
current_response=argument,
count=investment_debate_state.count + 1,
)
state.investment_debate_state = new_investment_debate_state
return state
# {{/docs-fragment bear_researcher}}
@env.task
async def create_bull_researcher(llm: str, state: AgentState) -> AgentState:
investment_debate_state = state.investment_debate_state
history = investment_debate_state.history
bull_history = investment_debate_state.bull_history
current_response = investment_debate_state.current_response
market_research_report = state.market_report
sentiment_report = state.sentiment_report
news_report = state.news_report
fundamentals_report = state.fundamentals_report
memory = await memory_init(name="bull-researcher")
curr_situation = f"{market_research_report}\n\n{sentiment_report}\n\n{news_report}\n\n{fundamentals_report}"
past_memories = memory.get_memories(curr_situation, n_matches=2)
past_memory_str = ""
for rec in past_memories:
past_memory_str += rec["recommendation"] + "\n\n"
prompt = f"""You are a Bull Analyst advocating for investing in the stock.
Your task is to build a strong, evidence-based case emphasizing growth potential, competitive advantages,
and positive market indicators.
Leverage the provided research and data to address concerns and counter bearish arguments effectively.
Key points to focus on:
- Growth Potential: Highlight the company's market opportunities, revenue projections, and scalability.
- Competitive Advantages: Emphasize factors like unique products, strong branding, or dominant market positioning.
- Positive Indicators: Use financial health, industry trends, and recent positive news as evidence.
- Bear Counterpoints: Critically analyze the bear argument with specific data and sound reasoning, addressing
concerns thoroughly and showing why the bull perspective holds stronger merit.
- Engagement: Present your argument in a conversational style, engaging directly with the bear analyst's points
and debating effectively rather than just listing data.
Resources available:
Market research report: {market_research_report}
Social media sentiment report: {sentiment_report}
Latest world affairs news: {news_report}
Company fundamentals report: {fundamentals_report}
Conversation history of the debate: {history}
Last bear argument: {current_response}
Reflections from similar situations and lessons learned: {past_memory_str}
Use this information to deliver a compelling bull argument, refute the bear's concerns, and engage in a dynamic debate
that demonstrates the strengths of the bull position.
You must also address reflections and learn from lessons and mistakes you made in the past.
"""
response = ChatOpenAI(model=llm).invoke(prompt)
argument = f"Bull Analyst: {response.content}"
new_investment_debate_state = InvestmentDebateState(
history=history + "\n" + argument,
bull_history=bull_history + "\n" + argument,
bear_history=investment_debate_state.bear_history,
current_response=argument,
count=investment_debate_state.count + 1,
)
state.investment_debate_state = new_investment_debate_state
return state
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/trading_agents/agents/researchers.py*
To aid reasoning, the agents can also retrieve relevant "memories" from a vector database, giving them richer historical context. The number of debate rounds is configurable, and after a few iterations of back-and-forth between the bull and bear, a research manager agent reviews their arguments and makes a final investment decision.
```
from agents.utils.utils import (
AgentState,
InvestmentDebateState,
RiskDebateState,
memory_init,
)
from flyte_env import env
from langchain_openai import ChatOpenAI
# {{docs-fragment research_manager}}
@env.task
async def create_research_manager(llm: str, state: AgentState) -> AgentState:
history = state.investment_debate_state.history
investment_debate_state = state.investment_debate_state
market_research_report = state.market_report
sentiment_report = state.sentiment_report
news_report = state.news_report
fundamentals_report = state.fundamentals_report
memory = await memory_init(name="research-manager")
curr_situation = f"{market_research_report}\n\n{sentiment_report}\n\n{news_report}\n\n{fundamentals_report}"
past_memories = memory.get_memories(curr_situation, n_matches=2)
past_memory_str = ""
for rec in past_memories:
past_memory_str += rec["recommendation"] + "\n\n"
prompt = f"""As the portfolio manager and debate facilitator, your role is to critically evaluate
this round of debate and make a definitive decision:
align with the bear analyst, the bull analyst,
or choose Hold only if it is strongly justified based on the arguments presented.
Summarize the key points from both sides concisely, focusing on the most compelling evidence or reasoning.
Your recommendation—Buy, Sell, or Hold—must be clear and actionable.
Avoid defaulting to Hold simply because both sides have valid points;
commit to a stance grounded in the debate's strongest arguments.
Additionally, develop a detailed investment plan for the trader. This should include:
Your Recommendation: A decisive stance supported by the most convincing arguments.
Rationale: An explanation of why these arguments lead to your conclusion.
Strategic Actions: Concrete steps for implementing the recommendation.
Take into account your past mistakes on similar situations.
Use these insights to refine your decision-making and ensure you are learning and improving.
Present your analysis conversationally, as if speaking naturally, without special formatting.
Here are your past reflections on mistakes:
\"{past_memory_str}\"
Here is the debate:
Debate History:
{history}"""
response = ChatOpenAI(model=llm).invoke(prompt)
new_investment_debate_state = InvestmentDebateState(
judge_decision=response.content,
history=investment_debate_state.history,
bear_history=investment_debate_state.bear_history,
bull_history=investment_debate_state.bull_history,
current_response=response.content,
count=investment_debate_state.count,
)
state.investment_debate_state = new_investment_debate_state
state.investment_plan = response.content
return state
# {{/docs-fragment research_manager}}
@env.task
async def create_risk_manager(llm: str, state: AgentState) -> AgentState:
history = state.risk_debate_state.history
risk_debate_state = state.risk_debate_state
trader_plan = state.investment_plan
market_research_report = state.market_report
sentiment_report = state.sentiment_report
news_report = state.news_report
fundamentals_report = state.fundamentals_report
memory = await memory_init(name="risk-manager")
curr_situation = f"{market_research_report}\n\n{sentiment_report}\n\n{news_report}\n\n{fundamentals_report}"
past_memories = memory.get_memories(curr_situation, n_matches=2)
past_memory_str = ""
for rec in past_memories:
past_memory_str += rec["recommendation"] + "\n\n"
prompt = f"""As the Risk Management Judge and Debate Facilitator,
your goal is to evaluate the debate between three risk analysts—Risky,
Neutral, and Safe/Conservative—and determine the best course of action for the trader.
Your decision must result in a clear recommendation: Buy, Sell, or Hold.
Choose Hold only if strongly justified by specific arguments, not as a fallback when all sides seem valid.
Strive for clarity and decisiveness.
Guidelines for Decision-Making:
1. **Summarize Key Arguments**: Extract the strongest points from each analyst, focusing on relevance to the context.
2. **Provide Rationale**: Support your recommendation with direct quotes and counterarguments from the debate.
3. **Refine the Trader's Plan**: Start with the trader's original plan, **{trader_plan}**,
and adjust it based on the analysts' insights.
4. **Learn from Past Mistakes**: Use lessons from **{past_memory_str}** to address prior misjudgments
and improve the decision you are making now to make sure you don't make a wrong BUY/SELL/HOLD call that loses money.
Deliverables:
- A clear and actionable recommendation: Buy, Sell, or Hold.
- Detailed reasoning anchored in the debate and past reflections.
---
**Analysts Debate History:**
{history}
---
Focus on actionable insights and continuous improvement.
Build on past lessons, critically evaluate all perspectives, and ensure each decision advances better outcomes."""
response = ChatOpenAI(model=llm).invoke(prompt)
new_risk_debate_state = RiskDebateState(
judge_decision=response.content,
history=risk_debate_state.history,
risky_history=risk_debate_state.risky_history,
safe_history=risk_debate_state.safe_history,
neutral_history=risk_debate_state.neutral_history,
latest_speaker="Judge",
current_risky_response=risk_debate_state.current_risky_response,
current_safe_response=risk_debate_state.current_safe_response,
current_neutral_response=risk_debate_state.current_neutral_response,
count=risk_debate_state.count,
)
state.risk_debate_state = new_risk_debate_state
state.final_trade_decision = response.content
return state
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/trading_agents/agents/managers.py*
### Trading agent
The trader agent consolidates the insights from analysts and researchers to generate a final recommendation. It synthesizes competing signals and produces a conclusion such as _Buy for long-term growth despite short-term volatility_.
```
from agents.utils.utils import AgentState, memory_init
from flyte_env import env
from langchain_core.messages import convert_to_openai_messages
from langchain_openai import ChatOpenAI
# {{docs-fragment trader}}
@env.task
async def create_trader(llm: str, state: AgentState) -> AgentState:
company_name = state.company_of_interest
investment_plan = state.investment_plan
market_research_report = state.market_report
sentiment_report = state.sentiment_report
news_report = state.news_report
fundamentals_report = state.fundamentals_report
memory = await memory_init(name="trader")
curr_situation = f"{market_research_report}\n\n{sentiment_report}\n\n{news_report}\n\n{fundamentals_report}"
past_memories = memory.get_memories(curr_situation, n_matches=2)
past_memory_str = ""
for rec in past_memories:
past_memory_str += rec["recommendation"] + "\n\n"
context = {
"role": "user",
"content": f"Based on a comprehensive analysis by a team of analysts, "
f"here is an investment plan tailored for {company_name}. "
"This plan incorporates insights from current technical market trends, "
"macroeconomic indicators, and social media sentiment. "
"Use this plan as a foundation for evaluating your next trading decision.\n\n"
f"Proposed Investment Plan: {investment_plan}\n\n"
"Leverage these insights to make an informed and strategic decision.",
}
messages = [
{
"role": "system",
"content": f"""You are a trading agent analyzing market data to make investment decisions.
Based on your analysis, provide a specific recommendation to buy, sell, or hold.
End with a firm decision and always conclude your response with 'FINAL TRANSACTION PROPOSAL: **BUY/HOLD/SELL**'
to confirm your recommendation.
Do not forget to utilize lessons from past decisions to learn from your mistakes.
Here is some reflections from similar situatiosn you traded in and the lessons learned: {past_memory_str}""",
},
context,
]
result = ChatOpenAI(model=llm).invoke(messages)
state.messages.append(convert_to_openai_messages(result))
state.trader_investment_plan = result.content
state.sender = "Trader"
return state
# {{/docs-fragment trader}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/trading_agents/agents/trader.py*
### Risk agents
Risk agents comprise agents with different risk tolerances: a risky debater, a neutral one, and a conservative one. They assess the portfolio through lenses like market volatility, liquidity, and systemic risk. Similar to the bull-bear debate, these agents engage in internal discussion, after which a risk manager makes the final call.
```
from agents.utils.utils import AgentState, RiskDebateState
from flyte_env import env
from langchain_openai import ChatOpenAI
# {{docs-fragment risk_debator}}
@env.task
async def create_risky_debator(llm: str, state: AgentState) -> AgentState:
risk_debate_state = state.risk_debate_state
history = risk_debate_state.history
risky_history = risk_debate_state.risky_history
current_safe_response = risk_debate_state.current_safe_response
current_neutral_response = risk_debate_state.current_neutral_response
market_research_report = state.market_report
sentiment_report = state.sentiment_report
news_report = state.news_report
fundamentals_report = state.fundamentals_report
trader_decision = state.trader_investment_plan
prompt = f"""As the Risky Risk Analyst, your role is to actively champion high-reward, high-risk opportunities,
emphasizing bold strategies and competitive advantages.
When evaluating the trader's decision or plan, focus intently on the potential upside, growth potential,
and innovative benefits—even when these come with elevated risk.
Use the provided market data and sentiment analysis to strengthen your arguments and challenge the opposing views.
Specifically, respond directly to each point made by the conservative and neutral analysts,
countering with data-driven rebuttals and persuasive reasoning.
Highlight where their caution might miss critical opportunities or where their assumptions may be overly conservative.
Here is the trader's decision:
{trader_decision}
Your task is to create a compelling case for the trader's decision by questioning and critiquing the conservative
and neutral stances to demonstrate why your high-reward perspective offers the best path forward.
Incorporate insights from the following sources into your arguments:
Market Research Report: {market_research_report}
Social Media Sentiment Report: {sentiment_report}
Latest World Affairs Report: {news_report}
Company Fundamentals Report: {fundamentals_report}
Here is the current conversation history: {history}
Here are the last arguments from the conservative analyst: {current_safe_response}
Here are the last arguments from the neutral analyst: {current_neutral_response}.
If there are no responses from the other viewpoints, do not halluncinate and just present your point.
Engage actively by addressing any specific concerns raised, refuting the weaknesses in their logic,
and asserting the benefits of risk-taking to outpace market norms.
Maintain a focus on debating and persuading, not just presenting data.
Challenge each counterpoint to underscore why a high-risk approach is optimal.
Output conversationally as if you are speaking without any special formatting."""
response = ChatOpenAI(model=llm).invoke(prompt)
argument = f"Risky Analyst: {response.content}"
new_risk_debate_state = RiskDebateState(
history=history + "\n" + argument,
risky_history=risky_history + "\n" + argument,
safe_history=risk_debate_state.safe_history,
neutral_history=risk_debate_state.neutral_history,
latest_speaker="Risky",
current_risky_response=argument,
current_safe_response=current_safe_response,
current_neutral_response=current_neutral_response,
count=risk_debate_state.count + 1,
)
state.risk_debate_state = new_risk_debate_state
return state
# {{/docs-fragment risk_debator}}
@env.task
async def create_safe_debator(llm: str, state: AgentState) -> AgentState:
risk_debate_state = state.risk_debate_state
history = risk_debate_state.history
safe_history = risk_debate_state.safe_history
current_risky_response = risk_debate_state.current_risky_response
current_neutral_response = risk_debate_state.current_neutral_response
market_research_report = state.market_report
sentiment_report = state.sentiment_report
news_report = state.news_report
fundamentals_report = state.fundamentals_report
trader_decision = state.trader_investment_plan
prompt = f"""As the Safe/Conservative Risk Analyst, your primary objective is to protect assets,
minimize volatility, and ensure steady, reliable growth. You prioritize stability, security, and risk mitigation,
carefully assessing potential losses, economic downturns, and market volatility.
When evaluating the trader's decision or plan, critically examine high-risk elements,
pointing out where the decision may expose the firm to undue risk and where more cautious
alternatives could secure long-term gains.
Here is the trader's decision:
{trader_decision}
Your task is to actively counter the arguments of the Risky and Neutral Analysts,
highlighting where their views may overlook potential threats or fail to prioritize sustainability.
Respond directly to their points, drawing from the following data sources
to build a convincing case for a low-risk approach adjustment to the trader's decision:
Market Research Report: {market_research_report}
Social Media Sentiment Report: {sentiment_report}
Latest World Affairs Report: {news_report}
Company Fundamentals Report: {fundamentals_report}
Here is the current conversation history: {history}
Here is the last response from the risky analyst: {current_risky_response}
Here is the last response from the neutral analyst: {current_neutral_response}.
If there are no responses from the other viewpoints, do not halluncinate and just present your point.
Engage by questioning their optimism and emphasizing the potential downsides they may have overlooked.
Address each of their counterpoints to showcase why a conservative stance is ultimately the
safest path for the firm's assets.
Focus on debating and critiquing their arguments to demonstrate the strength of a low-risk strategy
over their approaches.
Output conversationally as if you are speaking without any special formatting."""
response = ChatOpenAI(model=llm).invoke(prompt)
argument = f"Safe Analyst: {response.content}"
new_risk_debate_state = RiskDebateState(
history=history + "\n" + argument,
risky_history=risk_debate_state.risky_history,
safe_history=safe_history + "\n" + argument,
neutral_history=risk_debate_state.neutral_history,
latest_speaker="Safe",
current_risky_response=current_risky_response,
current_safe_response=argument,
current_neutral_response=current_neutral_response,
count=risk_debate_state.count + 1,
)
state.risk_debate_state = new_risk_debate_state
return state
@env.task
async def create_neutral_debator(llm: str, state: AgentState) -> AgentState:
risk_debate_state = state.risk_debate_state
history = risk_debate_state.history
neutral_history = risk_debate_state.neutral_history
current_risky_response = risk_debate_state.current_risky_response
current_safe_response = risk_debate_state.current_safe_response
market_research_report = state.market_report
sentiment_report = state.sentiment_report
news_report = state.news_report
fundamentals_report = state.fundamentals_report
trader_decision = state.trader_investment_plan
prompt = f"""As the Neutral Risk Analyst, your role is to provide a balanced perspective,
weighing both the potential benefits and risks of the trader's decision or plan.
You prioritize a well-rounded approach, evaluating the upsides
and downsides while factoring in broader market trends,
potential economic shifts, and diversification strategies.Here is the trader's decision:
{trader_decision}
Your task is to challenge both the Risky and Safe Analysts,
pointing out where each perspective may be overly optimistic or overly cautious.
Use insights from the following data sources to support a moderate, sustainable strategy
to adjust the trader's decision:
Market Research Report: {market_research_report}
Social Media Sentiment Report: {sentiment_report}
Latest World Affairs Report: {news_report}
Company Fundamentals Report: {fundamentals_report}
Here is the current conversation history: {history}
Here is the last response from the risky analyst: {current_risky_response}
Here is the last response from the safe analyst: {current_safe_response}.
If there are no responses from the other viewpoints, do not halluncinate and just present your point.
Engage actively by analyzing both sides critically, addressing weaknesses in the risky
and conservative arguments to advocate for a more balanced approach.
Challenge each of their points to illustrate why a moderate risk strategy might offer the best of both worlds,
providing growth potential while safeguarding against extreme volatility.
Focus on debating rather than simply presenting data, aiming to show that a balanced view can lead to
the most reliable outcomes. Output conversationally as if you are speaking without any special formatting."""
response = ChatOpenAI(model=llm).invoke(prompt)
argument = f"Neutral Analyst: {response.content}"
new_risk_debate_state = RiskDebateState(
history=history + "\n" + argument,
risky_history=risk_debate_state.risky_history,
safe_history=risk_debate_state.safe_history,
neutral_history=neutral_history + "\n" + argument,
latest_speaker="Neutral",
current_risky_response=current_risky_response,
current_safe_response=current_safe_response,
current_neutral_response=argument,
count=risk_debate_state.count + 1,
)
state.risk_debate_state = new_risk_debate_state
return state
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/trading_agents/agents/risk_debators.py*
The outcome of the risk manager — whether to proceed with the trade or not — is considered the final decision of the trading simulation.
You can visualize this full pipeline in the Flyte/Union UI, where every step is logged.
You’ll see input/output metadata for each tool and agent task.
Thanks to Flyte's caching, repeated steps are skipped unless inputs change, saving time and compute resources.
### Retaining agent memory with S3 vectors
To help agents learn from past decisions, we persist their memory in a vector store. In this example, we use an [S3 vector](https://aws.amazon.com/s3/features/vectors/) bucket for their simplicity and tight integration with Flyte and Union, but any vector database can be used.
Note: To use the S3 vector store, make sure your IAM role has the following permissions configured:
```
s3vectors:CreateVectorBucket
s3vectors:CreateIndex
s3vectors:PutVectors
s3vectors:GetIndex
s3vectors:GetVectors
s3vectors:QueryVectors
s3vectors:GetVectorBucket
```
After each trade decision, you can run a `reflect_on_decisions` task. This evaluates whether the final outcome aligned with the agent's recommendation and stores that reflection in the vector store. These stored insights can later be retrieved to provide historical context and improve future decision-making.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "akshare==1.16.98",
# "backtrader==1.9.78.123",
# "boto3==1.39.9",
# "chainlit==2.5.5",
# "eodhd==1.0.32",
# "feedparser==6.0.11",
# "finnhub-python==2.4.23",
# "langchain-experimental==0.3.4",
# "langchain-openai==0.3.23",
# "pandas==2.3.0",
# "parsel==1.10.0",
# "praw==7.8.1",
# "pytz==2025.2",
# "questionary==2.1.0",
# "redis==6.2.0",
# "requests==2.32.4",
# "stockstats==0.6.5",
# "tqdm==4.67.1",
# "tushare==1.4.21",
# "typing-extensions==4.14.0",
# "yfinance==0.2.63",
# ]
# main = "main"
# params = ""
# ///
import asyncio
from copy import deepcopy
import agents
import agents.analysts
from agents.managers import create_research_manager, create_risk_manager
from agents.researchers import create_bear_researcher, create_bull_researcher
from agents.risk_debators import (
create_neutral_debator,
create_risky_debator,
create_safe_debator,
)
from agents.trader import create_trader
from agents.utils.utils import AgentState
from flyte_env import DEEP_THINKING_LLM, QUICK_THINKING_LLM, env, flyte
from langchain_openai import ChatOpenAI
from reflection import (
reflect_bear_researcher,
reflect_bull_researcher,
reflect_research_manager,
reflect_risk_manager,
reflect_trader,
)
@env.task
async def process_signal(full_signal: str, QUICK_THINKING_LLM: str) -> str:
"""Process a full trading signal to extract the core decision."""
messages = [
{
"role": "system",
"content": """You are an efficient assistant designed to analyze paragraphs or
financial reports provided by a group of analysts.
Your task is to extract the investment decision: SELL, BUY, or HOLD.
Provide only the extracted decision (SELL, BUY, or HOLD) as your output,
without adding any additional text or information.""",
},
{"role": "human", "content": full_signal},
]
return ChatOpenAI(model=QUICK_THINKING_LLM).invoke(messages).content
async def run_analyst(analyst_name, state, online_tools):
# Create a copy of the state for isolation
run_fn = getattr(agents.analysts, f"create_{analyst_name}_analyst")
# Run the analyst's chain
result_state = await run_fn(QUICK_THINKING_LLM, state, online_tools)
# Determine the report key
report_key = (
"sentiment_report"
if analyst_name == "social_media"
else f"{analyst_name}_report"
)
report_value = getattr(result_state, report_key)
return result_state.messages[1:], report_key, report_value
# {{docs-fragment main}}
@env.task
async def main(
selected_analysts: list[str] = [
"market",
"fundamentals",
"news",
"social_media",
],
max_debate_rounds: int = 1,
max_risk_discuss_rounds: int = 1,
online_tools: bool = True,
company_name: str = "NVDA",
trade_date: str = "2024-05-12",
) -> tuple[str, AgentState]:
if not selected_analysts:
raise ValueError(
"No analysts selected. Please select at least one analyst from market, fundamentals, news, or social_media."
)
state = AgentState(
messages=[{"role": "human", "content": company_name}],
company_of_interest=company_name,
trade_date=str(trade_date),
)
# Run all analysts concurrently
results = await asyncio.gather(
*[
run_analyst(analyst, deepcopy(state), online_tools)
for analyst in selected_analysts
]
)
# Flatten and append all resulting messages into the shared state
for messages, report_attr, report in results:
state.messages.extend(messages)
setattr(state, report_attr, report)
# Bull/Bear debate loop
state = await create_bull_researcher(QUICK_THINKING_LLM, state) # Start with bull
while state.investment_debate_state.count < 2 * max_debate_rounds:
current = state.investment_debate_state.current_response
if current.startswith("Bull"):
state = await create_bear_researcher(QUICK_THINKING_LLM, state)
else:
state = await create_bull_researcher(QUICK_THINKING_LLM, state)
state = await create_research_manager(DEEP_THINKING_LLM, state)
state = await create_trader(QUICK_THINKING_LLM, state)
# Risk debate loop
state = await create_risky_debator(QUICK_THINKING_LLM, state) # Start with risky
while state.risk_debate_state.count < 3 * max_risk_discuss_rounds:
speaker = state.risk_debate_state.latest_speaker
if speaker == "Risky":
state = await create_safe_debator(QUICK_THINKING_LLM, state)
elif speaker == "Safe":
state = await create_neutral_debator(QUICK_THINKING_LLM, state)
else:
state = await create_risky_debator(QUICK_THINKING_LLM, state)
state = await create_risk_manager(DEEP_THINKING_LLM, state)
decision = await process_signal(state.final_trade_decision, QUICK_THINKING_LLM)
return decision, state
# {{/docs-fragment main}}
# {{docs-fragment reflect_on_decisions}}
@env.task
async def reflect_and_store(state: AgentState, returns: str) -> str:
await asyncio.gather(
reflect_bear_researcher(state, returns),
reflect_bull_researcher(state, returns),
reflect_trader(state, returns),
reflect_risk_manager(state, returns),
reflect_research_manager(state, returns),
)
return "Reflection completed."
# Run the reflection task after the main function
@env.task(cache="disable")
async def reflect_on_decisions(
returns: str,
selected_analysts: list[str] = [
"market",
"fundamentals",
"news",
"social_media",
],
max_debate_rounds: int = 1,
max_risk_discuss_rounds: int = 1,
online_tools: bool = True,
company_name: str = "NVDA",
trade_date: str = "2024-05-12",
) -> str:
_, state = await main(
selected_analysts,
max_debate_rounds,
max_risk_discuss_rounds,
online_tools,
company_name,
trade_date,
)
return await reflect_and_store(state, returns)
# {{/docs-fragment reflect_on_decisions}}
# {{docs-fragment execute_main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(main)
print(run.url)
run.wait()
# run = flyte.run(reflect_on_decisions, "+3.2% gain over 5 days")
# print(run.url)
# {{/docs-fragment execute_main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/trading_agents/main.py*
### Running the simulation
First, set up your OpenAI secret (from [openai.com](https://platform.openai.com/api-keys)) and Finnhub API key (from [finnhub.io](https://finnhub.io/)):
```
flyte create secret openai_api_key
flyte create secret finnhub_api_key
```
Then [clone the repo](https://github.com/unionai/unionai-examples), navigate to the `tutorials-v2/trading_agents` directory, and run the following commands:
```
flyte create config --endpoint --project --domain --builder remote
uv run main.py
```
If you'd like to run the `reflect_on_decisions` task instead, comment out the `main` function call and uncomment the `reflect_on_decisions` call in the `__main__` block:
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.0.0b52",
# "akshare==1.16.98",
# "backtrader==1.9.78.123",
# "boto3==1.39.9",
# "chainlit==2.5.5",
# "eodhd==1.0.32",
# "feedparser==6.0.11",
# "finnhub-python==2.4.23",
# "langchain-experimental==0.3.4",
# "langchain-openai==0.3.23",
# "pandas==2.3.0",
# "parsel==1.10.0",
# "praw==7.8.1",
# "pytz==2025.2",
# "questionary==2.1.0",
# "redis==6.2.0",
# "requests==2.32.4",
# "stockstats==0.6.5",
# "tqdm==4.67.1",
# "tushare==1.4.21",
# "typing-extensions==4.14.0",
# "yfinance==0.2.63",
# ]
# main = "main"
# params = ""
# ///
import asyncio
from copy import deepcopy
import agents
import agents.analysts
from agents.managers import create_research_manager, create_risk_manager
from agents.researchers import create_bear_researcher, create_bull_researcher
from agents.risk_debators import (
create_neutral_debator,
create_risky_debator,
create_safe_debator,
)
from agents.trader import create_trader
from agents.utils.utils import AgentState
from flyte_env import DEEP_THINKING_LLM, QUICK_THINKING_LLM, env, flyte
from langchain_openai import ChatOpenAI
from reflection import (
reflect_bear_researcher,
reflect_bull_researcher,
reflect_research_manager,
reflect_risk_manager,
reflect_trader,
)
@env.task
async def process_signal(full_signal: str, QUICK_THINKING_LLM: str) -> str:
"""Process a full trading signal to extract the core decision."""
messages = [
{
"role": "system",
"content": """You are an efficient assistant designed to analyze paragraphs or
financial reports provided by a group of analysts.
Your task is to extract the investment decision: SELL, BUY, or HOLD.
Provide only the extracted decision (SELL, BUY, or HOLD) as your output,
without adding any additional text or information.""",
},
{"role": "human", "content": full_signal},
]
return ChatOpenAI(model=QUICK_THINKING_LLM).invoke(messages).content
async def run_analyst(analyst_name, state, online_tools):
# Create a copy of the state for isolation
run_fn = getattr(agents.analysts, f"create_{analyst_name}_analyst")
# Run the analyst's chain
result_state = await run_fn(QUICK_THINKING_LLM, state, online_tools)
# Determine the report key
report_key = (
"sentiment_report"
if analyst_name == "social_media"
else f"{analyst_name}_report"
)
report_value = getattr(result_state, report_key)
return result_state.messages[1:], report_key, report_value
# {{docs-fragment main}}
@env.task
async def main(
selected_analysts: list[str] = [
"market",
"fundamentals",
"news",
"social_media",
],
max_debate_rounds: int = 1,
max_risk_discuss_rounds: int = 1,
online_tools: bool = True,
company_name: str = "NVDA",
trade_date: str = "2024-05-12",
) -> tuple[str, AgentState]:
if not selected_analysts:
raise ValueError(
"No analysts selected. Please select at least one analyst from market, fundamentals, news, or social_media."
)
state = AgentState(
messages=[{"role": "human", "content": company_name}],
company_of_interest=company_name,
trade_date=str(trade_date),
)
# Run all analysts concurrently
results = await asyncio.gather(
*[
run_analyst(analyst, deepcopy(state), online_tools)
for analyst in selected_analysts
]
)
# Flatten and append all resulting messages into the shared state
for messages, report_attr, report in results:
state.messages.extend(messages)
setattr(state, report_attr, report)
# Bull/Bear debate loop
state = await create_bull_researcher(QUICK_THINKING_LLM, state) # Start with bull
while state.investment_debate_state.count < 2 * max_debate_rounds:
current = state.investment_debate_state.current_response
if current.startswith("Bull"):
state = await create_bear_researcher(QUICK_THINKING_LLM, state)
else:
state = await create_bull_researcher(QUICK_THINKING_LLM, state)
state = await create_research_manager(DEEP_THINKING_LLM, state)
state = await create_trader(QUICK_THINKING_LLM, state)
# Risk debate loop
state = await create_risky_debator(QUICK_THINKING_LLM, state) # Start with risky
while state.risk_debate_state.count < 3 * max_risk_discuss_rounds:
speaker = state.risk_debate_state.latest_speaker
if speaker == "Risky":
state = await create_safe_debator(QUICK_THINKING_LLM, state)
elif speaker == "Safe":
state = await create_neutral_debator(QUICK_THINKING_LLM, state)
else:
state = await create_risky_debator(QUICK_THINKING_LLM, state)
state = await create_risk_manager(DEEP_THINKING_LLM, state)
decision = await process_signal(state.final_trade_decision, QUICK_THINKING_LLM)
return decision, state
# {{/docs-fragment main}}
# {{docs-fragment reflect_on_decisions}}
@env.task
async def reflect_and_store(state: AgentState, returns: str) -> str:
await asyncio.gather(
reflect_bear_researcher(state, returns),
reflect_bull_researcher(state, returns),
reflect_trader(state, returns),
reflect_risk_manager(state, returns),
reflect_research_manager(state, returns),
)
return "Reflection completed."
# Run the reflection task after the main function
@env.task(cache="disable")
async def reflect_on_decisions(
returns: str,
selected_analysts: list[str] = [
"market",
"fundamentals",
"news",
"social_media",
],
max_debate_rounds: int = 1,
max_risk_discuss_rounds: int = 1,
online_tools: bool = True,
company_name: str = "NVDA",
trade_date: str = "2024-05-12",
) -> str:
_, state = await main(
selected_analysts,
max_debate_rounds,
max_risk_discuss_rounds,
online_tools,
company_name,
trade_date,
)
return await reflect_and_store(state, returns)
# {{/docs-fragment reflect_on_decisions}}
# {{docs-fragment execute_main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(main)
print(run.url)
run.wait()
# run = flyte.run(reflect_on_decisions, "+3.2% gain over 5 days")
# print(run.url)
# {{/docs-fragment execute_main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/trading_agents/main.py*
Then run:
```
uv run main.py
```
## Why Flyte? _(A quick note before you go)_
You might now be wondering: can't I just build all this with Python and LangChain?
Absolutely. But as your project grows, you'll likely run into these challenges:
1. **Observability**: Agent workflows can feel opaque. You send a prompt, get a response, but what happened in between?
- Were the right tools used?
- Were correct arguments passed?
- How did the LLM reason through intermediate steps?
- Why did it fail?
Flyte gives you a window into each of these stages.
2. **Multi-agent coordination**: Real-world applications often require multiple agents with distinct roles and responsibilities. In such cases, you'll need:
- Isolated state per agent,
- Shared context where needed,
- And coordination — sequential or parallel.
Managing this manually gets fragile, fast. Flyte handles it for you.
3. **Scalability**: Agents and tools might need to run in isolated or containerized environments. Whether you're scaling out to more agents or more powerful hardware, Flyte lets you scale without taxing your local machine or racking up unnecessary cloud bills.
4. **Durability & recovery**: LLM-based workflows are often long-running and expensive. If something fails halfway:
- Do you lose all progress?
- Replay everything from scratch?
With Flyte, you get built-in caching, checkpointing, and recovery, so you can resume where you left off.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/financial-services/fraud-detection-feast ===
# Fraud detection with Feast
> [!NOTE]
> Code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/fraud_detection_feast).
This tutorial builds a credit-card fraud detection pipeline that combines [Feast](https://feast.dev/) feature store materialization with an XGBoost classifier on the Sparkov simulated transactions dataset. The workflow engineers transaction and user-level features, trains a model, registers features in Feast, and materializes online feature values for low-latency scoring.
Flyte provides:
- **Cached data preparation** for the Kaggle dataset download and feature engineering.
- **Report-backed training** with confusion matrix and ROC-style metrics in the UI.
- **Durable artifacts** — the trained model and Feast repo are returned as `flyte.io.File` and `flyte.io.Dir`.
## Define the task environment
```
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flyte>=2.4.0",
# "feast==0.63.0",
# "scikit-learn==1.8.0",
# "xgboost==3.2.0",
# "joblib",
# "pandas",
# "pyarrow",
# "kagglehub==0.3.12",
# ]
# main = "fraud_detection_pipeline"
# params = ""
# ///
import json
import logging
import math
import os
import shutil
import tempfile
from datetime import datetime, timedelta, timezone
import joblib
import numpy as np
import pandas as pd
import flyte
import flyte.io
import flyte.report
# {{docs-fragment env}}
main_img = flyte.Image.from_uv_script(__file__, name="fraud-detection-feast", pre=True)
env = flyte.TaskEnvironment(
name="fraud-detection-feast",
image=main_img,
resources=flyte.Resources(cpu=2, memory="4Gi"),
)
# {{/docs-fragment env}}
import report_helpers as rh
logging.basicConfig(level=logging.WARNING, format="%(message)s", force=True)
log = logging.getLogger(__name__)
log.setLevel(logging.INFO)
# ------------------------------------------------------------------
# Feature definitions
#
# Transaction features: known at scoring time (from the request)
# User features: pre-computed aggregates stored in Feast
# Derived features: computed at both training and scoring time by
# comparing the transaction to the user's profile
# ------------------------------------------------------------------
TXN_FEATURE_COLS = ["amt", "amt_log", "category_encoded", "merch_lat", "merch_long"]
USER_FEATURE_COLS = [
"txn_count", "mean_amt", "std_amt", "max_amt",
"home_lat", "home_long", "age",
]
DERIVED_FEATURE_COLS = [
"amt_zscore", "amt_ratio", "distance_from_home", "hour", "day_of_week",
]
ALL_FEATURE_COLS = TXN_FEATURE_COLS + USER_FEATURE_COLS + DERIVED_FEATURE_COLS
def haversine(lat1, lon1, lat2, lon2):
"""Compute distance in miles between two (lat, lon) points."""
R = 3959 # Earth radius in miles
lat1, lon1, lat2, lon2 = map(np.radians, [lat1, lon1, lat2, lon2])
dlat = lat2 - lat1
dlon = lon2 - lon1
a = np.sin(dlat / 2) ** 2 + np.cos(lat1) * np.cos(lat2) * np.sin(dlon / 2) ** 2
return 2 * R * np.arcsin(np.sqrt(a))
# ------------------------------------------------------------------
# Task 1: Download dataset and engineer features
# ------------------------------------------------------------------
@env.task(report=True, cache="auto")
async def prepare_data() -> flyte.io.Dir:
"""Download the Sparkov credit card fraud dataset and prepare parquets."""
import kagglehub
log.info("Downloading dataset...")
dataset_path = kagglehub.dataset_download("kartik2112/fraud-detection")
csv_path = os.path.join(dataset_path, "fraudTrain.csv")
df = pd.read_csv(csv_path)
log.info(f"Loaded {len(df):,} transactions ({int(df['is_fraud'].sum()):,} fraudulent)")
# Sample for workshop speed (stratified to preserve fraud ratio)
if len(df) > 500_000:
from sklearn.model_selection import train_test_split
df, _ = train_test_split(df, train_size=500_000, stratify=df["is_fraud"], random_state=42)
log.info(f"Sampled to {len(df):,} transactions")
# ------------------------------------------------------------------
# Parse timestamps
# ------------------------------------------------------------------
df["event_timestamp"] = pd.to_datetime(df["trans_date_trans_time"])
df["event_timestamp"] = df["event_timestamp"].dt.tz_localize("UTC")
df["hour"] = df["event_timestamp"].dt.hour
df["day_of_week"] = df["event_timestamp"].dt.dayofweek
# ------------------------------------------------------------------
# Map cc_num → sequential user_id for clean API
# ------------------------------------------------------------------
cc_nums = df["cc_num"].unique()
cc_to_user = {cc: i for i, cc in enumerate(sorted(cc_nums))}
df["user_id"] = df["cc_num"].map(cc_to_user)
# ------------------------------------------------------------------
# Feature engineering
# ------------------------------------------------------------------
df["amt_log"] = np.log1p(df["amt"])
# Label-encode merchant category
categories = sorted(df["category"].unique())
cat_to_int = {cat: i for i, cat in enumerate(categories)}
df["category_encoded"] = df["category"].map(cat_to_int)
# Compute age from dob
df["dob"] = pd.to_datetime(df["dob"]).dt.tz_localize("UTC")
ref_date = df["event_timestamp"].max()
df["age"] = ((ref_date - df["dob"]).dt.days / 365.25).astype(int)
# Distance between buyer and merchant
df["distance"] = haversine(df["lat"], df["long"], df["merch_lat"], df["merch_long"])
# ------------------------------------------------------------------
# Build user aggregates
# ------------------------------------------------------------------
user_stats = df.groupby("user_id").agg(
txn_count=("amt", "count"),
mean_amt=("amt", "mean"),
std_amt=("amt", "std"),
max_amt=("amt", "max"),
home_lat=("lat", "median"),
home_long=("long", "median"),
age=("age", "first"),
).reset_index()
user_stats["std_amt"] = user_stats["std_amt"].fillna(0)
# Use earliest timestamp so Feast point-in-time joins work for all transactions
earliest_ts = df.groupby("user_id")["event_timestamp"].min().reset_index()
user_stats = user_stats.merge(earliest_ts, on="user_id")
# ------------------------------------------------------------------
# Save to temp directory
# ------------------------------------------------------------------
data_dir = tempfile.mkdtemp()
txn_cols = [
"user_id", "event_timestamp",
"amt", "amt_log", "category_encoded", "merch_lat", "merch_long",
"hour", "day_of_week", "lat", "long", "distance",
"is_fraud",
]
df[txn_cols].to_parquet(os.path.join(data_dir, "transactions.parquet"), index=False)
user_stats.to_parquet(os.path.join(data_dir, "user_features.parquet"), index=False)
# Save category mapping + cc_num mapping for the app
with open(os.path.join(data_dir, "category_mapping.json"), "w") as f:
json.dump(cat_to_int, f)
with open(os.path.join(data_dir, "user_mapping.json"), "w") as f:
json.dump({str(k): v for k, v in cc_to_user.items()}, f)
n_fraud = int(df["is_fraud"].sum())
n_legit = len(df) - n_fraud
fraud_pct = df["is_fraud"].mean() * 100
html = (
'
Data Prepared
'
+ rh.stat_grid([
(f"{len(df):,}", "Transactions"),
(f"{n_fraud:,}", "Fraudulent"),
(f"{fraud_pct:.2f}%", "Fraud Rate"),
(f"{user_stats['user_id'].nunique():,}", "Users"),
(f"{len(categories)}", "Categories"),
])
+ rh.class_distribution_bar(n_legit, n_fraud)
)
await flyte.report.replace.aio(rh.wrap(html))
await flyte.report.flush.aio()
return await flyte.io.Dir.from_local(data_dir)
# ------------------------------------------------------------------
# Task 2: Set up Feast and materialize user profiles to online store
# ------------------------------------------------------------------
@env.task(report=True)
async def materialize_features(data_dir: flyte.io.Dir) -> flyte.io.Dir:
"""Apply Feast definitions and materialize user profiles to SQLite online store."""
from feast import Entity, FeatureStore, FeatureView, Field, FileSource
from feast.types import Float64, Int64
data_path = await data_dir.download()
# Create a self-contained Feast repo in a temp directory
feast_dir = tempfile.mkdtemp()
# Copy parquet into feast dir so the repo is fully self-contained
shutil.copy2(
os.path.join(data_path, "user_features.parquet"),
os.path.join(feast_dir, "user_features.parquet"),
)
# Write feature_store.yaml
yaml_content = (
"project: fraud_detection\n"
f"registry: {feast_dir}/registry.db\n"
"provider: local\n"
"online_store:\n"
" type: sqlite\n"
f" path: {feast_dir}/online_store.db\n"
"offline_store:\n"
" type: file\n"
"entity_key_serialization_version: 3\n"
)
yaml_path = os.path.join(feast_dir, "feature_store.yaml")
with open(yaml_path, "w") as f:
f.write(yaml_content)
store = FeatureStore(repo_path=feast_dir)
# Define entity and feature view
user = Entity(name="user", join_keys=["user_id"], description="Credit card holder")
user_source = FileSource(
path=os.path.join(feast_dir, "user_features.parquet"),
timestamp_field="event_timestamp",
)
user_stats = FeatureView(
name="user_stats",
entities=[user],
ttl=timedelta(days=0), # No expiry — workshop data has old timestamps
schema=[
Field(name="txn_count", dtype=Int64),
Field(name="mean_amt", dtype=Float64),
Field(name="std_amt", dtype=Float64),
Field(name="max_amt", dtype=Float64),
Field(name="home_lat", dtype=Float64),
Field(name="home_long", dtype=Float64),
Field(name="age", dtype=Int64),
],
online=True,
source=user_source,
)
# Apply and materialize
log.info("Applying Feast definitions...")
store.apply([user, user_stats])
log.info("Materializing user profiles to online store...")
store.materialize(
start_date=datetime(2018, 1, 1, tzinfo=timezone.utc),
end_date=datetime.now(timezone.utc),
)
# Re-apply with relative paths so the registry is portable across workers
portable_yaml = (
"project: fraud_detection\n"
"registry: registry.db\n"
"provider: local\n"
"online_store:\n"
" type: sqlite\n"
" path: online_store.db\n"
"offline_store:\n"
" type: file\n"
"entity_key_serialization_version: 3\n"
)
with open(yaml_path, "w") as f:
f.write(portable_yaml)
# Re-apply with relative source path so get_historical_features works on other workers
store = FeatureStore(repo_path=feast_dir)
user_source = FileSource(
path="user_features.parquet",
timestamp_field="event_timestamp",
)
user_stats = FeatureView(
name="user_stats",
entities=[user],
ttl=timedelta(days=0),
schema=[
Field(name="txn_count", dtype=Int64),
Field(name="mean_amt", dtype=Float64),
Field(name="std_amt", dtype=Float64),
Field(name="max_amt", dtype=Float64),
Field(name="home_lat", dtype=Float64),
Field(name="home_long", dtype=Float64),
Field(name="age", dtype=Int64),
],
online=True,
source=user_source,
)
store.apply([user, user_stats])
features = ["txn_count", "mean_amt", "std_amt", "max_amt", "home_lat", "home_long", "age"]
html = (
'
' + rh.pipeline_step_indicator(1, steps)
await flyte.report.replace.aio(rh.wrap(html))
await flyte.report.flush.aio()
# Materialize features first so training can use Feast
feast_dir = await materialize_features(data_dir)
html = '
Fraud Detection Pipeline
' + rh.pipeline_step_indicator(2, steps)
await flyte.report.replace.aio(rh.wrap(html))
await flyte.report.flush.aio()
# Train model using Feast for user feature retrieval
model_file = await train_model(
data_dir,
feast_dir,
n_estimators=n_estimators,
max_depth=max_depth,
learning_rate=learning_rate,
min_child_weight=min_child_weight,
gamma=gamma,
)
# Save copies to working directory for local app testing
model_local = await model_file.download()
feast_local = await feast_dir.download()
shutil.copy2(model_local, "model.joblib")
if os.path.exists("feast_artifacts"):
shutil.rmtree("feast_artifacts")
shutil.copytree(feast_local, "feast_artifacts")
log.info("Saved local copies: model.joblib, feast_artifacts/")
html = (
'
Fraud Detection Pipeline
'
+ rh.pipeline_step_indicator(4, steps)
+ '
'
'
Pipeline Complete
'
'
Model and feature store artifacts are ready for serving.
'
'
'
'
Next Step
Command
'
'
Run locally
python app.py
'
'
Deploy scoring app
flyte deploy app.py serving_env
'
'
Deploy dashboard
flyte deploy dashboard.py dashboard_env
'
'
'
)
await flyte.report.replace.aio(rh.wrap(html))
await flyte.report.flush.aio()
log.info("Pipeline complete")
return model_file, feast_dir
# {{/docs-fragment pipeline}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(fraud_detection_pipeline)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/fraud_detection_feast/fraud_detection_feast.py*
```
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flyte>=2.4.0",
# "feast==0.63.0",
# "xgboost==3.2.0",
# "scikit-learn==1.8.0",
# "kagglehub==0.3.12",
# ...
# ]
# ///
```
## Orchestrate the pipeline
The `fraud_detection_pipeline` task downloads data, trains XGBoost, applies Feast feature definitions, and materializes features.
```
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "flyte>=2.4.0",
# "feast==0.63.0",
# "scikit-learn==1.8.0",
# "xgboost==3.2.0",
# "joblib",
# "pandas",
# "pyarrow",
# "kagglehub==0.3.12",
# ]
# main = "fraud_detection_pipeline"
# params = ""
# ///
import json
import logging
import math
import os
import shutil
import tempfile
from datetime import datetime, timedelta, timezone
import joblib
import numpy as np
import pandas as pd
import flyte
import flyte.io
import flyte.report
# {{docs-fragment env}}
main_img = flyte.Image.from_uv_script(__file__, name="fraud-detection-feast", pre=True)
env = flyte.TaskEnvironment(
name="fraud-detection-feast",
image=main_img,
resources=flyte.Resources(cpu=2, memory="4Gi"),
)
# {{/docs-fragment env}}
import report_helpers as rh
logging.basicConfig(level=logging.WARNING, format="%(message)s", force=True)
log = logging.getLogger(__name__)
log.setLevel(logging.INFO)
# ------------------------------------------------------------------
# Feature definitions
#
# Transaction features: known at scoring time (from the request)
# User features: pre-computed aggregates stored in Feast
# Derived features: computed at both training and scoring time by
# comparing the transaction to the user's profile
# ------------------------------------------------------------------
TXN_FEATURE_COLS = ["amt", "amt_log", "category_encoded", "merch_lat", "merch_long"]
USER_FEATURE_COLS = [
"txn_count", "mean_amt", "std_amt", "max_amt",
"home_lat", "home_long", "age",
]
DERIVED_FEATURE_COLS = [
"amt_zscore", "amt_ratio", "distance_from_home", "hour", "day_of_week",
]
ALL_FEATURE_COLS = TXN_FEATURE_COLS + USER_FEATURE_COLS + DERIVED_FEATURE_COLS
def haversine(lat1, lon1, lat2, lon2):
"""Compute distance in miles between two (lat, lon) points."""
R = 3959 # Earth radius in miles
lat1, lon1, lat2, lon2 = map(np.radians, [lat1, lon1, lat2, lon2])
dlat = lat2 - lat1
dlon = lon2 - lon1
a = np.sin(dlat / 2) ** 2 + np.cos(lat1) * np.cos(lat2) * np.sin(dlon / 2) ** 2
return 2 * R * np.arcsin(np.sqrt(a))
# ------------------------------------------------------------------
# Task 1: Download dataset and engineer features
# ------------------------------------------------------------------
@env.task(report=True, cache="auto")
async def prepare_data() -> flyte.io.Dir:
"""Download the Sparkov credit card fraud dataset and prepare parquets."""
import kagglehub
log.info("Downloading dataset...")
dataset_path = kagglehub.dataset_download("kartik2112/fraud-detection")
csv_path = os.path.join(dataset_path, "fraudTrain.csv")
df = pd.read_csv(csv_path)
log.info(f"Loaded {len(df):,} transactions ({int(df['is_fraud'].sum()):,} fraudulent)")
# Sample for workshop speed (stratified to preserve fraud ratio)
if len(df) > 500_000:
from sklearn.model_selection import train_test_split
df, _ = train_test_split(df, train_size=500_000, stratify=df["is_fraud"], random_state=42)
log.info(f"Sampled to {len(df):,} transactions")
# ------------------------------------------------------------------
# Parse timestamps
# ------------------------------------------------------------------
df["event_timestamp"] = pd.to_datetime(df["trans_date_trans_time"])
df["event_timestamp"] = df["event_timestamp"].dt.tz_localize("UTC")
df["hour"] = df["event_timestamp"].dt.hour
df["day_of_week"] = df["event_timestamp"].dt.dayofweek
# ------------------------------------------------------------------
# Map cc_num → sequential user_id for clean API
# ------------------------------------------------------------------
cc_nums = df["cc_num"].unique()
cc_to_user = {cc: i for i, cc in enumerate(sorted(cc_nums))}
df["user_id"] = df["cc_num"].map(cc_to_user)
# ------------------------------------------------------------------
# Feature engineering
# ------------------------------------------------------------------
df["amt_log"] = np.log1p(df["amt"])
# Label-encode merchant category
categories = sorted(df["category"].unique())
cat_to_int = {cat: i for i, cat in enumerate(categories)}
df["category_encoded"] = df["category"].map(cat_to_int)
# Compute age from dob
df["dob"] = pd.to_datetime(df["dob"]).dt.tz_localize("UTC")
ref_date = df["event_timestamp"].max()
df["age"] = ((ref_date - df["dob"]).dt.days / 365.25).astype(int)
# Distance between buyer and merchant
df["distance"] = haversine(df["lat"], df["long"], df["merch_lat"], df["merch_long"])
# ------------------------------------------------------------------
# Build user aggregates
# ------------------------------------------------------------------
user_stats = df.groupby("user_id").agg(
txn_count=("amt", "count"),
mean_amt=("amt", "mean"),
std_amt=("amt", "std"),
max_amt=("amt", "max"),
home_lat=("lat", "median"),
home_long=("long", "median"),
age=("age", "first"),
).reset_index()
user_stats["std_amt"] = user_stats["std_amt"].fillna(0)
# Use earliest timestamp so Feast point-in-time joins work for all transactions
earliest_ts = df.groupby("user_id")["event_timestamp"].min().reset_index()
user_stats = user_stats.merge(earliest_ts, on="user_id")
# ------------------------------------------------------------------
# Save to temp directory
# ------------------------------------------------------------------
data_dir = tempfile.mkdtemp()
txn_cols = [
"user_id", "event_timestamp",
"amt", "amt_log", "category_encoded", "merch_lat", "merch_long",
"hour", "day_of_week", "lat", "long", "distance",
"is_fraud",
]
df[txn_cols].to_parquet(os.path.join(data_dir, "transactions.parquet"), index=False)
user_stats.to_parquet(os.path.join(data_dir, "user_features.parquet"), index=False)
# Save category mapping + cc_num mapping for the app
with open(os.path.join(data_dir, "category_mapping.json"), "w") as f:
json.dump(cat_to_int, f)
with open(os.path.join(data_dir, "user_mapping.json"), "w") as f:
json.dump({str(k): v for k, v in cc_to_user.items()}, f)
n_fraud = int(df["is_fraud"].sum())
n_legit = len(df) - n_fraud
fraud_pct = df["is_fraud"].mean() * 100
html = (
'
Data Prepared
'
+ rh.stat_grid([
(f"{len(df):,}", "Transactions"),
(f"{n_fraud:,}", "Fraudulent"),
(f"{fraud_pct:.2f}%", "Fraud Rate"),
(f"{user_stats['user_id'].nunique():,}", "Users"),
(f"{len(categories)}", "Categories"),
])
+ rh.class_distribution_bar(n_legit, n_fraud)
)
await flyte.report.replace.aio(rh.wrap(html))
await flyte.report.flush.aio()
return await flyte.io.Dir.from_local(data_dir)
# ------------------------------------------------------------------
# Task 2: Set up Feast and materialize user profiles to online store
# ------------------------------------------------------------------
@env.task(report=True)
async def materialize_features(data_dir: flyte.io.Dir) -> flyte.io.Dir:
"""Apply Feast definitions and materialize user profiles to SQLite online store."""
from feast import Entity, FeatureStore, FeatureView, Field, FileSource
from feast.types import Float64, Int64
data_path = await data_dir.download()
# Create a self-contained Feast repo in a temp directory
feast_dir = tempfile.mkdtemp()
# Copy parquet into feast dir so the repo is fully self-contained
shutil.copy2(
os.path.join(data_path, "user_features.parquet"),
os.path.join(feast_dir, "user_features.parquet"),
)
# Write feature_store.yaml
yaml_content = (
"project: fraud_detection\n"
f"registry: {feast_dir}/registry.db\n"
"provider: local\n"
"online_store:\n"
" type: sqlite\n"
f" path: {feast_dir}/online_store.db\n"
"offline_store:\n"
" type: file\n"
"entity_key_serialization_version: 3\n"
)
yaml_path = os.path.join(feast_dir, "feature_store.yaml")
with open(yaml_path, "w") as f:
f.write(yaml_content)
store = FeatureStore(repo_path=feast_dir)
# Define entity and feature view
user = Entity(name="user", join_keys=["user_id"], description="Credit card holder")
user_source = FileSource(
path=os.path.join(feast_dir, "user_features.parquet"),
timestamp_field="event_timestamp",
)
user_stats = FeatureView(
name="user_stats",
entities=[user],
ttl=timedelta(days=0), # No expiry — workshop data has old timestamps
schema=[
Field(name="txn_count", dtype=Int64),
Field(name="mean_amt", dtype=Float64),
Field(name="std_amt", dtype=Float64),
Field(name="max_amt", dtype=Float64),
Field(name="home_lat", dtype=Float64),
Field(name="home_long", dtype=Float64),
Field(name="age", dtype=Int64),
],
online=True,
source=user_source,
)
# Apply and materialize
log.info("Applying Feast definitions...")
store.apply([user, user_stats])
log.info("Materializing user profiles to online store...")
store.materialize(
start_date=datetime(2018, 1, 1, tzinfo=timezone.utc),
end_date=datetime.now(timezone.utc),
)
# Re-apply with relative paths so the registry is portable across workers
portable_yaml = (
"project: fraud_detection\n"
"registry: registry.db\n"
"provider: local\n"
"online_store:\n"
" type: sqlite\n"
" path: online_store.db\n"
"offline_store:\n"
" type: file\n"
"entity_key_serialization_version: 3\n"
)
with open(yaml_path, "w") as f:
f.write(portable_yaml)
# Re-apply with relative source path so get_historical_features works on other workers
store = FeatureStore(repo_path=feast_dir)
user_source = FileSource(
path="user_features.parquet",
timestamp_field="event_timestamp",
)
user_stats = FeatureView(
name="user_stats",
entities=[user],
ttl=timedelta(days=0),
schema=[
Field(name="txn_count", dtype=Int64),
Field(name="mean_amt", dtype=Float64),
Field(name="std_amt", dtype=Float64),
Field(name="max_amt", dtype=Float64),
Field(name="home_lat", dtype=Float64),
Field(name="home_long", dtype=Float64),
Field(name="age", dtype=Int64),
],
online=True,
source=user_source,
)
store.apply([user, user_stats])
features = ["txn_count", "mean_amt", "std_amt", "max_amt", "home_lat", "home_long", "age"]
html = (
'
' + rh.pipeline_step_indicator(1, steps)
await flyte.report.replace.aio(rh.wrap(html))
await flyte.report.flush.aio()
# Materialize features first so training can use Feast
feast_dir = await materialize_features(data_dir)
html = '
Fraud Detection Pipeline
' + rh.pipeline_step_indicator(2, steps)
await flyte.report.replace.aio(rh.wrap(html))
await flyte.report.flush.aio()
# Train model using Feast for user feature retrieval
model_file = await train_model(
data_dir,
feast_dir,
n_estimators=n_estimators,
max_depth=max_depth,
learning_rate=learning_rate,
min_child_weight=min_child_weight,
gamma=gamma,
)
# Save copies to working directory for local app testing
model_local = await model_file.download()
feast_local = await feast_dir.download()
shutil.copy2(model_local, "model.joblib")
if os.path.exists("feast_artifacts"):
shutil.rmtree("feast_artifacts")
shutil.copytree(feast_local, "feast_artifacts")
log.info("Saved local copies: model.joblib, feast_artifacts/")
html = (
'
Fraud Detection Pipeline
'
+ rh.pipeline_step_indicator(4, steps)
+ '
'
'
Pipeline Complete
'
'
Model and feature store artifacts are ready for serving.
'
'
'
'
Next Step
Command
'
'
Run locally
python app.py
'
'
Deploy scoring app
flyte deploy app.py serving_env
'
'
Deploy dashboard
flyte deploy dashboard.py dashboard_env
'
'
'
)
await flyte.report.replace.aio(rh.wrap(html))
await flyte.report.flush.aio()
log.info("Pipeline complete")
return model_file, feast_dir
# {{/docs-fragment pipeline}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(fraud_detection_pipeline)
print(run.url)
run.wait()
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/fraud_detection_feast/fraud_detection_feast.py*
## Run the workflow
From the [example directory](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/fraud_detection_feast):
```
cd v2/tutorials/fraud_detection_feast
uv run --script fraud_detection_feast.py
```
The first run downloads the dataset via `kagglehub` (public dataset, no API key required). Open the run report to review the confusion matrix and feature-importance summary when training completes.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/financial-services/financial-research-agent ===
# Financial research agent
> [!NOTE]
> Code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/financial_research_agent).
This example demonstrates how to build a financial research and earnings-cycle agent on Flyte. For each company, the agent runs grounded, source-cited research and fresh news, then synthesizes an analyst-ready equity briefing.
Financial research benefits from **low-latency, ranked, source-cited results** across both the general web and news streams. The [You.com Research API](https://you.com/docs/research/overview) produces a grounded, citation-backed synthesis, and the [You.com Search API](https://you.com/docs/search/overview) adds a fresh-news layer. [Claude](https://docs.anthropic.com/) via [LiteLLM](https://docs.litellm.ai/) turns that evidence into an analyst-ready briefing. Flyte's `cache="auto"` reuses prior results when runs converge on the same companies.
Flyte provides:
- **Fan-out parallelism** across companies
- **`cache="auto"`** to reuse prior You.com and LLM results across converging runs
- **`@flyte.trace`** on every external call for full prompt → citation lineage
- **Flyte reports** with thesis, risks, watch items, and source citations per company
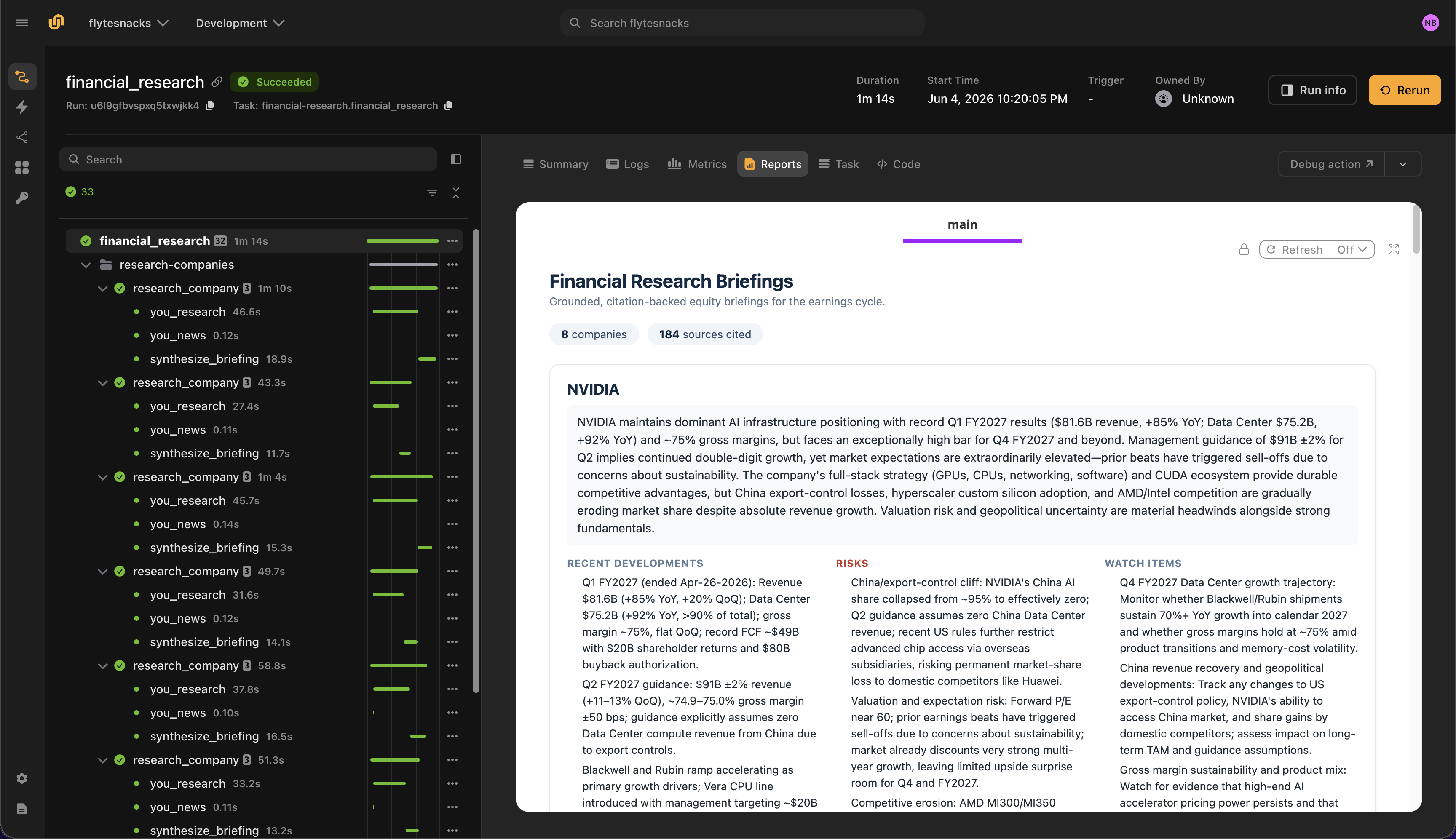
## Setting up the environment
The agent runs in a `TaskEnvironment` with secrets for the You.com and Anthropic API keys, automatic caching, and a container image built from the `uv` script dependencies.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# main = "financial_research"
# params = ""
# ///
"""Financial research & earnings-cycle agent.
For each company, runs grounded, source-cited research via the You.com Research
API plus a fresh-news layer via the Search API, then uses Claude to synthesize
an analyst-ready equity briefing that preserves citations. Flyte caching cuts
duplicate spend when runs converge.
"""
# {{docs-fragment env}}
import asyncio
import json
import os
from dataclasses import dataclass, field
import flyte
MODEL = "anthropic/claude-haiku-4-5"
env = flyte.TaskEnvironment(
name="financial-research",
secrets=[
flyte.Secret(key="youdotcom-api-key", as_env_var="YOU_API_KEY"),
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
image=flyte.Image.from_uv_script(__file__, name="financial-research", pre=True),
resources=flyte.Resources(cpu="1", memory="1Gi"),
cache="auto",
)
# {{/docs-fragment env}}
# {{docs-fragment data_types}}
@dataclass
class Source:
title: str
url: str
domain: str = ""
snippet: str = ""
published: str = ""
favicon: str = ""
section: str = "research" # "research", "news", or "web"
def _domain(url: str) -> str:
from urllib.parse import urlparse
try:
return urlparse(url).netloc.replace("www.", "")
except Exception:
return ""
def _favicon_for(url: str) -> str:
return f"https://ydc-index.io/favicon?domain={_domain(url)}&size=128"
@dataclass
class Briefing:
company: str
thesis: str
recent_developments: list[str] = field(default_factory=list)
risks: list[str] = field(default_factory=list)
watch_items: list[str] = field(default_factory=list)
sources: list[Source] = field(default_factory=list)
@dataclass
class ResearchReport:
briefings: list[Briefing] = field(default_factory=list)
# {{/docs-fragment data_types}}
# {{docs-fragment you_apis}}
YOU_RESEARCH_URL = "https://api.you.com/v1/research"
YOU_SEARCH_URL = "https://ydc-index.io/v1/search"
async def _you_request(method: str, url: str, timeout: float, **kwargs) -> dict:
"""HTTP wrapper with exponential backoff + jitter on 429 rate limits.
Fanned-out tasks run in separate pods, so we retry on the client side to
smooth out bursts against the You.com API rate limit.
"""
import asyncio
import random
import httpx
headers = {"X-API-Key": os.environ["YOU_API_KEY"]}
if method == "POST":
headers["Content-Type"] = "application/json"
async with httpx.AsyncClient(timeout=timeout) as client:
for attempt in range(7):
resp = await client.request(method, url, headers=headers, **kwargs)
if resp.status_code == 429 and attempt < 6:
wait = float(resp.headers.get("retry-after") or 0) or min(2**attempt, 30)
await asyncio.sleep(wait + random.uniform(0, 2))
continue
resp.raise_for_status()
return resp.json()
resp.raise_for_status()
return resp.json()
@flyte.trace
async def you_research(question: str, research_effort: str, freshness: str) -> dict:
"""Grounded, citation-backed research answer."""
body = {
"input": question,
"research_effort": research_effort,
"source_control": {"freshness": freshness},
}
return await _you_request("POST", YOU_RESEARCH_URL, 300.0, json=body)
@flyte.trace
async def you_news(query: str, count: int = 6, freshness: str = "week") -> list[dict]:
"""Fresh news headlines for a company."""
params = {"query": query, "count": count, "freshness": freshness}
data = await _you_request("GET", YOU_SEARCH_URL, 60.0, params=params)
results = data.get("results", {})
out: list[dict] = []
for section in ("news", "web"):
for item in results.get(section, []) or []:
snippets = item.get("snippets") or []
url = item.get("url", "")
out.append(
{
"title": item.get("title", ""),
"url": url,
"domain": _domain(url),
"snippet": snippets[0] if snippets else item.get("description", ""),
"published": item.get("page_age", "") or "",
"favicon": item.get("favicon_url")
or _favicon_for(url),
"section": section,
}
)
return out
# {{/docs-fragment you_apis}}
# {{docs-fragment llm}}
@flyte.trace
async def synthesize_briefing(company: str, focus: str, research: str, news: str) -> dict:
"""Use Claude to synthesize a structured equity briefing."""
from litellm import acompletion
system = (
"You are an equity research analyst. Using ONLY the grounded research "
"and news provided, write a concise briefing. Respond ONLY with JSON: "
'{"thesis": str, "recent_developments": [str], "risks": [str], '
'"watch_items": [str]}. Keep each list to 3-5 short, specific bullets.'
)
user = (
f"Company: {company}\nFocus: {focus}\n\n"
f"Grounded research:\n{research}\n\nRecent news:\n{news}"
)
resp = await acompletion(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
temperature=0.0,
max_tokens=1536,
)
parsed = _parse_json(resp.choices[0].message.content)
return parsed if isinstance(parsed, dict) else {}
def _parse_json(text: str) -> dict | list:
text = text.strip()
if text.startswith("```"):
text = text.split("```", 2)[1]
if text.lstrip().startswith("json"):
text = text.lstrip()[4:]
start = min((i for i in (text.find("{"), text.find("[")) if i != -1), default=0)
end = max(text.rfind("}"), text.rfind("]")) + 1
return json.loads(text[start:end])
# {{/docs-fragment llm}}
# {{docs-fragment research_company}}
@env.task(retries=3)
async def research_company(
company: str,
focus: str,
research_effort: str,
freshness: str,
) -> Briefing:
"""Research one company and synthesize a cited briefing."""
question = (
f"Provide a grounded analysis of {company} with respect to: {focus}. "
f"Cover recent financial performance, strategic moves, competitive "
f"positioning, and risks."
)
research_result, news = await asyncio.gather(
you_research(question, research_effort, freshness),
you_news(f"{company} earnings news", freshness=freshness),
)
output = research_result.get("output", {})
research_text = output.get("content", "")
if not isinstance(research_text, str):
research_text = json.dumps(research_text)
sources: list[Source] = []
for s in output.get("sources", []) or []:
url = str(s.get("url", ""))
sources.append(
Source(
title=str(s.get("title", "") or url),
url=url,
domain=_domain(url),
snippet=str((s.get("snippets") or [""])[0]),
favicon=_favicon_for(url),
section="research",
)
)
for n in news:
sources.append(
Source(
title=str(n.get("title", "")),
url=str(n.get("url", "")),
domain=str(n.get("domain", "")),
snippet=str(n.get("snippet", "")),
published=str(n.get("published", "")),
favicon=str(n.get("favicon", "")),
section=str(n.get("section", "web")),
)
)
news_text = "\n".join(
f"- {n['title']} ({n['published']}) {n['domain']}: {n['snippet'][:120]}"
for n in news
)
parsed = await synthesize_briefing(company, focus, research_text, news_text)
def _list(key: str) -> list[str]:
return [str(x) for x in (parsed.get(key) or [])]
return Briefing(
company=company,
thesis=str(parsed.get("thesis", "")),
recent_developments=_list("recent_developments"),
risks=_list("risks"),
watch_items=_list("watch_items"),
sources=sources,
)
# {{/docs-fragment research_company}}
# {{docs-fragment report}}
REPORT_CSS = """
"""
def _cite(s: Source) -> str:
"""Render a rich You.com citation (Research or Search source)."""
if not s.url:
return ""
tag_cls = s.section if s.section in ("research", "news") else "web"
meta_bits = []
if s.published:
meta_bits.append(s.published[:10])
if s.title:
meta_bits.append(s.title)
meta = " · ".join(meta_bits)
snip = f"
Research answers from the You.com Research API (grounded
synthesis with inline citations) plus fresh headlines from the You.com
Search API (web + auto-classified news with timestamps and snippets).
"""
# {{/docs-fragment report}}
# {{docs-fragment driver}}
@env.task(report=True)
async def financial_research(
companies: list[str] = [
"NVIDIA",
"Advanced Micro Devices",
"Microsoft",
"Alphabet",
"Amazon",
"Meta Platforms",
"Broadcom",
"Taiwan Semiconductor Manufacturing",
],
focus: str = "Q4 earnings preview and competitive positioning",
research_effort: str = "standard",
freshness: str = "month",
) -> ResearchReport:
"""Fan out across companies and aggregate cited equity briefings."""
with flyte.group("research-companies"):
briefings = await asyncio.gather(
*[
research_company(c, focus, research_effort, freshness)
for c in companies
]
)
report = ResearchReport(briefings=list(briefings))
await flyte.report.replace.aio(_render_report(report), do_flush=True)
await flyte.report.flush.aio()
return report
# {{/docs-fragment driver}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(financial_research)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/financial_research_agent/main.py*
The Python packages are declared at the top of the file using the `uv` script style:
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# ///
```
## Data types
Each `Briefing` carries a thesis, recent developments, risks, watch items, and a list of `Source` objects from both the Research and Search APIs.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# main = "financial_research"
# params = ""
# ///
"""Financial research & earnings-cycle agent.
For each company, runs grounded, source-cited research via the You.com Research
API plus a fresh-news layer via the Search API, then uses Claude to synthesize
an analyst-ready equity briefing that preserves citations. Flyte caching cuts
duplicate spend when runs converge.
"""
# {{docs-fragment env}}
import asyncio
import json
import os
from dataclasses import dataclass, field
import flyte
MODEL = "anthropic/claude-haiku-4-5"
env = flyte.TaskEnvironment(
name="financial-research",
secrets=[
flyte.Secret(key="youdotcom-api-key", as_env_var="YOU_API_KEY"),
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
image=flyte.Image.from_uv_script(__file__, name="financial-research", pre=True),
resources=flyte.Resources(cpu="1", memory="1Gi"),
cache="auto",
)
# {{/docs-fragment env}}
# {{docs-fragment data_types}}
@dataclass
class Source:
title: str
url: str
domain: str = ""
snippet: str = ""
published: str = ""
favicon: str = ""
section: str = "research" # "research", "news", or "web"
def _domain(url: str) -> str:
from urllib.parse import urlparse
try:
return urlparse(url).netloc.replace("www.", "")
except Exception:
return ""
def _favicon_for(url: str) -> str:
return f"https://ydc-index.io/favicon?domain={_domain(url)}&size=128"
@dataclass
class Briefing:
company: str
thesis: str
recent_developments: list[str] = field(default_factory=list)
risks: list[str] = field(default_factory=list)
watch_items: list[str] = field(default_factory=list)
sources: list[Source] = field(default_factory=list)
@dataclass
class ResearchReport:
briefings: list[Briefing] = field(default_factory=list)
# {{/docs-fragment data_types}}
# {{docs-fragment you_apis}}
YOU_RESEARCH_URL = "https://api.you.com/v1/research"
YOU_SEARCH_URL = "https://ydc-index.io/v1/search"
async def _you_request(method: str, url: str, timeout: float, **kwargs) -> dict:
"""HTTP wrapper with exponential backoff + jitter on 429 rate limits.
Fanned-out tasks run in separate pods, so we retry on the client side to
smooth out bursts against the You.com API rate limit.
"""
import asyncio
import random
import httpx
headers = {"X-API-Key": os.environ["YOU_API_KEY"]}
if method == "POST":
headers["Content-Type"] = "application/json"
async with httpx.AsyncClient(timeout=timeout) as client:
for attempt in range(7):
resp = await client.request(method, url, headers=headers, **kwargs)
if resp.status_code == 429 and attempt < 6:
wait = float(resp.headers.get("retry-after") or 0) or min(2**attempt, 30)
await asyncio.sleep(wait + random.uniform(0, 2))
continue
resp.raise_for_status()
return resp.json()
resp.raise_for_status()
return resp.json()
@flyte.trace
async def you_research(question: str, research_effort: str, freshness: str) -> dict:
"""Grounded, citation-backed research answer."""
body = {
"input": question,
"research_effort": research_effort,
"source_control": {"freshness": freshness},
}
return await _you_request("POST", YOU_RESEARCH_URL, 300.0, json=body)
@flyte.trace
async def you_news(query: str, count: int = 6, freshness: str = "week") -> list[dict]:
"""Fresh news headlines for a company."""
params = {"query": query, "count": count, "freshness": freshness}
data = await _you_request("GET", YOU_SEARCH_URL, 60.0, params=params)
results = data.get("results", {})
out: list[dict] = []
for section in ("news", "web"):
for item in results.get(section, []) or []:
snippets = item.get("snippets") or []
url = item.get("url", "")
out.append(
{
"title": item.get("title", ""),
"url": url,
"domain": _domain(url),
"snippet": snippets[0] if snippets else item.get("description", ""),
"published": item.get("page_age", "") or "",
"favicon": item.get("favicon_url")
or _favicon_for(url),
"section": section,
}
)
return out
# {{/docs-fragment you_apis}}
# {{docs-fragment llm}}
@flyte.trace
async def synthesize_briefing(company: str, focus: str, research: str, news: str) -> dict:
"""Use Claude to synthesize a structured equity briefing."""
from litellm import acompletion
system = (
"You are an equity research analyst. Using ONLY the grounded research "
"and news provided, write a concise briefing. Respond ONLY with JSON: "
'{"thesis": str, "recent_developments": [str], "risks": [str], '
'"watch_items": [str]}. Keep each list to 3-5 short, specific bullets.'
)
user = (
f"Company: {company}\nFocus: {focus}\n\n"
f"Grounded research:\n{research}\n\nRecent news:\n{news}"
)
resp = await acompletion(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
temperature=0.0,
max_tokens=1536,
)
parsed = _parse_json(resp.choices[0].message.content)
return parsed if isinstance(parsed, dict) else {}
def _parse_json(text: str) -> dict | list:
text = text.strip()
if text.startswith("```"):
text = text.split("```", 2)[1]
if text.lstrip().startswith("json"):
text = text.lstrip()[4:]
start = min((i for i in (text.find("{"), text.find("[")) if i != -1), default=0)
end = max(text.rfind("}"), text.rfind("]")) + 1
return json.loads(text[start:end])
# {{/docs-fragment llm}}
# {{docs-fragment research_company}}
@env.task(retries=3)
async def research_company(
company: str,
focus: str,
research_effort: str,
freshness: str,
) -> Briefing:
"""Research one company and synthesize a cited briefing."""
question = (
f"Provide a grounded analysis of {company} with respect to: {focus}. "
f"Cover recent financial performance, strategic moves, competitive "
f"positioning, and risks."
)
research_result, news = await asyncio.gather(
you_research(question, research_effort, freshness),
you_news(f"{company} earnings news", freshness=freshness),
)
output = research_result.get("output", {})
research_text = output.get("content", "")
if not isinstance(research_text, str):
research_text = json.dumps(research_text)
sources: list[Source] = []
for s in output.get("sources", []) or []:
url = str(s.get("url", ""))
sources.append(
Source(
title=str(s.get("title", "") or url),
url=url,
domain=_domain(url),
snippet=str((s.get("snippets") or [""])[0]),
favicon=_favicon_for(url),
section="research",
)
)
for n in news:
sources.append(
Source(
title=str(n.get("title", "")),
url=str(n.get("url", "")),
domain=str(n.get("domain", "")),
snippet=str(n.get("snippet", "")),
published=str(n.get("published", "")),
favicon=str(n.get("favicon", "")),
section=str(n.get("section", "web")),
)
)
news_text = "\n".join(
f"- {n['title']} ({n['published']}) {n['domain']}: {n['snippet'][:120]}"
for n in news
)
parsed = await synthesize_briefing(company, focus, research_text, news_text)
def _list(key: str) -> list[str]:
return [str(x) for x in (parsed.get(key) or [])]
return Briefing(
company=company,
thesis=str(parsed.get("thesis", "")),
recent_developments=_list("recent_developments"),
risks=_list("risks"),
watch_items=_list("watch_items"),
sources=sources,
)
# {{/docs-fragment research_company}}
# {{docs-fragment report}}
REPORT_CSS = """
"""
def _cite(s: Source) -> str:
"""Render a rich You.com citation (Research or Search source)."""
if not s.url:
return ""
tag_cls = s.section if s.section in ("research", "news") else "web"
meta_bits = []
if s.published:
meta_bits.append(s.published[:10])
if s.title:
meta_bits.append(s.title)
meta = " · ".join(meta_bits)
snip = f"
Research answers from the You.com Research API (grounded
synthesis with inline citations) plus fresh headlines from the You.com
Search API (web + auto-classified news with timestamps and snippets).
"""
# {{/docs-fragment report}}
# {{docs-fragment driver}}
@env.task(report=True)
async def financial_research(
companies: list[str] = [
"NVIDIA",
"Advanced Micro Devices",
"Microsoft",
"Alphabet",
"Amazon",
"Meta Platforms",
"Broadcom",
"Taiwan Semiconductor Manufacturing",
],
focus: str = "Q4 earnings preview and competitive positioning",
research_effort: str = "standard",
freshness: str = "month",
) -> ResearchReport:
"""Fan out across companies and aggregate cited equity briefings."""
with flyte.group("research-companies"):
briefings = await asyncio.gather(
*[
research_company(c, focus, research_effort, freshness)
for c in companies
]
)
report = ResearchReport(briefings=list(briefings))
await flyte.report.replace.aio(_render_report(report), do_flush=True)
await flyte.report.flush.aio()
return report
# {{/docs-fragment driver}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(financial_research)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/financial_research_agent/main.py*
## You.com Research and Search APIs
The agent uses both You.com APIs in parallel for each company:
- **Research API** (`https://api.you.com/v1/research`) — grounded, citation-backed analysis with configurable `research_effort` (`lite`, `standard`, `deep`, `exhaustive`). See the [Research API reference](https://you.com/docs/api-reference/research/v1-research).
- **Search API** (`https://ydc-index.io/v1/search`) — fresh news headlines with `freshness` filtering. See the [Search API reference](https://you.com/docs/api-reference/search/v1-search).
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# main = "financial_research"
# params = ""
# ///
"""Financial research & earnings-cycle agent.
For each company, runs grounded, source-cited research via the You.com Research
API plus a fresh-news layer via the Search API, then uses Claude to synthesize
an analyst-ready equity briefing that preserves citations. Flyte caching cuts
duplicate spend when runs converge.
"""
# {{docs-fragment env}}
import asyncio
import json
import os
from dataclasses import dataclass, field
import flyte
MODEL = "anthropic/claude-haiku-4-5"
env = flyte.TaskEnvironment(
name="financial-research",
secrets=[
flyte.Secret(key="youdotcom-api-key", as_env_var="YOU_API_KEY"),
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
image=flyte.Image.from_uv_script(__file__, name="financial-research", pre=True),
resources=flyte.Resources(cpu="1", memory="1Gi"),
cache="auto",
)
# {{/docs-fragment env}}
# {{docs-fragment data_types}}
@dataclass
class Source:
title: str
url: str
domain: str = ""
snippet: str = ""
published: str = ""
favicon: str = ""
section: str = "research" # "research", "news", or "web"
def _domain(url: str) -> str:
from urllib.parse import urlparse
try:
return urlparse(url).netloc.replace("www.", "")
except Exception:
return ""
def _favicon_for(url: str) -> str:
return f"https://ydc-index.io/favicon?domain={_domain(url)}&size=128"
@dataclass
class Briefing:
company: str
thesis: str
recent_developments: list[str] = field(default_factory=list)
risks: list[str] = field(default_factory=list)
watch_items: list[str] = field(default_factory=list)
sources: list[Source] = field(default_factory=list)
@dataclass
class ResearchReport:
briefings: list[Briefing] = field(default_factory=list)
# {{/docs-fragment data_types}}
# {{docs-fragment you_apis}}
YOU_RESEARCH_URL = "https://api.you.com/v1/research"
YOU_SEARCH_URL = "https://ydc-index.io/v1/search"
async def _you_request(method: str, url: str, timeout: float, **kwargs) -> dict:
"""HTTP wrapper with exponential backoff + jitter on 429 rate limits.
Fanned-out tasks run in separate pods, so we retry on the client side to
smooth out bursts against the You.com API rate limit.
"""
import asyncio
import random
import httpx
headers = {"X-API-Key": os.environ["YOU_API_KEY"]}
if method == "POST":
headers["Content-Type"] = "application/json"
async with httpx.AsyncClient(timeout=timeout) as client:
for attempt in range(7):
resp = await client.request(method, url, headers=headers, **kwargs)
if resp.status_code == 429 and attempt < 6:
wait = float(resp.headers.get("retry-after") or 0) or min(2**attempt, 30)
await asyncio.sleep(wait + random.uniform(0, 2))
continue
resp.raise_for_status()
return resp.json()
resp.raise_for_status()
return resp.json()
@flyte.trace
async def you_research(question: str, research_effort: str, freshness: str) -> dict:
"""Grounded, citation-backed research answer."""
body = {
"input": question,
"research_effort": research_effort,
"source_control": {"freshness": freshness},
}
return await _you_request("POST", YOU_RESEARCH_URL, 300.0, json=body)
@flyte.trace
async def you_news(query: str, count: int = 6, freshness: str = "week") -> list[dict]:
"""Fresh news headlines for a company."""
params = {"query": query, "count": count, "freshness": freshness}
data = await _you_request("GET", YOU_SEARCH_URL, 60.0, params=params)
results = data.get("results", {})
out: list[dict] = []
for section in ("news", "web"):
for item in results.get(section, []) or []:
snippets = item.get("snippets") or []
url = item.get("url", "")
out.append(
{
"title": item.get("title", ""),
"url": url,
"domain": _domain(url),
"snippet": snippets[0] if snippets else item.get("description", ""),
"published": item.get("page_age", "") or "",
"favicon": item.get("favicon_url")
or _favicon_for(url),
"section": section,
}
)
return out
# {{/docs-fragment you_apis}}
# {{docs-fragment llm}}
@flyte.trace
async def synthesize_briefing(company: str, focus: str, research: str, news: str) -> dict:
"""Use Claude to synthesize a structured equity briefing."""
from litellm import acompletion
system = (
"You are an equity research analyst. Using ONLY the grounded research "
"and news provided, write a concise briefing. Respond ONLY with JSON: "
'{"thesis": str, "recent_developments": [str], "risks": [str], '
'"watch_items": [str]}. Keep each list to 3-5 short, specific bullets.'
)
user = (
f"Company: {company}\nFocus: {focus}\n\n"
f"Grounded research:\n{research}\n\nRecent news:\n{news}"
)
resp = await acompletion(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
temperature=0.0,
max_tokens=1536,
)
parsed = _parse_json(resp.choices[0].message.content)
return parsed if isinstance(parsed, dict) else {}
def _parse_json(text: str) -> dict | list:
text = text.strip()
if text.startswith("```"):
text = text.split("```", 2)[1]
if text.lstrip().startswith("json"):
text = text.lstrip()[4:]
start = min((i for i in (text.find("{"), text.find("[")) if i != -1), default=0)
end = max(text.rfind("}"), text.rfind("]")) + 1
return json.loads(text[start:end])
# {{/docs-fragment llm}}
# {{docs-fragment research_company}}
@env.task(retries=3)
async def research_company(
company: str,
focus: str,
research_effort: str,
freshness: str,
) -> Briefing:
"""Research one company and synthesize a cited briefing."""
question = (
f"Provide a grounded analysis of {company} with respect to: {focus}. "
f"Cover recent financial performance, strategic moves, competitive "
f"positioning, and risks."
)
research_result, news = await asyncio.gather(
you_research(question, research_effort, freshness),
you_news(f"{company} earnings news", freshness=freshness),
)
output = research_result.get("output", {})
research_text = output.get("content", "")
if not isinstance(research_text, str):
research_text = json.dumps(research_text)
sources: list[Source] = []
for s in output.get("sources", []) or []:
url = str(s.get("url", ""))
sources.append(
Source(
title=str(s.get("title", "") or url),
url=url,
domain=_domain(url),
snippet=str((s.get("snippets") or [""])[0]),
favicon=_favicon_for(url),
section="research",
)
)
for n in news:
sources.append(
Source(
title=str(n.get("title", "")),
url=str(n.get("url", "")),
domain=str(n.get("domain", "")),
snippet=str(n.get("snippet", "")),
published=str(n.get("published", "")),
favicon=str(n.get("favicon", "")),
section=str(n.get("section", "web")),
)
)
news_text = "\n".join(
f"- {n['title']} ({n['published']}) {n['domain']}: {n['snippet'][:120]}"
for n in news
)
parsed = await synthesize_briefing(company, focus, research_text, news_text)
def _list(key: str) -> list[str]:
return [str(x) for x in (parsed.get(key) or [])]
return Briefing(
company=company,
thesis=str(parsed.get("thesis", "")),
recent_developments=_list("recent_developments"),
risks=_list("risks"),
watch_items=_list("watch_items"),
sources=sources,
)
# {{/docs-fragment research_company}}
# {{docs-fragment report}}
REPORT_CSS = """
"""
def _cite(s: Source) -> str:
"""Render a rich You.com citation (Research or Search source)."""
if not s.url:
return ""
tag_cls = s.section if s.section in ("research", "news") else "web"
meta_bits = []
if s.published:
meta_bits.append(s.published[:10])
if s.title:
meta_bits.append(s.title)
meta = " · ".join(meta_bits)
snip = f"
Research answers from the You.com Research API (grounded
synthesis with inline citations) plus fresh headlines from the You.com
Search API (web + auto-classified news with timestamps and snippets).
"""
# {{/docs-fragment report}}
# {{docs-fragment driver}}
@env.task(report=True)
async def financial_research(
companies: list[str] = [
"NVIDIA",
"Advanced Micro Devices",
"Microsoft",
"Alphabet",
"Amazon",
"Meta Platforms",
"Broadcom",
"Taiwan Semiconductor Manufacturing",
],
focus: str = "Q4 earnings preview and competitive positioning",
research_effort: str = "standard",
freshness: str = "month",
) -> ResearchReport:
"""Fan out across companies and aggregate cited equity briefings."""
with flyte.group("research-companies"):
briefings = await asyncio.gather(
*[
research_company(c, focus, research_effort, freshness)
for c in companies
]
)
report = ResearchReport(briefings=list(briefings))
await flyte.report.replace.aio(_render_report(report), do_flush=True)
await flyte.report.flush.aio()
return report
# {{/docs-fragment driver}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(financial_research)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/financial_research_agent/main.py*
## Synthesize briefings with Claude
Claude, routed through LiteLLM, turns the grounded research answer and news headlines into a structured equity briefing grounded in the evidence provided.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# main = "financial_research"
# params = ""
# ///
"""Financial research & earnings-cycle agent.
For each company, runs grounded, source-cited research via the You.com Research
API plus a fresh-news layer via the Search API, then uses Claude to synthesize
an analyst-ready equity briefing that preserves citations. Flyte caching cuts
duplicate spend when runs converge.
"""
# {{docs-fragment env}}
import asyncio
import json
import os
from dataclasses import dataclass, field
import flyte
MODEL = "anthropic/claude-haiku-4-5"
env = flyte.TaskEnvironment(
name="financial-research",
secrets=[
flyte.Secret(key="youdotcom-api-key", as_env_var="YOU_API_KEY"),
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
image=flyte.Image.from_uv_script(__file__, name="financial-research", pre=True),
resources=flyte.Resources(cpu="1", memory="1Gi"),
cache="auto",
)
# {{/docs-fragment env}}
# {{docs-fragment data_types}}
@dataclass
class Source:
title: str
url: str
domain: str = ""
snippet: str = ""
published: str = ""
favicon: str = ""
section: str = "research" # "research", "news", or "web"
def _domain(url: str) -> str:
from urllib.parse import urlparse
try:
return urlparse(url).netloc.replace("www.", "")
except Exception:
return ""
def _favicon_for(url: str) -> str:
return f"https://ydc-index.io/favicon?domain={_domain(url)}&size=128"
@dataclass
class Briefing:
company: str
thesis: str
recent_developments: list[str] = field(default_factory=list)
risks: list[str] = field(default_factory=list)
watch_items: list[str] = field(default_factory=list)
sources: list[Source] = field(default_factory=list)
@dataclass
class ResearchReport:
briefings: list[Briefing] = field(default_factory=list)
# {{/docs-fragment data_types}}
# {{docs-fragment you_apis}}
YOU_RESEARCH_URL = "https://api.you.com/v1/research"
YOU_SEARCH_URL = "https://ydc-index.io/v1/search"
async def _you_request(method: str, url: str, timeout: float, **kwargs) -> dict:
"""HTTP wrapper with exponential backoff + jitter on 429 rate limits.
Fanned-out tasks run in separate pods, so we retry on the client side to
smooth out bursts against the You.com API rate limit.
"""
import asyncio
import random
import httpx
headers = {"X-API-Key": os.environ["YOU_API_KEY"]}
if method == "POST":
headers["Content-Type"] = "application/json"
async with httpx.AsyncClient(timeout=timeout) as client:
for attempt in range(7):
resp = await client.request(method, url, headers=headers, **kwargs)
if resp.status_code == 429 and attempt < 6:
wait = float(resp.headers.get("retry-after") or 0) or min(2**attempt, 30)
await asyncio.sleep(wait + random.uniform(0, 2))
continue
resp.raise_for_status()
return resp.json()
resp.raise_for_status()
return resp.json()
@flyte.trace
async def you_research(question: str, research_effort: str, freshness: str) -> dict:
"""Grounded, citation-backed research answer."""
body = {
"input": question,
"research_effort": research_effort,
"source_control": {"freshness": freshness},
}
return await _you_request("POST", YOU_RESEARCH_URL, 300.0, json=body)
@flyte.trace
async def you_news(query: str, count: int = 6, freshness: str = "week") -> list[dict]:
"""Fresh news headlines for a company."""
params = {"query": query, "count": count, "freshness": freshness}
data = await _you_request("GET", YOU_SEARCH_URL, 60.0, params=params)
results = data.get("results", {})
out: list[dict] = []
for section in ("news", "web"):
for item in results.get(section, []) or []:
snippets = item.get("snippets") or []
url = item.get("url", "")
out.append(
{
"title": item.get("title", ""),
"url": url,
"domain": _domain(url),
"snippet": snippets[0] if snippets else item.get("description", ""),
"published": item.get("page_age", "") or "",
"favicon": item.get("favicon_url")
or _favicon_for(url),
"section": section,
}
)
return out
# {{/docs-fragment you_apis}}
# {{docs-fragment llm}}
@flyte.trace
async def synthesize_briefing(company: str, focus: str, research: str, news: str) -> dict:
"""Use Claude to synthesize a structured equity briefing."""
from litellm import acompletion
system = (
"You are an equity research analyst. Using ONLY the grounded research "
"and news provided, write a concise briefing. Respond ONLY with JSON: "
'{"thesis": str, "recent_developments": [str], "risks": [str], '
'"watch_items": [str]}. Keep each list to 3-5 short, specific bullets.'
)
user = (
f"Company: {company}\nFocus: {focus}\n\n"
f"Grounded research:\n{research}\n\nRecent news:\n{news}"
)
resp = await acompletion(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
temperature=0.0,
max_tokens=1536,
)
parsed = _parse_json(resp.choices[0].message.content)
return parsed if isinstance(parsed, dict) else {}
def _parse_json(text: str) -> dict | list:
text = text.strip()
if text.startswith("```"):
text = text.split("```", 2)[1]
if text.lstrip().startswith("json"):
text = text.lstrip()[4:]
start = min((i for i in (text.find("{"), text.find("[")) if i != -1), default=0)
end = max(text.rfind("}"), text.rfind("]")) + 1
return json.loads(text[start:end])
# {{/docs-fragment llm}}
# {{docs-fragment research_company}}
@env.task(retries=3)
async def research_company(
company: str,
focus: str,
research_effort: str,
freshness: str,
) -> Briefing:
"""Research one company and synthesize a cited briefing."""
question = (
f"Provide a grounded analysis of {company} with respect to: {focus}. "
f"Cover recent financial performance, strategic moves, competitive "
f"positioning, and risks."
)
research_result, news = await asyncio.gather(
you_research(question, research_effort, freshness),
you_news(f"{company} earnings news", freshness=freshness),
)
output = research_result.get("output", {})
research_text = output.get("content", "")
if not isinstance(research_text, str):
research_text = json.dumps(research_text)
sources: list[Source] = []
for s in output.get("sources", []) or []:
url = str(s.get("url", ""))
sources.append(
Source(
title=str(s.get("title", "") or url),
url=url,
domain=_domain(url),
snippet=str((s.get("snippets") or [""])[0]),
favicon=_favicon_for(url),
section="research",
)
)
for n in news:
sources.append(
Source(
title=str(n.get("title", "")),
url=str(n.get("url", "")),
domain=str(n.get("domain", "")),
snippet=str(n.get("snippet", "")),
published=str(n.get("published", "")),
favicon=str(n.get("favicon", "")),
section=str(n.get("section", "web")),
)
)
news_text = "\n".join(
f"- {n['title']} ({n['published']}) {n['domain']}: {n['snippet'][:120]}"
for n in news
)
parsed = await synthesize_briefing(company, focus, research_text, news_text)
def _list(key: str) -> list[str]:
return [str(x) for x in (parsed.get(key) or [])]
return Briefing(
company=company,
thesis=str(parsed.get("thesis", "")),
recent_developments=_list("recent_developments"),
risks=_list("risks"),
watch_items=_list("watch_items"),
sources=sources,
)
# {{/docs-fragment research_company}}
# {{docs-fragment report}}
REPORT_CSS = """
"""
def _cite(s: Source) -> str:
"""Render a rich You.com citation (Research or Search source)."""
if not s.url:
return ""
tag_cls = s.section if s.section in ("research", "news") else "web"
meta_bits = []
if s.published:
meta_bits.append(s.published[:10])
if s.title:
meta_bits.append(s.title)
meta = " · ".join(meta_bits)
snip = f"
Research answers from the You.com Research API (grounded
synthesis with inline citations) plus fresh headlines from the You.com
Search API (web + auto-classified news with timestamps and snippets).
"""
# {{/docs-fragment report}}
# {{docs-fragment driver}}
@env.task(report=True)
async def financial_research(
companies: list[str] = [
"NVIDIA",
"Advanced Micro Devices",
"Microsoft",
"Alphabet",
"Amazon",
"Meta Platforms",
"Broadcom",
"Taiwan Semiconductor Manufacturing",
],
focus: str = "Q4 earnings preview and competitive positioning",
research_effort: str = "standard",
freshness: str = "month",
) -> ResearchReport:
"""Fan out across companies and aggregate cited equity briefings."""
with flyte.group("research-companies"):
briefings = await asyncio.gather(
*[
research_company(c, focus, research_effort, freshness)
for c in companies
]
)
report = ResearchReport(briefings=list(briefings))
await flyte.report.replace.aio(_render_report(report), do_flush=True)
await flyte.report.flush.aio()
return report
# {{/docs-fragment driver}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(financial_research)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/financial_research_agent/main.py*
## Research one company
The `research_company` task calls both You.com APIs in parallel, collects sources, and synthesizes a structured briefing.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# main = "financial_research"
# params = ""
# ///
"""Financial research & earnings-cycle agent.
For each company, runs grounded, source-cited research via the You.com Research
API plus a fresh-news layer via the Search API, then uses Claude to synthesize
an analyst-ready equity briefing that preserves citations. Flyte caching cuts
duplicate spend when runs converge.
"""
# {{docs-fragment env}}
import asyncio
import json
import os
from dataclasses import dataclass, field
import flyte
MODEL = "anthropic/claude-haiku-4-5"
env = flyte.TaskEnvironment(
name="financial-research",
secrets=[
flyte.Secret(key="youdotcom-api-key", as_env_var="YOU_API_KEY"),
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
image=flyte.Image.from_uv_script(__file__, name="financial-research", pre=True),
resources=flyte.Resources(cpu="1", memory="1Gi"),
cache="auto",
)
# {{/docs-fragment env}}
# {{docs-fragment data_types}}
@dataclass
class Source:
title: str
url: str
domain: str = ""
snippet: str = ""
published: str = ""
favicon: str = ""
section: str = "research" # "research", "news", or "web"
def _domain(url: str) -> str:
from urllib.parse import urlparse
try:
return urlparse(url).netloc.replace("www.", "")
except Exception:
return ""
def _favicon_for(url: str) -> str:
return f"https://ydc-index.io/favicon?domain={_domain(url)}&size=128"
@dataclass
class Briefing:
company: str
thesis: str
recent_developments: list[str] = field(default_factory=list)
risks: list[str] = field(default_factory=list)
watch_items: list[str] = field(default_factory=list)
sources: list[Source] = field(default_factory=list)
@dataclass
class ResearchReport:
briefings: list[Briefing] = field(default_factory=list)
# {{/docs-fragment data_types}}
# {{docs-fragment you_apis}}
YOU_RESEARCH_URL = "https://api.you.com/v1/research"
YOU_SEARCH_URL = "https://ydc-index.io/v1/search"
async def _you_request(method: str, url: str, timeout: float, **kwargs) -> dict:
"""HTTP wrapper with exponential backoff + jitter on 429 rate limits.
Fanned-out tasks run in separate pods, so we retry on the client side to
smooth out bursts against the You.com API rate limit.
"""
import asyncio
import random
import httpx
headers = {"X-API-Key": os.environ["YOU_API_KEY"]}
if method == "POST":
headers["Content-Type"] = "application/json"
async with httpx.AsyncClient(timeout=timeout) as client:
for attempt in range(7):
resp = await client.request(method, url, headers=headers, **kwargs)
if resp.status_code == 429 and attempt < 6:
wait = float(resp.headers.get("retry-after") or 0) or min(2**attempt, 30)
await asyncio.sleep(wait + random.uniform(0, 2))
continue
resp.raise_for_status()
return resp.json()
resp.raise_for_status()
return resp.json()
@flyte.trace
async def you_research(question: str, research_effort: str, freshness: str) -> dict:
"""Grounded, citation-backed research answer."""
body = {
"input": question,
"research_effort": research_effort,
"source_control": {"freshness": freshness},
}
return await _you_request("POST", YOU_RESEARCH_URL, 300.0, json=body)
@flyte.trace
async def you_news(query: str, count: int = 6, freshness: str = "week") -> list[dict]:
"""Fresh news headlines for a company."""
params = {"query": query, "count": count, "freshness": freshness}
data = await _you_request("GET", YOU_SEARCH_URL, 60.0, params=params)
results = data.get("results", {})
out: list[dict] = []
for section in ("news", "web"):
for item in results.get(section, []) or []:
snippets = item.get("snippets") or []
url = item.get("url", "")
out.append(
{
"title": item.get("title", ""),
"url": url,
"domain": _domain(url),
"snippet": snippets[0] if snippets else item.get("description", ""),
"published": item.get("page_age", "") or "",
"favicon": item.get("favicon_url")
or _favicon_for(url),
"section": section,
}
)
return out
# {{/docs-fragment you_apis}}
# {{docs-fragment llm}}
@flyte.trace
async def synthesize_briefing(company: str, focus: str, research: str, news: str) -> dict:
"""Use Claude to synthesize a structured equity briefing."""
from litellm import acompletion
system = (
"You are an equity research analyst. Using ONLY the grounded research "
"and news provided, write a concise briefing. Respond ONLY with JSON: "
'{"thesis": str, "recent_developments": [str], "risks": [str], '
'"watch_items": [str]}. Keep each list to 3-5 short, specific bullets.'
)
user = (
f"Company: {company}\nFocus: {focus}\n\n"
f"Grounded research:\n{research}\n\nRecent news:\n{news}"
)
resp = await acompletion(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
temperature=0.0,
max_tokens=1536,
)
parsed = _parse_json(resp.choices[0].message.content)
return parsed if isinstance(parsed, dict) else {}
def _parse_json(text: str) -> dict | list:
text = text.strip()
if text.startswith("```"):
text = text.split("```", 2)[1]
if text.lstrip().startswith("json"):
text = text.lstrip()[4:]
start = min((i for i in (text.find("{"), text.find("[")) if i != -1), default=0)
end = max(text.rfind("}"), text.rfind("]")) + 1
return json.loads(text[start:end])
# {{/docs-fragment llm}}
# {{docs-fragment research_company}}
@env.task(retries=3)
async def research_company(
company: str,
focus: str,
research_effort: str,
freshness: str,
) -> Briefing:
"""Research one company and synthesize a cited briefing."""
question = (
f"Provide a grounded analysis of {company} with respect to: {focus}. "
f"Cover recent financial performance, strategic moves, competitive "
f"positioning, and risks."
)
research_result, news = await asyncio.gather(
you_research(question, research_effort, freshness),
you_news(f"{company} earnings news", freshness=freshness),
)
output = research_result.get("output", {})
research_text = output.get("content", "")
if not isinstance(research_text, str):
research_text = json.dumps(research_text)
sources: list[Source] = []
for s in output.get("sources", []) or []:
url = str(s.get("url", ""))
sources.append(
Source(
title=str(s.get("title", "") or url),
url=url,
domain=_domain(url),
snippet=str((s.get("snippets") or [""])[0]),
favicon=_favicon_for(url),
section="research",
)
)
for n in news:
sources.append(
Source(
title=str(n.get("title", "")),
url=str(n.get("url", "")),
domain=str(n.get("domain", "")),
snippet=str(n.get("snippet", "")),
published=str(n.get("published", "")),
favicon=str(n.get("favicon", "")),
section=str(n.get("section", "web")),
)
)
news_text = "\n".join(
f"- {n['title']} ({n['published']}) {n['domain']}: {n['snippet'][:120]}"
for n in news
)
parsed = await synthesize_briefing(company, focus, research_text, news_text)
def _list(key: str) -> list[str]:
return [str(x) for x in (parsed.get(key) or [])]
return Briefing(
company=company,
thesis=str(parsed.get("thesis", "")),
recent_developments=_list("recent_developments"),
risks=_list("risks"),
watch_items=_list("watch_items"),
sources=sources,
)
# {{/docs-fragment research_company}}
# {{docs-fragment report}}
REPORT_CSS = """
"""
def _cite(s: Source) -> str:
"""Render a rich You.com citation (Research or Search source)."""
if not s.url:
return ""
tag_cls = s.section if s.section in ("research", "news") else "web"
meta_bits = []
if s.published:
meta_bits.append(s.published[:10])
if s.title:
meta_bits.append(s.title)
meta = " · ".join(meta_bits)
snip = f"
Research answers from the You.com Research API (grounded
synthesis with inline citations) plus fresh headlines from the You.com
Search API (web + auto-classified news with timestamps and snippets).
"""
# {{/docs-fragment report}}
# {{docs-fragment driver}}
@env.task(report=True)
async def financial_research(
companies: list[str] = [
"NVIDIA",
"Advanced Micro Devices",
"Microsoft",
"Alphabet",
"Amazon",
"Meta Platforms",
"Broadcom",
"Taiwan Semiconductor Manufacturing",
],
focus: str = "Q4 earnings preview and competitive positioning",
research_effort: str = "standard",
freshness: str = "month",
) -> ResearchReport:
"""Fan out across companies and aggregate cited equity briefings."""
with flyte.group("research-companies"):
briefings = await asyncio.gather(
*[
research_company(c, focus, research_effort, freshness)
for c in companies
]
)
report = ResearchReport(briefings=list(briefings))
await flyte.report.replace.aio(_render_report(report), do_flush=True)
await flyte.report.flush.aio()
return report
# {{/docs-fragment driver}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(financial_research)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/financial_research_agent/main.py*
## Orchestration
The `financial_research` driver task fans out across all companies and renders a Flyte report with per-company briefings and citations.
```
# /// script
# requires-python = "==3.13"
# dependencies = [
# "flyte>=2.4.0",
# "httpx>=0.27.0",
# "litellm>=1.72.0",
# ]
# main = "financial_research"
# params = ""
# ///
"""Financial research & earnings-cycle agent.
For each company, runs grounded, source-cited research via the You.com Research
API plus a fresh-news layer via the Search API, then uses Claude to synthesize
an analyst-ready equity briefing that preserves citations. Flyte caching cuts
duplicate spend when runs converge.
"""
# {{docs-fragment env}}
import asyncio
import json
import os
from dataclasses import dataclass, field
import flyte
MODEL = "anthropic/claude-haiku-4-5"
env = flyte.TaskEnvironment(
name="financial-research",
secrets=[
flyte.Secret(key="youdotcom-api-key", as_env_var="YOU_API_KEY"),
flyte.Secret(key="internal-anthropic-api-key", as_env_var="ANTHROPIC_API_KEY"),
],
image=flyte.Image.from_uv_script(__file__, name="financial-research", pre=True),
resources=flyte.Resources(cpu="1", memory="1Gi"),
cache="auto",
)
# {{/docs-fragment env}}
# {{docs-fragment data_types}}
@dataclass
class Source:
title: str
url: str
domain: str = ""
snippet: str = ""
published: str = ""
favicon: str = ""
section: str = "research" # "research", "news", or "web"
def _domain(url: str) -> str:
from urllib.parse import urlparse
try:
return urlparse(url).netloc.replace("www.", "")
except Exception:
return ""
def _favicon_for(url: str) -> str:
return f"https://ydc-index.io/favicon?domain={_domain(url)}&size=128"
@dataclass
class Briefing:
company: str
thesis: str
recent_developments: list[str] = field(default_factory=list)
risks: list[str] = field(default_factory=list)
watch_items: list[str] = field(default_factory=list)
sources: list[Source] = field(default_factory=list)
@dataclass
class ResearchReport:
briefings: list[Briefing] = field(default_factory=list)
# {{/docs-fragment data_types}}
# {{docs-fragment you_apis}}
YOU_RESEARCH_URL = "https://api.you.com/v1/research"
YOU_SEARCH_URL = "https://ydc-index.io/v1/search"
async def _you_request(method: str, url: str, timeout: float, **kwargs) -> dict:
"""HTTP wrapper with exponential backoff + jitter on 429 rate limits.
Fanned-out tasks run in separate pods, so we retry on the client side to
smooth out bursts against the You.com API rate limit.
"""
import asyncio
import random
import httpx
headers = {"X-API-Key": os.environ["YOU_API_KEY"]}
if method == "POST":
headers["Content-Type"] = "application/json"
async with httpx.AsyncClient(timeout=timeout) as client:
for attempt in range(7):
resp = await client.request(method, url, headers=headers, **kwargs)
if resp.status_code == 429 and attempt < 6:
wait = float(resp.headers.get("retry-after") or 0) or min(2**attempt, 30)
await asyncio.sleep(wait + random.uniform(0, 2))
continue
resp.raise_for_status()
return resp.json()
resp.raise_for_status()
return resp.json()
@flyte.trace
async def you_research(question: str, research_effort: str, freshness: str) -> dict:
"""Grounded, citation-backed research answer."""
body = {
"input": question,
"research_effort": research_effort,
"source_control": {"freshness": freshness},
}
return await _you_request("POST", YOU_RESEARCH_URL, 300.0, json=body)
@flyte.trace
async def you_news(query: str, count: int = 6, freshness: str = "week") -> list[dict]:
"""Fresh news headlines for a company."""
params = {"query": query, "count": count, "freshness": freshness}
data = await _you_request("GET", YOU_SEARCH_URL, 60.0, params=params)
results = data.get("results", {})
out: list[dict] = []
for section in ("news", "web"):
for item in results.get(section, []) or []:
snippets = item.get("snippets") or []
url = item.get("url", "")
out.append(
{
"title": item.get("title", ""),
"url": url,
"domain": _domain(url),
"snippet": snippets[0] if snippets else item.get("description", ""),
"published": item.get("page_age", "") or "",
"favicon": item.get("favicon_url")
or _favicon_for(url),
"section": section,
}
)
return out
# {{/docs-fragment you_apis}}
# {{docs-fragment llm}}
@flyte.trace
async def synthesize_briefing(company: str, focus: str, research: str, news: str) -> dict:
"""Use Claude to synthesize a structured equity briefing."""
from litellm import acompletion
system = (
"You are an equity research analyst. Using ONLY the grounded research "
"and news provided, write a concise briefing. Respond ONLY with JSON: "
'{"thesis": str, "recent_developments": [str], "risks": [str], '
'"watch_items": [str]}. Keep each list to 3-5 short, specific bullets.'
)
user = (
f"Company: {company}\nFocus: {focus}\n\n"
f"Grounded research:\n{research}\n\nRecent news:\n{news}"
)
resp = await acompletion(
model=MODEL,
messages=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
temperature=0.0,
max_tokens=1536,
)
parsed = _parse_json(resp.choices[0].message.content)
return parsed if isinstance(parsed, dict) else {}
def _parse_json(text: str) -> dict | list:
text = text.strip()
if text.startswith("```"):
text = text.split("```", 2)[1]
if text.lstrip().startswith("json"):
text = text.lstrip()[4:]
start = min((i for i in (text.find("{"), text.find("[")) if i != -1), default=0)
end = max(text.rfind("}"), text.rfind("]")) + 1
return json.loads(text[start:end])
# {{/docs-fragment llm}}
# {{docs-fragment research_company}}
@env.task(retries=3)
async def research_company(
company: str,
focus: str,
research_effort: str,
freshness: str,
) -> Briefing:
"""Research one company and synthesize a cited briefing."""
question = (
f"Provide a grounded analysis of {company} with respect to: {focus}. "
f"Cover recent financial performance, strategic moves, competitive "
f"positioning, and risks."
)
research_result, news = await asyncio.gather(
you_research(question, research_effort, freshness),
you_news(f"{company} earnings news", freshness=freshness),
)
output = research_result.get("output", {})
research_text = output.get("content", "")
if not isinstance(research_text, str):
research_text = json.dumps(research_text)
sources: list[Source] = []
for s in output.get("sources", []) or []:
url = str(s.get("url", ""))
sources.append(
Source(
title=str(s.get("title", "") or url),
url=url,
domain=_domain(url),
snippet=str((s.get("snippets") or [""])[0]),
favicon=_favicon_for(url),
section="research",
)
)
for n in news:
sources.append(
Source(
title=str(n.get("title", "")),
url=str(n.get("url", "")),
domain=str(n.get("domain", "")),
snippet=str(n.get("snippet", "")),
published=str(n.get("published", "")),
favicon=str(n.get("favicon", "")),
section=str(n.get("section", "web")),
)
)
news_text = "\n".join(
f"- {n['title']} ({n['published']}) {n['domain']}: {n['snippet'][:120]}"
for n in news
)
parsed = await synthesize_briefing(company, focus, research_text, news_text)
def _list(key: str) -> list[str]:
return [str(x) for x in (parsed.get(key) or [])]
return Briefing(
company=company,
thesis=str(parsed.get("thesis", "")),
recent_developments=_list("recent_developments"),
risks=_list("risks"),
watch_items=_list("watch_items"),
sources=sources,
)
# {{/docs-fragment research_company}}
# {{docs-fragment report}}
REPORT_CSS = """
"""
def _cite(s: Source) -> str:
"""Render a rich You.com citation (Research or Search source)."""
if not s.url:
return ""
tag_cls = s.section if s.section in ("research", "news") else "web"
meta_bits = []
if s.published:
meta_bits.append(s.published[:10])
if s.title:
meta_bits.append(s.title)
meta = " · ".join(meta_bits)
snip = f"
Research answers from the You.com Research API (grounded
synthesis with inline citations) plus fresh headlines from the You.com
Search API (web + auto-classified news with timestamps and snippets).
"""
# {{/docs-fragment report}}
# {{docs-fragment driver}}
@env.task(report=True)
async def financial_research(
companies: list[str] = [
"NVIDIA",
"Advanced Micro Devices",
"Microsoft",
"Alphabet",
"Amazon",
"Meta Platforms",
"Broadcom",
"Taiwan Semiconductor Manufacturing",
],
focus: str = "Q4 earnings preview and competitive positioning",
research_effort: str = "standard",
freshness: str = "month",
) -> ResearchReport:
"""Fan out across companies and aggregate cited equity briefings."""
with flyte.group("research-companies"):
briefings = await asyncio.gather(
*[
research_company(c, focus, research_effort, freshness)
for c in companies
]
)
report = ResearchReport(briefings=list(briefings))
await flyte.report.replace.aio(_render_report(report), do_flush=True)
await flyte.report.flush.aio()
return report
# {{/docs-fragment driver}}
# {{docs-fragment main}}
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(financial_research)
print(run.url)
run.wait()
# {{/docs-fragment main}}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/financial_research_agent/main.py*
## Run the agent
### Create secrets
Get a You.com API key from the [You.com platform](https://you.com/platform) (see the [quickstart guide](https://you.com/docs/quickstart)). Get an Anthropic API key from the [Anthropic console](https://console.anthropic.com/).
Register both keys as Flyte secrets. The secret key names must match those declared in the `TaskEnvironment`:
```
flyte create secret youdotcom-api-key
flyte create secret internal-anthropic-api-key
```
See [Secrets](https://www.union.ai/docs/v2/union/user-guide/task-configuration/secrets/page.md) for scoping and file-based secrets.
### Run locally or remotely
From the [example directory](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/financial_research_agent):
```
cd v2/tutorials/financial_research_agent
uv run --script main.py
```
To test locally without Flyte secrets:
```
export YOU_API_KEY=
export ANTHROPIC_API_KEY=
uv run --script main.py
```
When the run completes, open the Flyte report to review equity briefings with thesis, risks, and You.com source citations for each company.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/frontier-ai ===
# Frontier AI
Tutorials for frontier-model pretraining, automated experimentation, and large-scale AI workloads.
### **Frontier AI > Distributed LLM pretraining**
Pretrain large language models at scale with PyTorch Lightning, FSDP, and H200 GPUs, featuring streaming data and real-time metrics.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/frontier-ai/distributed-pretraining ===
# Distributed LLM pretraining
When training large models, infrastructure should not be the hardest part. The real work is in the model architecture, the data, and the hyperparameters. In practice, though, teams often spend weeks just trying to get distributed training to run reliably.
And when it breaks, it usually breaks in familiar ways: out-of-memory crashes, corrupted checkpoints, data loaders that silently fail, or runs that hang with no obvious explanation.
Most distributed training tutorials focus on PyTorch primitives. This one focuses on getting something that actually ships. We go into the technical details, such as how FSDP shards parameters, why gradient clipping behaves differently at scale, and how streaming datasets reduce memory pressure, but always with the goal of building a system that works in production.
Real training jobs need more than a training loop. They need checkpointing, fault tolerance, data streaming, visibility into what’s happening, and the ability to recover from failures. In this tutorial, we build all of that using Flyte, without having to stand up or manage any additional infrastructure.
> [!NOTE]
> Full code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/pretraining/train.py).
## Overview
We're going to pretrain a GPT-2 style language model from scratch. This involves training on raw text data starting from randomly initialized weights, rather than fine-tuning or adapting a pretrained model. This is the same process used to train the original GPT-2, LLaMA, and most other foundation models.
The model learns by predicting the next token. Given "The cat sat on the", it learns to predict "mat". Do this billions of times across terabytes of text, and the model develops surprisingly sophisticated language understanding. That's pretraining.
The challenge is scale. A 30B parameter model doesn't fit on a single GPU. The training dataset, [SlimPajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B) in our case, is 627 billion tokens. Training runs last for days or even weeks. To make this work, you need:
- **Distributed training**: Split the model across multiple GPUs using [FSDP (Fully Sharded Data Parallel)](https://docs.pytorch.org/tutorials/intermediate/FSDP_tutorial.html)
- **Data streaming**: Pull training data on-demand instead of downloading terabytes upfront
- **Checkpointing**: Save progress regularly so a failure doesn’t wipe out days of compute
- **Observability**: See what's happening inside a multi-day training run
We’ll build a Flyte pipeline that takes care of all of this, using three tasks with clearly defined responsibilities:
1. **Data preparation**: Tokenizes your dataset and converts it to MDS (MosaicML Data Shard) format for streaming. This Flyte task is cached, so it only needs to be run once and can be reused across runs.
2. **Distributed training**: Runs FSDP across 8 H200 GPUs. Flyte's `Elastic` plugin handles the distributed setup. Checkpoints upload to S3 automatically via Flyte's `File` abstraction.
3. **Real-time reporting**: Streams loss curves and training metrics to Flyte Reports, a live dashboard integrated into the Flyte UI.
Why three separate tasks? Flyte makes this separation efficient:
- **Caching**: The data preparation step runs once. On subsequent runs, Flyte skips it entirely.
- **Resource isolation**: Training uses expensive H200 GPUs only while actively training, while the driver runs on inexpensive CPU instances.
- **Fault boundaries**: If training fails, the data preparation step does not re-run. Training can resume directly from the most recent checkpoint.
## Implementation
Let's walk through the code. We'll start with the infrastructure setup, build the model, then wire everything together into a pipeline.
### Setting up the environment
Every distributed training job needs a consistent environment across all nodes. Flyte handles this with container images:
```
import logging
import math
import os
from pathlib import Path
from typing import Optional
import flyte
import flyte.report
import lightning as L
import numpy as np
import torch
import torch.nn as nn
from flyte.io import Dir, File
from flyteplugins.pytorch.task import Elastic
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
The imports tell the story: `flyte` for orchestration, `flyte.report` for live dashboards, `lightning` for training loop management, and `Elastic` from Flyte's PyTorch plugin. This last one is key as it configures PyTorch's distributed launch without you writing any distributed setup code.
```
NUM_NODES = 1
DEVICES_PER_NODE = 8
VOCAB_SIZE = (
50257 # GPT-2 BPE tokenizer vocabulary size (constant across all model sizes)
)
N_POSITIONS = 2048 # Maximum sequence length (constant across all model sizes)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
These constants define the distributed topology. We're using 1 node with 8 GPUs, but you can scale this up by changing `NUM_NODES`. The vocabulary size (50,257 tokens) and sequence length (2,048 tokens) match GPT-2's [Byte Pair Encoding (BPE) tokenizer](https://huggingface.co/learn/llm-course/en/chapter6/5).
```
image = flyte.Image.from_debian_base(
name="distributed_training_h200"
).with_pip_packages(
"transformers==4.57.3",
"datasets==4.4.1",
"tokenizers==0.22.1",
"huggingface-hub==0.34.0",
"mosaicml-streaming>=0.7.0",
"pyarrow==22.0.0",
"flyteplugins-pytorch>=2.0.0b33",
"torch==2.9.1",
"lightning==2.5.6",
"tensorboard==2.20.0",
"sentencepiece==0.2.1",
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
Flyte builds this container automatically when the pipeline is run. All dependencies required for distributed training, including PyTorch, Lightning, the streaming library, and NCCL for GPU communication, are baked in. There's no Dockerfile to maintain and no "works on my machine" debugging.
### Declaring resource requirements
Different parts of the pipeline need different resources. Data tokenization needs CPU and memory. Training needs GPUs. The driver just coordinates. Flyte's `TaskEnvironment` lets you declare exactly what each task needs:
```
data_loading_env = flyte.TaskEnvironment(
name="data_loading_h200",
image=image,
resources=flyte.Resources(cpu=5, memory="28Gi", disk="100Gi"),
env_vars={
"HF_DATASETS_CACHE": "/tmp/hf_cache", # Cache directory for datasets
"TOKENIZERS_PARALLELISM": "true", # Enable parallel tokenization
},
cache="auto",
)
distributed_llm_training_env = flyte.TaskEnvironment(
name="distributed_llm_training_h200",
image=image,
resources=flyte.Resources(
cpu=64,
memory="512Gi",
gpu=f"H200:{DEVICES_PER_NODE}",
disk="1Ti",
shm="16Gi", # Explicit shared memory for NCCL communication
),
plugin_config=Elastic(nnodes=NUM_NODES, nproc_per_node=DEVICES_PER_NODE),
env_vars={
"TORCH_DISTRIBUTED_DEBUG": "INFO",
"NCCL_DEBUG": "WARN",
},
cache="auto",
)
driver_env = flyte.TaskEnvironment(
name="llm_training_driver",
image=image,
resources=flyte.Resources(cpu=2, memory="4Gi"),
cache="auto",
depends_on=[data_loading_env, distributed_llm_training_env],
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
Let's break down the training environment, since this is where most of the complexity lives:
- **`gpu=f"H200:{DEVICES_PER_NODE}"`**: Flyte provisions exactly 8 H200 GPUs. These have 141GB of memory each, enough to train 30B+ parameter models with FSDP.
- **`shm="16Gi"`**: This allocates explicit shared memory. NCCL (NVIDIA's communication library) uses shared memory for inter-GPU communication on the same node. Without this, you'll see cryptic errors like "NCCL error: unhandled system error", which can be difficult to debug.
- **`Elastic(nnodes=NUM_NODES, nproc_per_node=DEVICES_PER_NODE)`**: This is Flyte's integration with PyTorch's elastic launch. It handles process spawning (one process per GPU), rank assignment (each process knows its ID), and environment setup (master address, world size). This replaces the boilerplate typically written in shell scripts.
The `driver_env` is intentionally lightweight, using 2 CPUs and 4 GB of memory. Its role is limited to orchestrating tasks and passing data between them, so allocating GPUs here would be unnecessary.
### Model configurations
Training a 1.5B model uses different hyperparameters than training a 65B model. Rather than hardcoding values, we define presets:
```
MODEL_CONFIGS = {
"1.5B": {
"n_embd": 2048,
"n_layer": 24,
"n_head": 16,
"batch_size": 8,
"learning_rate": 6e-4,
"checkpoint_every_n_steps": 10,
"report_every_n_steps": 5,
"val_check_interval": 100,
}, # Good for testing and debugging
"30B": {
"n_embd": 6656,
"n_layer": 48,
"n_head": 52,
"batch_size": 1,
"learning_rate": 1.6e-4,
"checkpoint_every_n_steps": 7500,
"report_every_n_steps": 200,
"val_check_interval": 1000,
},
"65B": {
"n_embd": 8192,
"n_layer": 80,
"n_head": 64,
"batch_size": 1,
"learning_rate": 1.5e-4,
"checkpoint_every_n_steps": 10000,
"report_every_n_steps": 250,
"val_check_interval": 2000,
},
}
def get_model_config(model_size: str) -> dict:
if model_size not in MODEL_CONFIGS:
available = ", ".join(MODEL_CONFIGS.keys())
raise ValueError(f"Unknown model size: {model_size}. Available: {available}")
return MODEL_CONFIGS[model_size]
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
A few things to notice:
- **Batch size decreases with model size**: For a fixed GPU memory budget, larger models consume more memory for parameters, optimizer state, and activations, leaving less room for per-GPU batch size. For example, a 1.5B parameter model may fit a batch size of 8 per GPU, while a 65B model may only fit a batch size of 1. This is typically compensated for using gradient accumulation to maintain a larger effective batch size.
- **Learning rate decreases with model size**: Larger models are more sensitive to optimization instability and typically require lower learning rates. The values here follow empirical best practices used in large-scale language model training, informed by work such as the [Chinchilla study](https://arxiv.org/pdf/2203.15556) on compute-optimal scaling.
- **Checkpoint frequency increases with model size**: Checkpointing a 65B model is expensive (the checkpoint is huge). We do it less often but make sure we don't lose too much progress if something fails.
The 1.5B config is good for testing your setup before committing to a serious training run.
### Building the GPT model
Now for the model itself. We're building a GPT-2 style decoder-only transformer from scratch.
First, the configuration class:
```
class GPTConfig:
"""Configuration for GPT model."""
def __init__(
self,
vocab_size: int = VOCAB_SIZE,
n_positions: int = N_POSITIONS,
n_embd: int = 2048,
n_layer: int = 24,
n_head: int = 16,
n_inner: Optional[int] = None,
activation_function: str = "gelu_new",
dropout: float = 0.1,
layer_norm_epsilon: float = 1e-5,
):
self.vocab_size = vocab_size
self.n_positions = n_positions
self.n_embd = n_embd
self.n_layer = n_layer
self.n_head = n_head
self.n_inner = n_inner if n_inner is not None else 4 * n_embd
self.activation_function = activation_function
self.dropout = dropout
self.layer_norm_epsilon = layer_norm_epsilon
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
The key architectural parameters:
- **`n_embd`**: The hidden (embedding) dimension. Larger values increase model capacity but also increase memory and compute requirements.
- **`n_layer`**: The number of transformer blocks. Model depth strongly influences expressiveness and performance.
- **`n_head`**: The number of attention heads. Each head can attend to different patterns or relationships in the input.
- **`n_inner`**: The hidden dimension of the feed-forward network (MLP), typically set to 4x the embedding dimension.
Next, we define a single transformer block:
```
class GPTBlock(nn.Module):
"""Transformer block with causal self-attention."""
def __init__(self, config: GPTConfig):
super().__init__()
self.ln_1 = nn.LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)
self.attn = nn.MultiheadAttention(
config.n_embd,
config.n_head,
dropout=config.dropout,
batch_first=True,
)
self.ln_2 = nn.LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)
# Get activation function from config
ACT_FNS = {
"gelu": nn.GELU(),
"gelu_new": nn.GELU(approximate="tanh"), # GPT-2 uses approximate GELU
"relu": nn.ReLU(),
"silu": nn.SiLU(),
"swish": nn.SiLU(), # SiLU = Swish
}
act_fn = ACT_FNS.get(config.activation_function, nn.GELU())
self.mlp = nn.Sequential(
nn.Linear(config.n_embd, config.n_inner),
act_fn,
nn.Linear(config.n_inner, config.n_embd),
nn.Dropout(config.dropout),
)
def forward(self, x, causal_mask, key_padding_mask=None):
x_normed = self.ln_1(x)
# Self-attention with causal and padding masks
attn_output, _ = self.attn(
x_normed, # query
x_normed, # key
x_normed, # value
attn_mask=causal_mask, # Causal mask: (seq_len, seq_len)
key_padding_mask=key_padding_mask, # Padding mask: (batch, seq_len)
need_weights=False,
)
x = x + attn_output
# MLP with residual
x = x + self.mlp(self.ln_2(x))
return x
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
Each block has two sub-layers: causal self-attention and a feed-forward MLP. The causal mask ensures the model can only attend to previous tokens in the sequence, so it can't "cheat" by looking at the answer. This is what makes it *autoregressive*.
The full `GPTModel` class (see the complete code) stacks these blocks and adds token and positional embeddings. One important detail is that the input token embedding matrix is shared with the output projection layer (often called [weight tying](https://mbrenndoerfer.com/writing/weight-tying-shared-embeddings-transformers)). This reduces the number of parameters by roughly 50 million for typical vocabulary sizes and often leads to better generalization and more stable training.
### The Lightning training module
PyTorch Lightning handles the training loop boilerplate. We wrap our model in a `LightningModule` that defines how to train it:
```
class GPTPreTrainingModule(L.LightningModule):
"""PyTorch Lightning module for GPT pre-training."""
def __init__(
self,
vocab_size: int = 50257,
n_positions: int = 2048,
n_embd: int = 2048,
n_layer: int = 24,
n_head: int = 16,
learning_rate: float = 6e-4,
weight_decay: float = 0.1,
warmup_steps: int = 2000,
max_steps: int = 100000,
):
super().__init__()
self.save_hyperparameters()
config = GPTConfig(
vocab_size=vocab_size,
n_positions=n_positions,
n_embd=n_embd,
n_layer=n_layer,
n_head=n_head,
)
self.model = GPTModel(config)
def forward(self, input_ids, attention_mask=None):
return self.model(input_ids, attention_mask)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
The `save_hyperparameters()` call is important because it stores all constructor arguments in the checkpoint. This allows the model to be reloaded later without having to manually reconstruct the original configuration.
The training and validation steps implement standard causal language modeling, where the model is trained to predict the next token given all previous tokens in the sequence.
```
def training_step(self, batch, _batch_idx):
# Convert int32 to int64 (long) - MDS stores as int32 but PyTorch expects long
input_ids = batch["input_ids"].long()
labels = batch["labels"].long()
# Get attention mask if present (optional, for padded sequences)
# attention_mask: 1 = real token, 0 = padding
# Note: Current data pipeline creates fixed-length sequences without padding,
# so attention_mask is not present. If using padded sequences, ensure:
# - Padded positions in labels are set to -100 (ignored by cross_entropy)
# - attention_mask marks real tokens (1) vs padding (0)
attention_mask = batch.get("attention_mask", None)
# Forward pass (causal mask is created internally in GPTModel)
logits = self(input_ids, attention_mask=attention_mask)
# Shift logits and labels for causal language modeling
# Before shift: labels[i] = input_ids[i]
# After shift: predict input_ids[i+1] from input_ids[:i+1]
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Calculate loss
loss = nn.functional.cross_entropy(
shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1),
ignore_index=-100,
)
# Log loss
self.log(
"train/loss",
loss,
on_step=True,
on_epoch=True,
prog_bar=True,
sync_dist=True,
)
# Calculate and log perplexity only on epoch (exp is costly, less frequent is fine)
perplexity = torch.exp(torch.clamp(loss, max=20.0))
self.log(
"train/perplexity",
perplexity,
on_step=False,
on_epoch=True,
prog_bar=True,
sync_dist=True,
)
return loss
def validation_step(self, batch, _batch_idx):
# Convert int32 to int64 (long) - MDS stores as int32 but PyTorch expects long
input_ids = batch["input_ids"].long()
labels = batch["labels"].long()
# Get attention mask if present (optional, for padded sequences)
attention_mask = batch.get("attention_mask", None)
# Forward pass (causal mask is created internally in GPTModel)
logits = self(input_ids, attention_mask=attention_mask)
# Shift logits and labels
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Calculate loss
loss = nn.functional.cross_entropy(
shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1),
ignore_index=-100,
)
# Log loss
self.log("val/loss", loss, prog_bar=True, sync_dist=True)
# Calculate and log perplexity (exp is costly, but validation is infrequent so OK)
perplexity = torch.exp(torch.clamp(loss, max=20.0))
self.log("val/perplexity", perplexity, prog_bar=True, sync_dist=True)
return loss
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
The model performs a forward pass with a causal (autoregressive) mask created internally, ensuring each token can only attend to earlier positions. To align predictions with targets, the logits and labels are shifted so that the representation at position `i` is used to predict token `i + 1`.
Loss is computed using cross-entropy over the shifted logits and labels. Training loss and perplexity are logged during execution, with metrics synchronized across distributed workers.
The optimizer setup is where a lot of training stability comes from:
```
def configure_optimizers(self):
# Separate parameters into weight decay and no weight decay groups
decay_params = []
no_decay_params = []
for param in self.model.parameters():
if param.requires_grad:
# 1D parameters (biases, LayerNorm) don't get weight decay
# 2D+ parameters (weight matrices) get weight decay
if param.ndim == 1:
no_decay_params.append(param)
else:
decay_params.append(param)
optimizer_grouped_parameters = [
{"params": decay_params, "weight_decay": self.hparams.weight_decay},
{"params": no_decay_params, "weight_decay": 0.0},
]
# AdamW optimizer
optimizer = torch.optim.AdamW(
optimizer_grouped_parameters,
lr=self.hparams.learning_rate,
betas=(0.9, 0.95),
eps=1e-8,
)
# Learning rate scheduler: warmup + cosine decay
# Warmup: linear increase from 0 to 1.0 over warmup_steps
# Decay: cosine decay from 1.0 to 0.0 over remaining steps
def lr_lambda(current_step):
if current_step < self.hparams.warmup_steps:
# Linear warmup
return float(current_step) / float(max(1, self.hparams.warmup_steps))
# Cosine decay after warmup
progress = (current_step - self.hparams.warmup_steps) / max(
1, self.hparams.max_steps - self.hparams.warmup_steps
)
# Cosine annealing from 1.0 to 0.0 (returns float, not tensor)
return 0.5 * (1.0 + math.cos(progress * math.pi))
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
return {
"optimizer": optimizer,
"lr_scheduler": {
"scheduler": scheduler,
"interval": "step",
},
}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
Two important choices here:
1. **Separate weight decay groups**: We only apply weight decay to the weight matrices, not to biases or LayerNorm parameters. This follows the original BERT paper and is now standard practice, as regularizing biases and normalization parameters does not improve performance and can be harmful.
2. **Cosine learning rate schedule with warmup**: We start with a low learning rate, ramp up linearly during warmup (helps stabilize early training when gradients are noisy), then decay following a cosine curve. This schedule outperforms constant or step decay for transformer training.
### Checkpointing for fault tolerance
Training a 30B-parameter model for 15,000 steps can take days. Hardware failures and spot instance preemptions are inevitable, which makes checkpointing essential.
```
class S3CheckpointCallback(L.Callback):
"""
Periodically upload checkpoints to S3 for durability and resumption.
This ensures checkpoints are safely stored in remote storage even if
the training job is interrupted or the instance fails.
"""
def __init__(self, checkpoint_dir: Path, upload_every_n_steps: int):
super().__init__()
self.checkpoint_dir = checkpoint_dir
self.upload_every_n_steps = upload_every_n_steps
self.last_uploaded_step = -1
def on_train_batch_end(self, trainer, pl_module, outputs, batch, batch_idx):
"""Upload checkpoint to S3 every N steps."""
if trainer.global_rank != 0:
return # Only upload from rank 0
current_step = trainer.global_step
# Upload every N steps (aligns with ModelCheckpoint's every_n_train_steps)
if (
current_step % self.upload_every_n_steps == 0
and current_step > self.last_uploaded_step
and current_step > 0
):
try:
# Find the most recent checkpoint file
checkpoint_files = list(self.checkpoint_dir.glob("*.ckpt"))
if not checkpoint_files:
print("No checkpoint files found to upload")
return
# Get the latest checkpoint (by modification time)
latest_checkpoint = max(
checkpoint_files, key=lambda p: p.stat().st_mtime
)
# Upload the checkpoint file directly to S3 using File.from_local_sync
checkpoint_file = File.from_local_sync(str(latest_checkpoint))
print(f"Checkpoint uploaded to S3 at: {checkpoint_file.path}")
self.last_uploaded_step = current_step
except Exception as e:
print(f"Warning: Failed to upload checkpoint to S3: {e}")
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
This callback runs every `N` training steps and uploads the checkpoint to durable storage. The key line is `File.from_local_sync()` which is a Flyte abstraction for uploading files. There are no blob store credentials to manage and no bucket paths to hardcode. Flyte automatically uses the storage backend configured for your cluster.
The callback only runs on rank 0. In distributed training, all 8 GPUs have identical model states (that's the point of data parallelism). Having all of them upload the same checkpoint would be wasteful and could cause race conditions.
When you restart a failed run, pass the checkpoint via `resume_checkpoint` so training resumes exactly where it left off, including the same step count, optimizer state, and learning rate schedule position.
### Real-time metrics with Flyte reports
Multi-day training runs need observability. Is the loss decreasing? Did training diverge? Is the learning rate schedule behaving correctly? Flyte Reports let you build live dashboards directly in the UI:
```
class FlyteReportingCallback(L.Callback):
"""Custom Lightning callback to report training metrics to Flyte Report."""
def __init__(self, report_every_n_steps: int = 100):
super().__init__()
self.report_every_n_steps = report_every_n_steps
self.metrics_history = {
"step": [],
"train_loss": [],
"learning_rate": [],
"val_loss": [],
"val_perplexity": [],
}
self.initialized_report = False
self.last_logged_step = -1
def on_train_start(self, trainer, pl_module):
"""Initialize the live dashboard on training start."""
if trainer.global_rank == 0 and not self.initialized_report:
self._initialize_report()
self.initialized_report = True
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
The `_initialize_report` method (see complete code) creates an HTML/JavaScript dashboard with interactive charts. The callback then calls `flyte.report.log()` every `N` steps to push new metrics. The charts update in real-time so you can watch your loss curve descend while training runs.
There is no need to deploy Grafana, configure Prometheus, or keep a TensorBoard server running. Using `flyte.report.log()` is sufficient to get live training metrics directly in the Flyte UI.
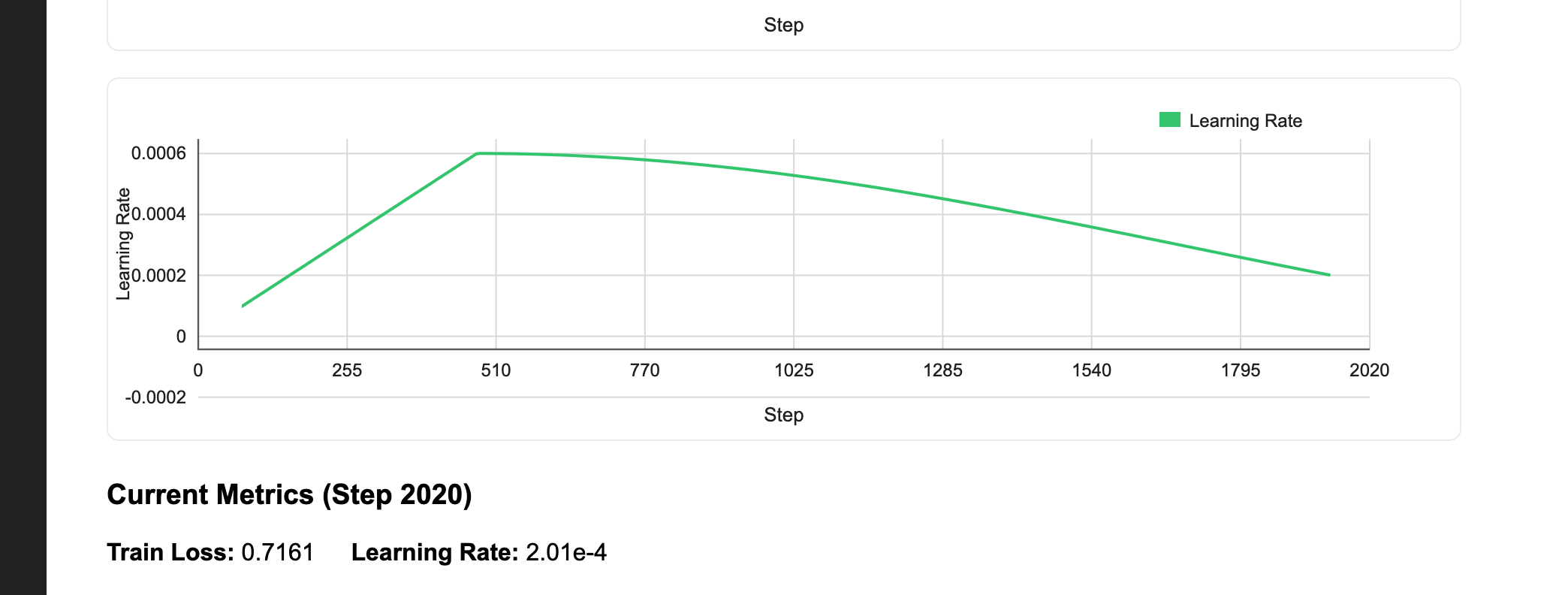
### Streaming data at scale
Training datasets are massive. SlimPajama contains 627 billion tokens and spans hundreds of gigabytes even when compressed. Downloading the entire dataset to each training node before starting would take hours and waste storage.
Instead, we convert the data to MDS (MosaicML Data Shard) format and stream it during training:
```
@data_loading_env.task
async def load_and_prepare_streaming_dataset(
dataset_name: str,
dataset_config: Optional[str],
max_length: int,
train_split: str,
val_split: Optional[str],
max_train_samples: Optional[int],
max_val_samples: Optional[int],
shard_size_mb: int,
) -> Dir:
"""Tokenize dataset and convert to MDS format for streaming."""
from datasets import load_dataset
from streaming import MDSWriter
from transformers import GPT2TokenizerFast
output_dir = Path("/tmp/streaming_dataset")
output_dir.mkdir(parents=True, exist_ok=True)
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
# MDS schema: what each sample contains
columns = {
"input_ids": "ndarray:int32",
"labels": "ndarray:int32",
}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
This task does three things:
1. **Tokenizes the text** using GPT-2's BPE tokenizer
2. **Concatenates documents** into fixed-length sequences (no padding waste)
3. **Writes shards** to storage in a format optimized for streaming
The task returns a Flyte `Dir` object, which is a reference to the output location. It's not the data itself, just a pointer. When the training task receives this `Dir`, it streams shards on-demand rather than downloading everything upfront.
Flyte caches this task automatically. Run the pipeline twice with the same dataset config, and Flyte skips tokenization entirely on the second run. Change the dataset or sequence length, and it re-runs.
### Distributed training with FSDP
Now we get to the core: actually training the model across multiple GPUs. FSDP is what makes this possible for large models.
```
@distributed_llm_training_env.task(report=True)
def train_distributed_llm(
prepared_dataset: Dir,
resume_checkpoint: Optional[Dir],
vocab_size: int,
n_positions: int,
n_embd: int,
n_layer: int,
n_head: int,
batch_size: int,
num_workers: int,
max_steps: int,
learning_rate: float,
weight_decay: float,
warmup_steps: int,
use_fsdp: bool,
checkpoint_upload_steps: int,
checkpoint_every_n_steps: int,
report_every_n_steps: int,
val_check_interval: int,
grad_accumulation_steps: int = 1,
) -> Optional[Dir]:
# ... setup code ...
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
Notice `report=True` on the task decorator. It enables Flyte Reports for this specific task.
The training task receives the prepared dataset as a `Dir` and streams data directly from storage:
```
# StreamingDataset streams shards from the remote Flyte storage on-demand
# It automatically detects torch.distributed context
# and shards data across GPUs - each rank gets different data automatically
train_dataset = StreamingDataset(
remote=f"{remote_path}/train", # Remote MDS shard location
local=str(local_cache / "train"), # Local cache for downloaded shards
shuffle=True, # Shuffle samples
shuffle_algo="naive", # Shuffling algorithm
batch_size=batch_size, # Used for shuffle buffer sizing
)
# Create validation StreamingDataset if it exists
val_dataset = None
try:
val_dataset = StreamingDataset(
remote=f"{remote_path}/validation",
local=str(local_cache / "validation"),
shuffle=False, # No shuffling for validation
batch_size=batch_size,
)
print(
f"Validation dataset initialized with streaming from: {remote_path}/validation"
)
except Exception as e:
print(f"No validation dataset found: {e}")
# Create data loaders
# StreamingDataset handles distributed sampling internally by detecting
# torch.distributed.get_rank() and torch.distributed.get_world_size()
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
num_workers=num_workers,
pin_memory=True,
persistent_workers=True,
drop_last=True, # Drop incomplete batches for distributed training
collate_fn=mds_collate_fn, # Handle read-only arrays
)
# Create validation loader if validation dataset exists
val_loader = None
if val_dataset is not None:
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
num_workers=num_workers,
pin_memory=True,
persistent_workers=True,
drop_last=False,
collate_fn=mds_collate_fn,
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
`prepared_dataset.path` provides the remote storage path for the dataset. MosaicML's `StreamingDataset` automatically shards data across GPUs so that each rank sees different samples, without requiring a manual distributed sampler. The credentials are already in the environment because Flyte set them up.
FSDP is where the memory magic happens. Instead of each GPU holding a full copy of the model (like Distributed Data Parallel (DDP)), FSDP shards the parameters, gradients, and optimizer states across all GPUs. Each GPU only holds 1/8th of the model. When a layer needs to run, FSDP all-gathers the full parameters, runs the computation, then discards them.
```
# Configure distributed strategy
if use_fsdp:
from torch.distributed.fsdp.wrap import ModuleWrapPolicy
strategy = FSDPStrategy(
auto_wrap_policy=ModuleWrapPolicy([GPTBlock]),
activation_checkpointing_policy=None,
cpu_offload=False, # H200 has 141GB - no CPU offload needed
state_dict_type="full",
sharding_strategy="FULL_SHARD",
process_group_backend="nccl",
)
else:
from lightning.pytorch.strategies import DDPStrategy
strategy = DDPStrategy(process_group_backend="nccl")
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
We wrap at the `GPTBlock` level because each transformer block becomes an FSDP unit. This balances communication overhead (more units = more all-gathers) against memory savings (smaller units = more granular sharding).
One subtle detail: gradient clipping. With FSDP, gradients are sharded across ranks, so computing a global gradient norm would require an expensive all-reduce operation. Instead of norm-based clipping, we use value-based gradient clipping, which clamps each individual gradient element to a fixed range. This can be done independently on each rank with no coordination overhead and is commonly used for large-scale FSDP training.
```
# Initialize trainer
trainer = L.Trainer(
strategy=strategy,
accelerator="gpu",
devices=DEVICES_PER_NODE,
num_nodes=NUM_NODES,
# Training configuration
max_steps=max_steps,
precision="bf16-mixed", # BFloat16 for better numerical stability
# Optimization
gradient_clip_val=1.0,
gradient_clip_algorithm=(
"value" if use_fsdp else "norm"
), # FSDP requires 'value', DDP can use 'norm'
accumulate_grad_batches=grad_accumulation_steps,
# Logging and checkpointing
callbacks=callbacks,
log_every_n_steps=report_every_n_steps,
val_check_interval=val_check_interval,
# Performance
benchmark=True,
deterministic=False,
# Enable gradient checkpointing for memory efficiency
enable_checkpointing=True,
use_distributed_sampler=False, # StreamingDataset handles distributed sampling
)
# Train the model (resume from checkpoint if provided)
trainer.fit(model, train_loader, val_loader, ckpt_path=ckpt_path)
# Print final results
if trainer.global_rank == 0:
if val_loader is not None:
print(
f"Final validation loss: {trainer.callback_metrics.get('val/loss', 0.0):.4f}"
)
print(
f"Final validation perplexity: {trainer.callback_metrics.get('val/perplexity', 0.0):.4f}"
)
print(f"Checkpoints saved to: {checkpoint_dir}")
return Dir.from_local_sync(output_dir)
return None
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
The trainer configuration brings together all the pieces we've discussed:
- **`precision="bf16-mixed"`**: BFloat16 mixed precision training. BF16 has the same dynamic range as FP32 (unlike FP16), so you don't need loss scaling. This is the standard choice for modern GPU training.
- **`gradient_clip_val=1.0`**: Clips gradients to prevent exploding gradients during training. Combined with value-based clipping for FSDP compatibility.
- **`accumulate_grad_batches`**: Accumulates gradients over multiple forward passes before updating weights. This lets us hit a larger effective batch size than what fits in GPU memory.
- **`val_check_interval`**: How often to run validation. For long training runs, you don't want to validate every epoch — that would be too infrequent. Instead, validate every `N` training steps.
- **`use_distributed_sampler=False`**: We disable Lightning's built-in distributed sampler because `StreamingDataset` handles data sharding internally. Using both would cause conflicts.
- **`benchmark=True`**: Enables cuDNN autotuning. PyTorch will benchmark different convolution algorithms on the first batch and pick the fastest one for your specific input sizes.
The trainer then calls `fit()` with the model, data loaders, and optionally a checkpoint path to resume from.
### Tying it together
The pipeline task orchestrates everything:
```
@driver_env.task
async def distributed_llm_pipeline(
model_size: str,
dataset_name: str = "Salesforce/wikitext",
dataset_config: str = "wikitext-103-raw-v1",
max_length: int = 2048,
max_train_samples: Optional[int] = 10000,
max_val_samples: Optional[int] = 1000,
max_steps: int = 100000,
resume_checkpoint: Optional[Dir] = None,
checkpoint_upload_steps: int = 1000,
# Optional overrides (if None, uses model preset defaults)
batch_size: Optional[int] = None,
learning_rate: Optional[float] = None,
use_fsdp: bool = True,
) -> Optional[Dir]:
# Get model configuration
model_config = get_model_config(model_size)
# Use preset values if not overridden
actual_batch_size = (
batch_size if batch_size is not None else model_config["batch_size"]
)
actual_learning_rate = (
learning_rate if learning_rate is not None else model_config["learning_rate"]
)
# Step 1: Load and prepare streaming dataset
prepared_dataset = await load_and_prepare_streaming_dataset(
dataset_name=dataset_name,
dataset_config=dataset_config,
max_length=max_length,
train_split="train",
val_split="validation",
max_train_samples=max_train_samples,
max_val_samples=max_val_samples,
shard_size_mb=64, # 64MB shards
)
# Step 2: Run distributed training
if resume_checkpoint is not None:
print("\nStep 2: Resuming distributed training from checkpoint...")
else:
print("\nStep 2: Starting distributed training from scratch...")
target_global_batch = 256
world_size = NUM_NODES * DEVICES_PER_NODE
effective_per_step = world_size * actual_batch_size
grad_accumulation_steps = max(
1, math.ceil(target_global_batch / max(1, effective_per_step))
)
checkpoint_dir = train_distributed_llm(
prepared_dataset=prepared_dataset,
resume_checkpoint=resume_checkpoint,
vocab_size=VOCAB_SIZE,
n_positions=N_POSITIONS,
n_embd=model_config["n_embd"],
n_layer=model_config["n_layer"],
n_head=model_config["n_head"],
batch_size=actual_batch_size,
num_workers=8,
max_steps=max_steps,
learning_rate=actual_learning_rate,
weight_decay=0.1,
warmup_steps=500,
use_fsdp=use_fsdp,
checkpoint_upload_steps=checkpoint_upload_steps,
checkpoint_every_n_steps=model_config["checkpoint_every_n_steps"],
report_every_n_steps=model_config["report_every_n_steps"],
val_check_interval=model_config["val_check_interval"],
grad_accumulation_steps=grad_accumulation_steps,
)
return checkpoint_dir
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
The flow is straightforward: load the configuration, prepare the data, and run training. Flyte automatically manages the execution graph so data preparation runs first and training waits until it completes. If data preparation is cached from a previous run, training starts immediately.
The gradient accumulation calculation is worth noting. We want a global batch size of 256 (this affects training dynamics), but each GPU can only fit a small batch. With 8 GPUs and batch size 1 each, we need 32 accumulation steps to hit 256.
## Running the pipeline
With everything defined, running is simple:
```
if __name__ == "__main__":
flyte.init_from_config()
run = flyte.run(
distributed_llm_pipeline,
model_size="30B",
dataset_name="cerebras/SlimPajama-627B",
dataset_config=None,
max_length=2048,
max_train_samples=5_000_000,
max_val_samples=50_000,
max_steps=15_000,
use_fsdp=True,
checkpoint_upload_steps=1000,
)
print(f"Run URL: {run.url}")
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/pretraining/train.py*
This configuration is designed for testing and demonstration. Notice `max_train_samples=5_000_000` — that's 5 million samples from a dataset with 627 billion tokens. A tiny fraction, enough to verify everything works without burning through compute.
For a real pretraining run, you would remove this limit by setting `max_train_samples=None`, or increase it significantly. You would also increase `max_steps` to match your compute budget, likely scale to multiple nodes by setting `NUM_NODES=4` or higher, and allocate more resources. The rest of the pipeline remains unchanged.
```bash
flyte create config --endpoint --project --domain --builder remote
uv run train.py
```
When you run this, Flyte:
1. **Builds the container** (cached after first run)
2. **Schedules data prep** on CPU nodes
3. **Waits for data prep** (or skips if cached)
4. **Provisions H200 nodes** and launches distributed training
5. **Streams logs and metrics** to the UI in real-time
Open the Flyte UI to observe the workflow execution. The data preparation task completes first, followed by the training task spinning up. As training begins, the Flyte Reports dashboard starts plotting loss curves. If anything goes wrong, the logs are immediately available in the UI.
If training fails due to an out-of-memory error, a GPU driver error, or a hardware issue, check the logs, fix the problem, and restart the run with `resume_checkpoint` pointing to the most recent checkpoint. Training resumes from where it left off. Flyte tracks the full execution history, so it is easy to see exactly what happened.
## Going further
If you've run through this tutorial, here's where to go next depending on what you're trying to do:
**You want to train on your own data.** The data prep task accepts any HuggingFace dataset with a `text` column. If your data isn't on HuggingFace, you can modify `load_and_prepare_streaming_dataset` to read from S3, local files, or any other source. The key is getting your data into MDS format. Once it's there, the streaming and sharding just works. For production training, look at SlimPajama, [RedPajama](https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T), or [The Pile](https://huggingface.co/datasets/EleutherAI/pile) as starting points.
**You want to scale to more GPUs.** Bump `NUM_NODES` and Flyte handles the rest. The main thing to watch is the effective batch size. As you add more GPUs, you may want to reduce gradient accumulation steps to keep the same global batch size, or increase them if you want to experiment with larger batches.
**Your training keeps failing.** Add `retries=3` to your task decorator for automatic retry on transient failures. This handles spot instance preemption, temporary network issues, and the occasional GPU that decides to stop working. Combined with checkpointing, you get fault-tolerant training that can survive most infrastructure hiccups. For persistent failures, the Flyte UI logs are your friend as they capture stdout/stderr from all ranks.
**You want better visibility into what's happening.** We're actively working on surfacing GPU driver logs (xid/sxid errors), memory utilization breakdowns, and NCCL communication metrics directly in the Flyte UI. If you're hitting issues that the current logs don't explain, reach out. Your feedback helps us prioritize what observability features to build next!
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/computer-vision ===
# Computer vision
Tutorials for image and vision-language model workloads.
### **Computer vision > Fine-tuning a VLM**
Adapt Qwen2.5-VL to occluded image classification by training a 10K-parameter adapter with multi-node DeepSpeed, automatic recovery, and live training dashboards.
### **Computer vision > RT-DETR object detection**
Fine-tune RT-DETRv2 on a COCO dataset with live training charts, mAP evaluation, and bounding-box demos.
### **Computer vision > Multimodal retrieval evaluation**
Benchmark ColPali, SigLIP, and OCR+BM25 visual document retrieval on ViDoRe with warm GPU containers, dynamic batching, and an interactive report.
=== PAGE: https://www.union.ai/docs/v2/union/tutorials/computer-vision/qwen-vl-finetuning ===
# Fine-tuning a VLM
Large vision-language models like Qwen2.5-VL are remarkably capable out of the box. But adapting one to a specialized task raises an immediate question: do you really need to update 3 billion parameters?
Usually, no. The **frozen backbone pattern** is a practical alternative: keep all pretrained weights frozen and train only a small, task-specific adapter inserted before the vision encoder. The adapter learns to transform its input in a way that makes the frozen model perform well on your task without touching the underlying billions of parameters. The result is faster training, lower memory pressure, and a much smaller set of weights to store and version.
This tutorial makes that pattern concrete. We take a partially-occluded image classification task — CIFAR-10 images with random black rectangles covering 22–45% of the frame — and train a tiny Conv2d adapter to "see through" the occlusion before the frozen VLM processes it. The adapter has approximately **10,500 trainable parameters**. The backbone has 3 billion.
The machine learning is interesting, but the real focus here is on shipping a production-grade training pipeline:
- **Multi-node distributed training** across 2 nodes × 4 GPUs using PyTorch Elastic and DeepSpeed Stage 2
- **Automatic fault tolerance**: checkpoints upload to object storage after every validation epoch; if training fails, the pipeline returns the last known-good checkpoint instead of crashing
- **Live observability**: a streaming HTML dashboard in the Flyte UI updates in real-time as training runs, no separate monitoring infrastructure required
- **Cached data preparation**: dataset processing runs once and is reused across all reruns
- **Clean task isolation**: each stage runs with exactly the resources it needs, nothing more
> [!NOTE]
> Full code available [here](https://github.com/unionai/unionai-examples/tree/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning).
## Overview
The pipeline has four tasks with clearly defined responsibilities:
1. **Dataset preparation** (`prepare_occlusion_dataset`): Downloads CIFAR-10, applies random occlusions, and writes image manifests as streaming JSONL files to object storage. Runs on CPU and is cached, so it only runs once regardless of how many times you rerun the pipeline with the same config.
2. **Multi-node training** (`train_qwen_adapter_multinode`): Runs PyTorch Lightning with DeepSpeed Stage 2 across 2 nodes × 4 L40s GPUs. Only the adapter trains; the 3B backbone stays frozen.
3. **Evaluation** (`evaluate_qwen_adapter`): Loads the saved adapter, runs inference on validation examples, and produces a predictions report. Runs on a single GPU.
4. **Driver** (`qwen_vl_multinode_deepspeed`): The pipeline entry point. Orchestrates the three tasks above, manages WandB initialization, handles recovery from training failures, and produces a final HTML report in the Flyte UI.
Why this separation? It mirrors how production pipelines should be structured. Data prep is cheap and deterministic so we cache it. Training is expensive and failure-prone so we isolate it with fault tolerance. Evaluation needs different hardware than training. The driver is pure coordination, so it gets minimal resources.
## Implementation
### Setting up the environment
Different tasks need different compute. Flyte's `TaskEnvironment` is how you declare exactly what each task needs.
First, define the container images. Training needs a full CUDA stack with ML libraries, driver compatibility, and DeepSpeed's build tools:
```
gpu_image = (
flyte.Image.from_base("nvidia/cuda:12.8.0-cudnn-devel-ubuntu22.04")
.clone(name="qwen_vl_multinode_deepspeed", python_version=(3, 13), extendable=True)
.with_apt_packages("build-essential")
.with_pip_packages(
"torch==2.9.1",
"torchvision==0.24.1",
"lightning==2.6.1",
"transformers==4.57.3",
"deepspeed==0.18.8",
"datasets==4.4.1",
"pillow==11.3.0",
"flyteplugins-pytorch>=2.0.11",
"flyteplugins-jsonl>=2.0.11",
"flyteplugins-wandb>=2.0.11",
)
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/config.py*
`from_base` starts from the official NVIDIA CUDA image, giving you NCCL, cuDNN, and the right driver headers out of the box. `with_apt_packages("build-essential")` is required because DeepSpeed compiles CUDA kernels at first use and without build tools, it silently falls back to slower CPU implementations. The non-GPU image for data preparation and orchestration is much lighter:
```
non_gpu_image = flyte.Image.from_debian_base(
name="qwen_vl_multinode_deepspeed_non_gpu"
).with_pip_packages(
"flyteplugins-pytorch>=2.0.11",
"flyteplugins-jsonl>=2.0.11",
"flyteplugins-wandb>=2.0.11",
"lightning==2.6.1",
"datasets==4.4.1",
"pillow==11.3.0",
"torchvision==0.24.1",
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/config.py*
With images defined, each task gets its own resource declaration:
```
dataset_env = flyte.TaskEnvironment(
name="qwen_vl_dataset_prep",
image=non_gpu_image,
resources=flyte.Resources(cpu=5, memory="15Gi"),
cache="auto",
)
training_env = flyte.TaskEnvironment(
name="qwen_vl_multinode_training",
image=gpu_image,
resources=flyte.Resources(
cpu=42,
memory="256Gi",
gpu=f"L40s:{DEVICES_PER_NODE}",
shm="16Gi",
),
plugin_config=Elastic(nnodes=NUM_NODES, nproc_per_node=DEVICES_PER_NODE),
secrets=[
flyte.Secret(key="wandb_api_key", as_env_var="WANDB_API_KEY")
], # TODO: update with your own secret key
env_vars={
"TORCH_DISTRIBUTED_DEBUG": "INFO",
"NCCL_DEBUG": "WARN",
"TOKENIZERS_PARALLELISM": "false",
"CUDA_HOME": "/usr/local/cuda",
"DS_SKIP_CUDA_CHECK": "1",
},
)
evaluation_env = flyte.TaskEnvironment(
name="qwen_vl_adapter_eval",
image=gpu_image,
resources=flyte.Resources(cpu=16, memory="64Gi", gpu="L40s:1"),
cache="auto",
)
driver_env = flyte.TaskEnvironment(
name="qwen_vl_multinode_driver",
image=non_gpu_image,
resources=flyte.Resources(cpu=2, memory="4Gi"),
depends_on=[dataset_env, training_env, evaluation_env],
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/config.py*
A few things worth noting here:
- **`Elastic(nnodes=2, nproc_per_node=4)`**: Flyte's integration with PyTorch's elastic launch. It handles process spawning (one process per GPU), rank assignment, and distributed environment setup — master address, world size, rendezvous — without any shell scripting or manual `torchrun` invocations.
- **`shm="16Gi"`**: Shared memory is required for NCCL inter-GPU communication on the same node. Without it, you'll see cryptic errors from the communication library when training starts.
- **`cache="auto"`**: The dataset preparation task is cached by input hash. Running the pipeline twice with the same hyperparameters skips it entirely on the second run.
- **`depends_on`**: The driver task declares that each worker image must finish building before it starts, ensuring containers are ready before the driver begins orchestrating.
- **`secrets`**: The WandB API key is injected from Flyte's secret store as an environment variable. No credentials in code.
All training hyperparameters flow through a single typed dataclass:
```
@dataclass
class Config:
model_name: str = DEFAULT_MODEL_NAME
image_size: int = IMAGE_SIZE
max_train_samples: int = 1024
max_val_samples: int = 256
epochs: int = 8
per_device_batch_size: int = 1
target_global_batch_size: int = 16
learning_rate: float = 2e-4
weight_decay: float = 1e-2
reconstruction_loss_weight: float = 0.35
report_every_n_steps: int = 10
num_workers: int = 4
max_length: int = 512
eval_examples: int = 16
train_occlusion_min: float = 0.22
train_occlusion_max: float = 0.42
eval_occlusion_min: float = 0.28
eval_occlusion_max: float = 0.45
seed: int = 7
def to_dict(self) -> dict:
return asdict(self)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/config.py*
Using a dataclass rather than scattered constants or argparse arguments means the full config is serializable, can be stored in artifact metadata alongside the model checkpoint, and flows cleanly as a typed input between tasks. The `to_dict()` method serializes it for WandB logging.
### Preparing the dataset
The dataset task handles everything: downloading CIFAR-10, generating occlusions, and writing the manifests.
```
@dataset_env.task
async def prepare_occlusion_dataset(config: Config) -> DatasetArtifacts:
from PIL import Image
from torchvision.datasets import CIFAR10
from flyte.io import Dir
from flyteplugins.jsonl import JsonlFile
import random
rng = random.Random(config.seed)
images_dir = Path("/tmp/qwen_vl_occlusion_images")
train_images_dir = images_dir / "train" / "images"
val_images_dir = images_dir / "validation" / "images"
train_images_dir.mkdir(parents=True, exist_ok=True)
val_images_dir.mkdir(parents=True, exist_ok=True)
prompt = (
"The image may be partially occluded. "
"Answer with exactly one CIFAR-10 class label: "
+ ", ".join(CLASS_NAMES)
+ ". What is the main object?"
)
async def export_split(
dataset,
split_name: str,
limit: int,
local_image_dir: Path,
occ_min: float,
occ_max: float,
):
out = JsonlFile.new_remote(f"{split_name}_manifest.jsonl")
async with out.writer() as writer:
for idx in range(limit):
pil_image, label_idx = dataset[idx]
resized = pil_image.resize(
(config.image_size, config.image_size),
resample=Image.Resampling.BICUBIC,
)
rel_path = f"{split_name}/images/{split_name}-{idx:05d}.png"
resized.save(local_image_dir / f"{split_name}-{idx:05d}.png")
occlusion = build_occlusion_box(
width=config.image_size,
height=config.image_size,
rng=rng,
min_fraction=occ_min,
max_fraction=occ_max,
)
await writer.write(
{
"image_path": rel_path,
"label": CLASS_NAMES[label_idx],
"label_index": int(label_idx),
"prompt": prompt,
"occlusion": occlusion,
}
)
return out
train_dataset = CIFAR10(root="/tmp/cifar10", train=True, download=True)
val_dataset = CIFAR10(root="/tmp/cifar10", train=False, download=True)
train_manifest = await export_split(
train_dataset,
"train",
config.max_train_samples,
train_images_dir,
config.train_occlusion_min,
config.train_occlusion_max,
)
val_manifest = await export_split(
val_dataset,
"validation",
config.max_val_samples,
val_images_dir,
config.eval_occlusion_min,
config.eval_occlusion_max,
)
return DatasetArtifacts(
train_manifest=train_manifest,
val_manifest=val_manifest,
images=await Dir.from_local(str(images_dir)),
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/data.py*
Each image gets a randomly-placed black rectangle. The occlusion covers 22–42% of the image area during training and 28–45% during evaluation. The occlusion is deliberately harder at eval time to test how robust the adapter is. The bounding box coordinates are written into each manifest record alongside the image path and ground-truth label, so the training task can reconstruct the binary occlusion mask as the adapter's fourth input channel.
Two Flyte primitives handle data persistence without any manual storage management:
- **`JsonlFile.new_remote()`** opens a streaming writer that writes directly to remote object storage. The training task reads records back via `jf.iter_records_sync()`, so no local file paths and S3 credentials to manage.
- **`Dir.from_local()`** uploads the local images directory to object storage and returns a typed handle. The training task downloads it to a local path via `Dir.download_sync()`.
Because `cache="auto"` is set on this task, dataset preparation runs once. Subsequent reruns with the same config skip it entirely.
### The adapter
Here's the entire trainable component of the model with `~10,500` parameters:
```
class ResidualOcclusionAdapter(nn.Module):
def __init__(self, hidden_channels: int = 32):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(4, hidden_channels, kernel_size=3, padding=1),
nn.GELU(),
nn.Conv2d(hidden_channels, hidden_channels, kernel_size=3, padding=1),
nn.GELU(),
nn.Conv2d(hidden_channels, 3, kernel_size=1),
nn.Tanh(),
)
self.gate = nn.Parameter(torch.tensor(0.10))
def forward(
self, pixel_values: torch.Tensor, occlusion_mask: torch.Tensor
) -> torch.Tensor:
if pixel_values.ndim != 4:
raise ValueError(
"ResidualOcclusionAdapter expects dense image tensors with shape "
f"(B, C, H, W), but received {tuple(pixel_values.shape)}."
)
if occlusion_mask.ndim == 3:
occlusion_mask = occlusion_mask.unsqueeze(1)
adapter_input = torch.cat(
[pixel_values, occlusion_mask.to(pixel_values.dtype)],
dim=1,
)
residual = self.net(adapter_input)
return pixel_values + torch.tanh(self.gate) * residual
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/model.py*
The adapter takes the occluded image (3 channels) concatenated with the binary occlusion mask (1 channel) as a 4-channel input. It predicts a residual correction through a small convolutional network, then adds that correction back to the original pixels. The learnable `gate` scalar, initialized to `0.10`, controls how strongly the adapter modifies the image. It starts as a near-identity transformation and gradually grows during training as the adapter gains confidence.
The adapter is plugged into Qwen2.5-VL via a Lightning module:
```
class QwenVLAdapterModule(L.LightningModule):
def __init__(
self,
model_name: str,
learning_rate: float,
weight_decay: float,
reconstruction_loss_weight: float,
):
super().__init__()
from transformers import Qwen2_5_VLForConditionalGeneration
self.save_hyperparameters()
self.adapter = ResidualOcclusionAdapter()
self.backbone = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
attn_implementation="sdpa",
)
self.backbone.requires_grad_(False)
self.backbone.gradient_checkpointing_enable()
# DeepSpeed checkpoints only persist the trainable adapter weights when
# `exclude_frozen_parameters=True`. On resume we rebuild the frozen
# backbone from Hugging Face and load the checkpoint non-strictly.
self.strict_loading = False
self.total_params, self.trainable_params = count_parameters(self)
self.example_input_array = None
self.vision_patch_size = int(self.backbone.config.vision_config.patch_size)
self.temporal_patch_size = int(
getattr(self.backbone.config.vision_config, "temporal_patch_size", 1)
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/model.py*
The key line is `self.backbone.requires_grad_(False)`. This freezes all 3 billion backbone parameters which means only the adapter's ~10,500 weights receive gradients. `gradient_checkpointing_enable()` trades compute for memory: instead of keeping the frozen backbone's intermediate activations in GPU memory during the backward pass, they're recomputed on the fly. This is critical when a 3B model is sitting in GPU memory alongside your optimizer state.
`strict_loading = False` handles an important DeepSpeed checkpoint detail. When `exclude_frozen_parameters=True` is set on the strategy, DeepSpeed only saves the adapter weights in checkpoints, not the 3B frozen backbone. On resume, the checkpoint won't contain backbone weights, so loading must be non-strict. The `on_load_checkpoint` hook fills in the missing backbone weights from the freshly-loaded HuggingFace model, combining the best of both worlds: small checkpoints and a fully initialized model.
The training loss combines two objectives:
```
def _forward_losses(
self, batch: dict[str, torch.Tensor]
) -> dict[str, torch.Tensor]:
backbone_dtype = next(self.backbone.parameters()).dtype
if batch["pixel_values"].ndim == 2:
if "image_grid_thw" not in batch:
raise ValueError(
"Packed Qwen pixel values require `image_grid_thw` to reconstruct "
"dense images for the Conv2d adapter."
)
grid_thw = batch["image_grid_thw"]
dense_pixels = packed_pixels_to_dense_images(
batch["pixel_values"].to(dtype=backbone_dtype),
grid_thw,
patch_size=self.vision_patch_size,
temporal_patch_size=self.temporal_patch_size,
)
clean_pixels = packed_pixels_to_dense_images(
batch["clean_pixel_values"].to(dtype=backbone_dtype),
grid_thw,
patch_size=self.vision_patch_size,
temporal_patch_size=self.temporal_patch_size,
)
adapted_dense = self.adapter(dense_pixels, batch["occlusion_mask"])
adapted_pixels = dense_images_to_packed_pixels(
adapted_dense,
grid_thw,
patch_size=self.vision_patch_size,
temporal_patch_size=self.temporal_patch_size,
)
else:
clean_pixels = batch["clean_pixel_values"].to(dtype=backbone_dtype)
adapted_dense = self.adapter(
batch["pixel_values"].to(dtype=backbone_dtype),
batch["occlusion_mask"],
)
adapted_pixels = adapted_dense
forward_kwargs = {
"input_ids": batch["input_ids"],
"attention_mask": batch["attention_mask"],
"pixel_values": adapted_pixels,
"labels": batch["labels"],
}
if "image_grid_thw" in batch:
forward_kwargs["image_grid_thw"] = batch["image_grid_thw"]
outputs = self.backbone(**forward_kwargs)
clean_pixels = clean_pixels.to(
device=adapted_pixels.device, dtype=backbone_dtype
)
occlusion_mask = batch["occlusion_mask"].to(
device=adapted_pixels.device,
dtype=backbone_dtype,
)
if occlusion_mask.ndim == 3:
occlusion_mask = occlusion_mask.unsqueeze(1)
if occlusion_mask.shape[-2:] != adapted_dense.shape[-2:]:
occlusion_mask = F.interpolate(
occlusion_mask,
size=adapted_dense.shape[-2:],
mode="nearest",
)
reconstruction_error = (adapted_dense - clean_pixels).abs() * occlusion_mask
mask_denominator = (occlusion_mask.sum() * adapted_dense.shape[1]).clamp_min(
1.0
)
reconstruction_loss = reconstruction_error.sum() / mask_denominator
total_loss = (
outputs.loss + self.hparams.reconstruction_loss_weight * reconstruction_loss
)
return {
"total_loss": total_loss,
"lm_loss": outputs.loss,
"reconstruction_loss": reconstruction_loss,
}
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/model.py*
The **language modeling loss** (cross-entropy on the predicted class label tokens) drives the model to produce correct answers. The **reconstruction loss** (mean absolute error between the adapter's output and the clean image, computed only in the occluded region) pushes the adapter to actually restore the missing pixels rather than finding a representation shortcut. Without it, the adapter could overfit the frozen backbone's quirks and produce correct tokens while generating noise in the masked region. The `reconstruction_loss_weight` (default `0.35`) balances these two objectives.
Because Qwen2.5-VL's preprocessor packs image patches into a flat `(num_patches, patch_dim)` tensor, the adapter must unpack this into a spatial `(B, C, H, W)` tensor, apply the convolutions, then repack. The `packed_pixels_to_dense_images` and `dense_images_to_packed_pixels` utilities in `model.py` handle this format conversion transparently.
### Multi-node training with DeepSpeed
The training task is a standard PyTorch Lightning training loop with distributed infrastructure handled by Flyte and DeepSpeed:
```
@wandb_init
@training_env.task(report=True)
def train_qwen_adapter_multinode(
train_manifest: JsonlFile,
val_manifest: JsonlFile,
images_dir: Dir,
config: Config,
resume_from: Optional[Dir] = None,
recovery_uri: Optional[str] = None,
) -> Optional[Dir]:
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/tasks.py*
The `@wandb_init` decorator integrates with the `wandb_config` context created in the driver task. It retrieves the initialized WandB run and attaches a `WandbLogger` to the trainer. The `report=True` flag on the task decorator enables Flyte Reports for live dashboard streaming from this task.
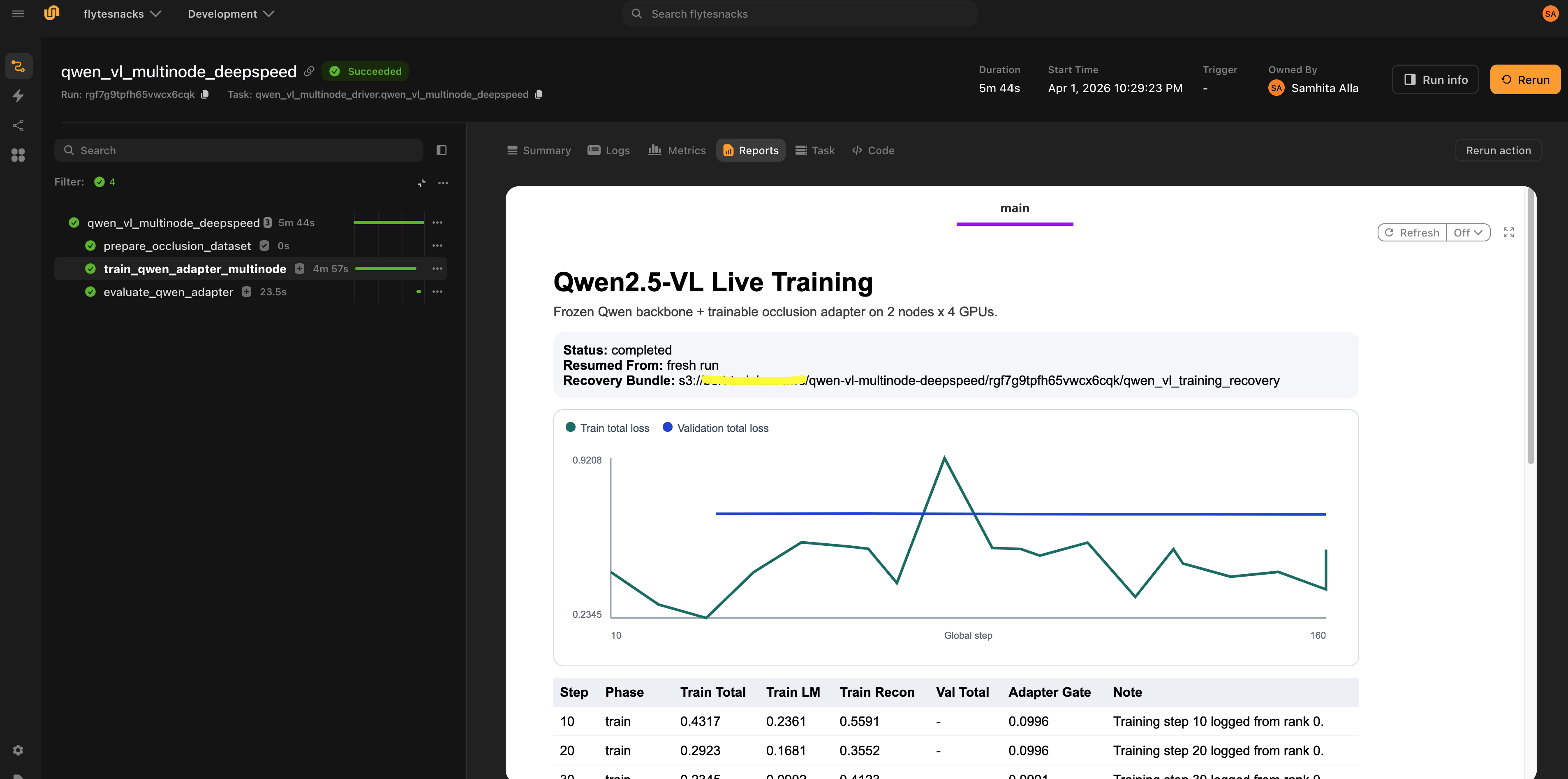
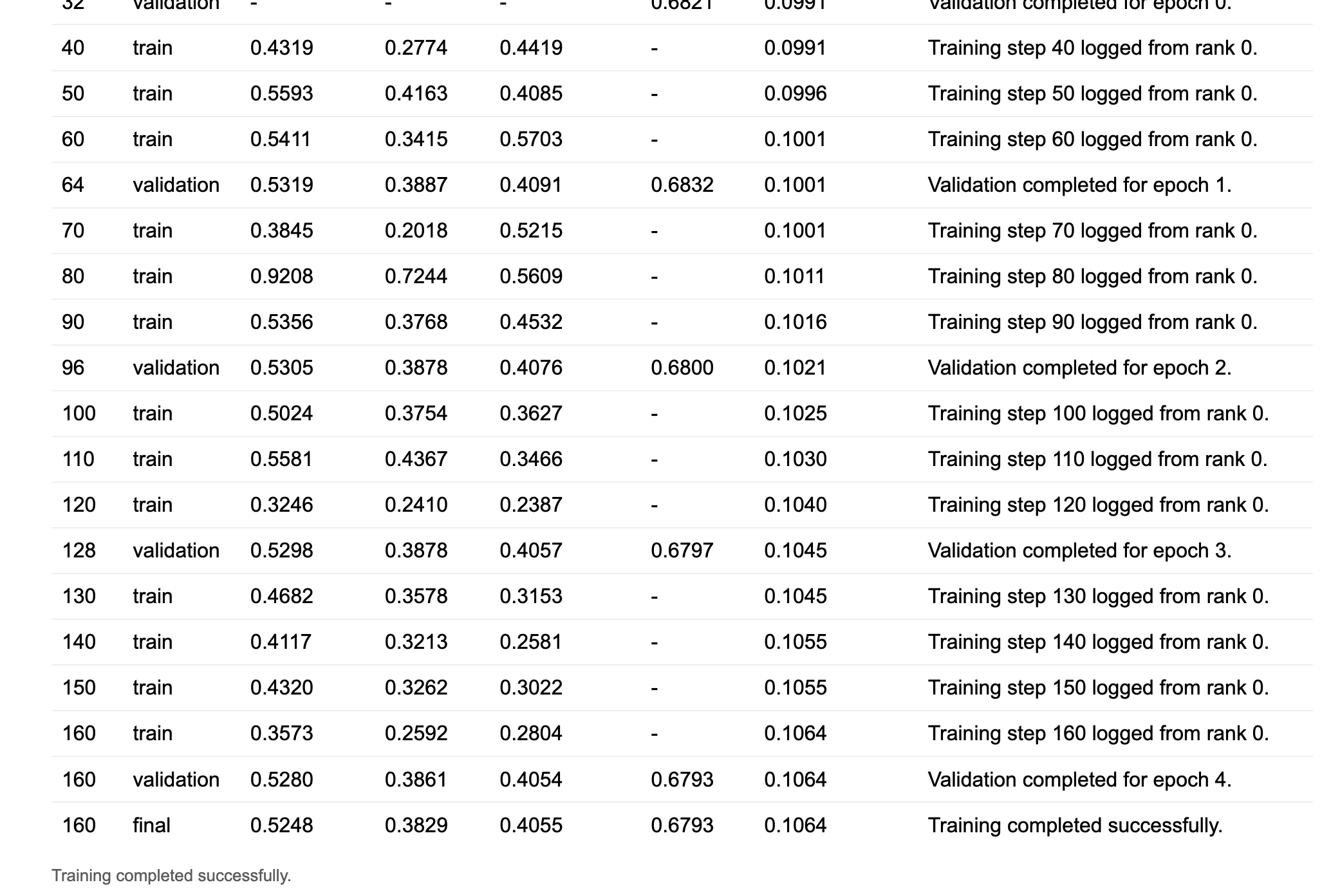
DeepSpeed Stage 2 shards optimizer states and gradients across GPUs, reducing per-GPU memory usage significantly. The critical configuration flag here is `exclude_frozen_parameters=True`:
```
strategy = DeepSpeedStrategy(
stage=2,
offload_optimizer=False,
offload_parameters=False,
process_group_backend="nccl",
exclude_frozen_parameters=True,
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/tasks.py*
Without `exclude_frozen_parameters=True`, DeepSpeed would shard and checkpoint the frozen backbone weights too, producing enormous checkpoint files, slow checkpoint saves, and unnecessary communication overhead. With it, only the adapter participates in sharding and checkpointing. The backbone is loaded independently on each worker from HuggingFace.
Gradient accumulation is computed automatically to hit the target global batch size regardless of how many GPUs are actually running:
```
world_size = NUM_NODES * DEVICES_PER_NODE
per_step_batch = world_size * config.per_device_batch_size
grad_accum_steps = max(
1,
math.ceil(config.target_global_batch_size / max(1, per_step_batch)),
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/tasks.py*
With 2 nodes × 4 GPUs × per-device batch size 1, the effective per-step batch is 8. To reach the default target of 16, the trainer accumulates over 2 steps. Change `NUM_NODES` or `per_device_batch_size` and the calculation adjusts automatically.
The trainer brings everything together:
```
trainer = L.Trainer(
accelerator="gpu",
devices=DEVICES_PER_NODE,
num_nodes=NUM_NODES,
strategy=strategy,
logger=wandb_logger,
precision="bf16-mixed",
max_epochs=config.epochs,
accumulate_grad_batches=grad_accum_steps,
callbacks=[
checkpoint_callback,
metrics_callback,
recovery_callback,
live_report_callback,
],
gradient_clip_val=1.0,
benchmark=True,
log_every_n_steps=1,
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/tasks.py*
`precision="bf16-mixed"` uses BFloat16, which matches FP32's dynamic range (unlike FP16), so you don't need loss scaling. This is the standard choice for modern VLM training. `benchmark=True` runs cuDNN autotuning on the first batch to select the fastest kernels for your specific input sizes.
### Fault tolerance and recovery
Multi-node GPU jobs fail. Hardware hiccups, spot instance preemptions, NCCL timeouts, memory spikes, etc. and the question is when, not if. This pipeline handles it with a two-part system.
After every validation epoch, the `RecoveryArtifactCallback` calls `trainer.save_checkpoint()` to write a DeepSpeed checkpoint directory, then uploads all shard files to the recovery URI. Each node's local rank 0 uploads its own shards; global rank 0 uploads the metadata files (`metrics.json`, `summary.json`). A distributed barrier between save and upload ensures all workers finish before training continues.
If training fails, the driver task catches the error and returns the last recovery artifact instead of propagating the failure:
```
try:
with wandb_config(
project=wandb_project,
entity=wandb_entity,
):
training_artifacts = train_qwen_adapter_multinode(
train_manifest=train_manifest,
val_manifest=val_manifest,
images_dir=images,
config=config,
resume_from=resume_training_artifacts,
recovery_uri=recovery_uri,
)
except flyte.errors.RuntimeUserError as e:
if recovery_uri is None:
raise e
print(f"Training failed - recovering latest checkpoint bundle: {recovery_uri}")
try:
recovered_artifacts = Dir(path=recovery_uri)
recovered_root = await download_dir_async(recovered_artifacts)
flyte.report.log(
build_qwen_adapter_report_html(recovered_root, None),
do_flush=True,
)
return recovered_artifacts
except Exception:
raise e
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/tasks.py*
A failed run still produces useful output: the best checkpoint reached before the failure, along with a partial training report. To resume from that point, pass the recovery artifact as `resume_training_artifacts` on the next run. The training task downloads it, finds the most recent `.ckpt` file, and passes it to `trainer.fit()` as `ckpt_path`. Training picks up at the last saved epoch with optimizer state and metrics history intact.
The recovery URI is constructed from the configurable base path and the run name:
```
s3://your-bucket/qwen-vl-multinode-deepspeed//qwen_vl_training_recovery/
```
This means each run gets its own recovery location, so you can identify exactly which run a checkpoint came from.
### Live observability
`flyte.report` lets you push HTML content directly into the Flyte UI during task execution, with no separate monitoring infrastructure. The `LiveTrainingReportCallback` uses this to stream training metrics in real-time:
```
def _push_update(
self,
*,
trainer,
pl_module,
status: str,
phase: str,
train_total=None,
train_lm=None,
train_recon=None,
val_total=None,
note: str,
) -> None:
adapter_gate = float(torch.tanh(pl_module.adapter.gate).detach().cpu())
def fmt(value):
return f"{float(value):.4f}" if value is not None else "-"
payload = {
"step": trainer.global_step,
"phase": phase,
"train_total": fmt(train_total),
"train_lm": fmt(train_lm),
"train_recon": fmt(train_recon),
"val_total": fmt(val_total),
"train_total_value": (
float(train_total) if train_total is not None else None
),
"val_total_value": float(val_total) if val_total is not None else None,
"adapter_gate": f"{adapter_gate:.4f}",
"status": status,
"resumed_from": self.resumed_from or "fresh run",
"recovery_path": self.recovery_callback.latest_path
or "pending first checkpoint upload",
"note": note,
}
flyte.report.log(
f"""
""",
do_flush=True,
)
```
*Source: https://github.com/unionai/unionai-examples/blob/main/v2/tutorials/qwen_vl_frozen_backbone_finetuning/callbacks.py*
`on_train_start` (see the full code) initializes the dashboard with an SVG loss chart and an HTML metrics table. Every `report_every_n_steps` training steps, `_push_update` serializes the latest metrics into a `